|
| 1 | +<div align="center"> |
| 2 | + |
| 3 | +<img alt="Lightning" src="https://pl-flash-data.s3.amazonaws.com/lightning_data_logo.png" width="800px" style="max-width: 100%;"> |
| 4 | + |
| 5 | +<br/> |
| 6 | +<br/> |
| 7 | + |
| 8 | +## Blazing fast, distributed streaming of training data from cloud storage |
| 9 | + |
| 10 | +</div> |
| 11 | + |
| 12 | +# ⚡ Welcome to Lightning Data |
| 13 | + |
| 14 | +We developed `StreamingDataset` to optimize training of large datasets stored on the cloud while prioritizing speed, affordability, and scalability. |
| 15 | + |
| 16 | +Specifically crafted for multi-node, distributed training with large models, it enhances accuracy, performance, and user-friendliness. Now, training efficiently is possible regardless of the data's location. Simply stream in the required data when needed. |
| 17 | + |
| 18 | +The `StreamingDataset` is compatible with any data type, including **images, text, video, and multimodal data** and it is a drop-in replacement for your PyTorch [IterableDataset](https://pytorch.org/docs/stable/data.html#torch.utils.data.IterableDataset) class. For example, it is used by [Lit-GPT](https://github.com/Lightning-AI/lit-gpt/blob/main/pretrain/tinyllama.py) to pretrain LLMs. |
| 19 | + |
| 20 | +Finally, the `StreamingDataset` is fast! Check out our [benchmark](https://lightning.ai/lightning-ai/studios/benchmark-cloud-data-loading-libraries). |
| 21 | + |
| 22 | +Here is an illustration showing how the `StreamingDataset` works. |
| 23 | + |
| 24 | +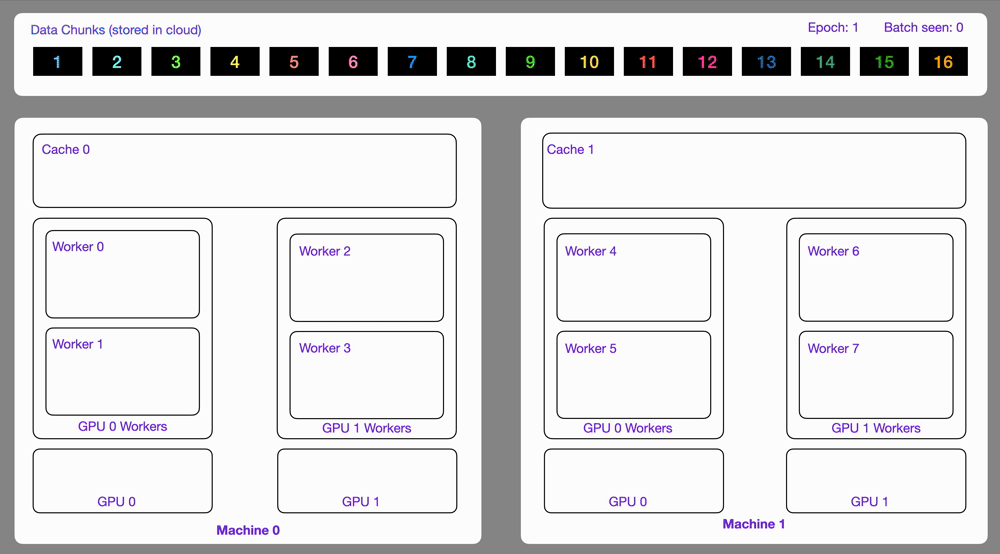