You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
Copy file name to clipboardexpand all lines: src/lightning/data/README.md
+50-22
Original file line number
Diff line number
Diff line change
@@ -5,23 +5,62 @@
5
5
<br/>
6
6
<br/>
7
7
8
-
## Blazing fast, distributed streaming of training data from cloud storage
8
+
## Blazingly fast, distributed streaming of training data from cloud storage
9
9
10
10
</div>
11
11
12
12
# ⚡ Welcome to Lightning Data
13
13
14
14
We developed `StreamingDataset` to optimize training of large datasets stored on the cloud while prioritizing speed, affordability, and scalability.
15
15
16
-
Specifically crafted for multi-node, distributed training with large models, it enhances accuracy, performance, and user-friendliness. Now, training efficiently is possible regardless of the data's location. Simply stream in the required data when needed.
16
+
Specifically crafted for multi-gpu & multi-node (with [DDP](https://lightning.ai/docs/pytorch/stable/accelerators/gpu_intermediate.html), [FSDP](https://lightning.ai/docs/pytorch/stable/advanced/model_parallel/fsdp.html), etc...), distributed training with large models, it enhances accuracy, performance, and user-friendliness. Now, training efficiently is possible regardless of the data's location. Simply stream in the required data when needed.
17
17
18
-
The `StreamingDataset` is compatible with any data type, including **images, text, video, and multimodal data** and it is a drop-in replacement for your PyTorch [IterableDataset](https://pytorch.org/docs/stable/data.html#torch.utils.data.IterableDataset) class. For example, it is used by [Lit-GPT](https://github.com/Lightning-AI/lit-gpt/blob/main/pretrain/tinyllama.py) to pretrain LLMs.
18
+
The `StreamingDataset` is compatible with any data type, including **images, text, video, audio, geo-spatial, and multimodal data** and it is a drop-in replacement for your PyTorch [IterableDataset](https://pytorch.org/docs/stable/data.html#torch.utils.data.IterableDataset) class. For example, it is used by [Lit-GPT](https://github.com/Lightning-AI/lit-gpt/blob/main/pretrain/tinyllama.py) to pretrain LLMs.
19
19
20
-
Finally, the `StreamingDataset` is fast! Check out our [benchmark](https://lightning.ai/lightning-ai/studios/benchmark-cloud-data-loading-libraries).
20
+
# 🚀 Benchmarks
21
21
22
-
Here is an illustration showing how the `StreamingDataset` works.
22
+
[Imagenet-1.2M](https://www.image-net.org/) is a commonly used dataset to compare computer vision models. Its training dataset contains `1,281,167 images`.
23
23
24
-
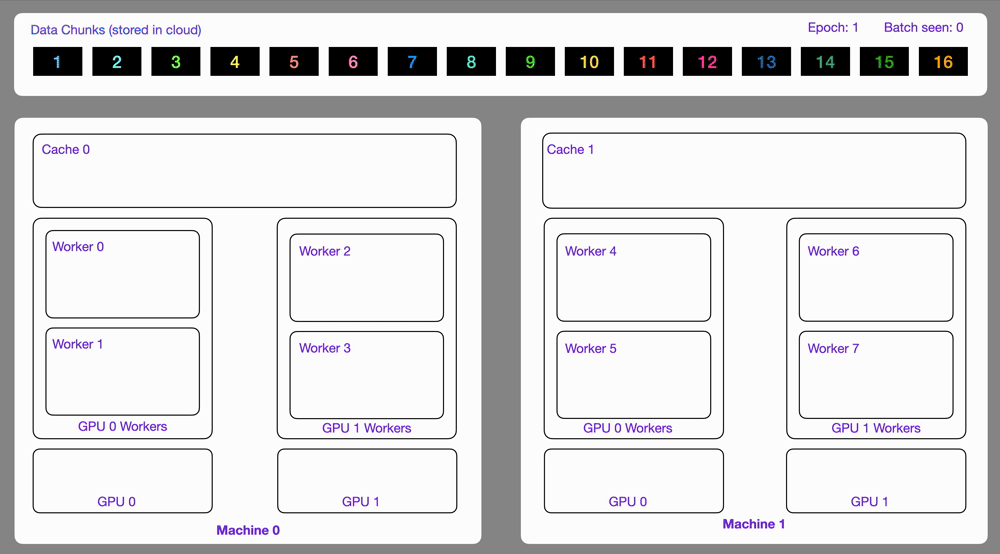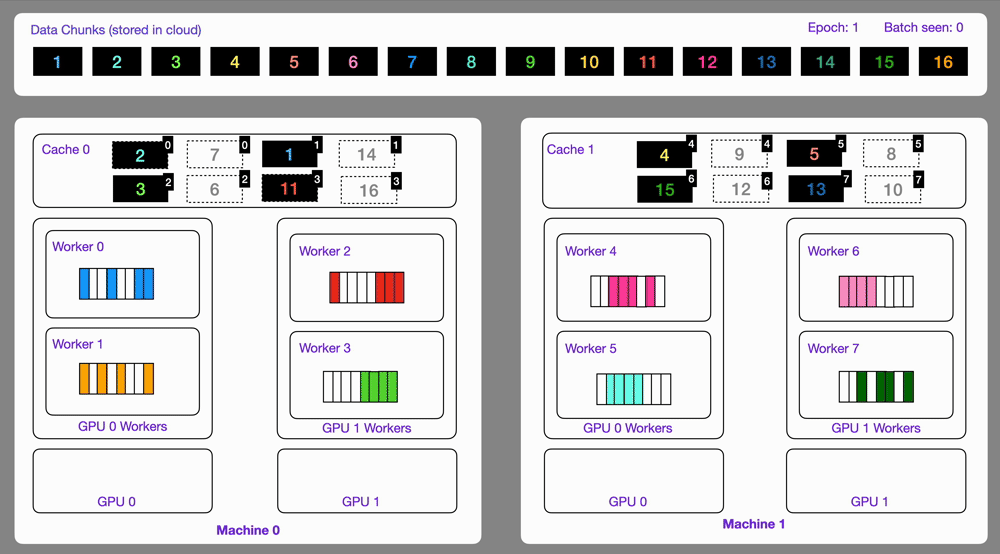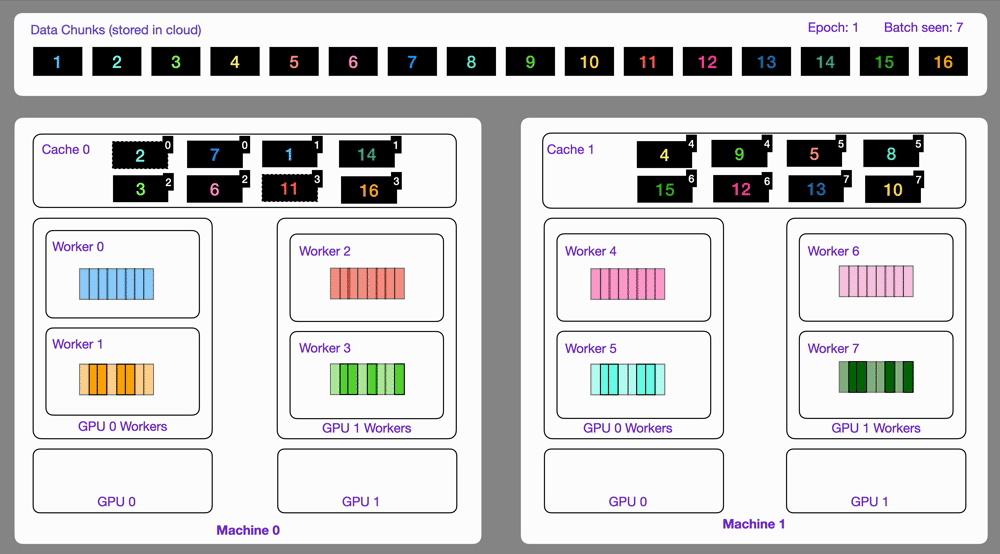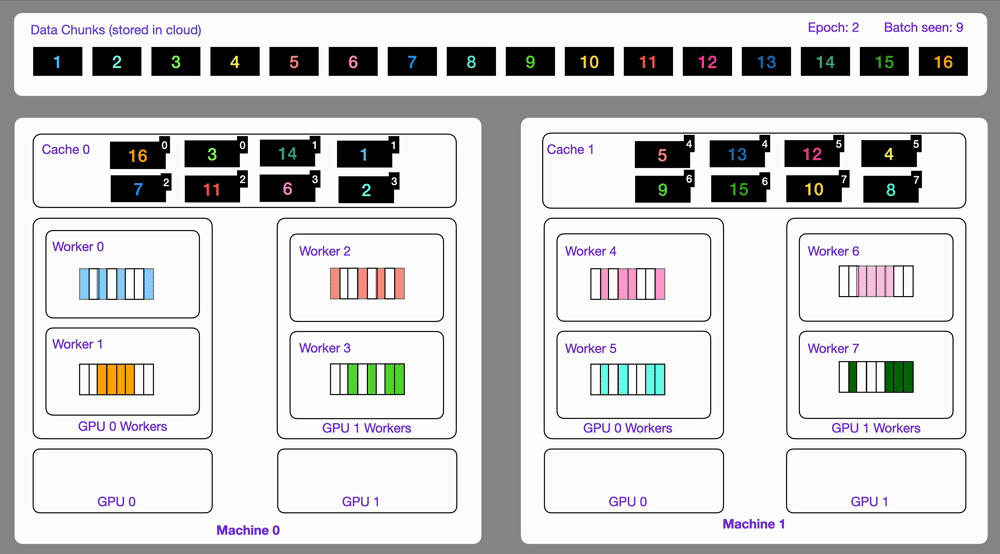
24
+
In this benchmark, we measured the streaming speed (`images per second`) loaded from [AWS S3](https://aws.amazon.com/s3/) for several frameworks.
25
+
26
+
Find the reproducible [Studio Benchmark](https://lightning.ai/lightning-ai/studios/benchmark-cloud-data-loading-libraries).
|[SlimPajama](https://huggingface.co/datasets/cerebras/SlimPajama-627B) & [StartCoder](https://huggingface.co/datasets/bigcode/starcoderdata)| Text |[Prepare the TinyLlama 1T token dataset](https://lightning.ai/lightning-ai/studios/prepare-the-tinyllama-1t-token-dataset)|
60
+
|[English Wikepedia](https://huggingface.co/datasets/wikipedia)| Text |[Embed English Wikipedia under 5 dollars](https://lightning.ai/lightning-ai/studios/embed-english-wikipedia-under-5-dollars)|
61
+
| Generated | Parquet Files |[Convert parquets to Lightning Streaming](https://lightning.ai/lightning-ai/studios/convert-parquets-to-lightning-streaming)|
62
+
63
+
[Lightning Studios](https://lightning.ai) are fully reproducible cloud IDE with data, code, dependencies, etc...
25
64
26
65
# 🎬 Getting Started
27
66
@@ -32,7 +71,7 @@ Lightning Data can be installed with `pip`:
Here is an illustration showing how the `StreamingDataset` works under the hood.
145
+
146
+

147
+
105
148
## Transform data
106
149
107
150
Similar to `optimize`, the `map` operator can be used to transform data by applying a function over a list of item and persist all the files written inside the output directory.
@@ -154,21 +197,6 @@ if __name__ == "__main__":
154
197
)
155
198
```
156
199
157
-
# 📚 End-to-end Lightning Studio Templates
158
-
159
-
We have end-to-end free [Studios](https://lightning.ai) showing all the steps to prepare the following datasets:
|[SlimPajama](https://huggingface.co/datasets/cerebras/SlimPajama-627B) & [StartCoder](https://huggingface.co/datasets/bigcode/starcoderdata)| Text |[Prepare the TinyLlama 1T token dataset](https://lightning.ai/lightning-ai/studios/prepare-the-tinyllama-1t-token-dataset)|
167
-
|[English Wikepedia](https://huggingface.co/datasets/wikipedia)| Text |[Embed English Wikipedia under 5 dollars](https://lightning.ai/lightning-ai/studios/embed-english-wikipedia-under-5-dollars)|
168
-
| Generated | Parquet Files |[Convert parquets to Lightning Streaming](https://lightning.ai/lightning-ai/studios/convert-parquets-to-lightning-streaming)|
169
-
170
-
[Lightning Studios](https://lightning.ai) are fully reproducible cloud IDE with data, code, dependencies, etc... Finally reproducible science.
171
-
172
200
# 📈 Easily scale data processing
173
201
174
202
To scale data processing, create a free account on [lightning.ai](https://lightning.ai/) platform. With the platform, the `optimize` and `map` can start multiple machines to make data processing drastically faster as follows:
0 commit comments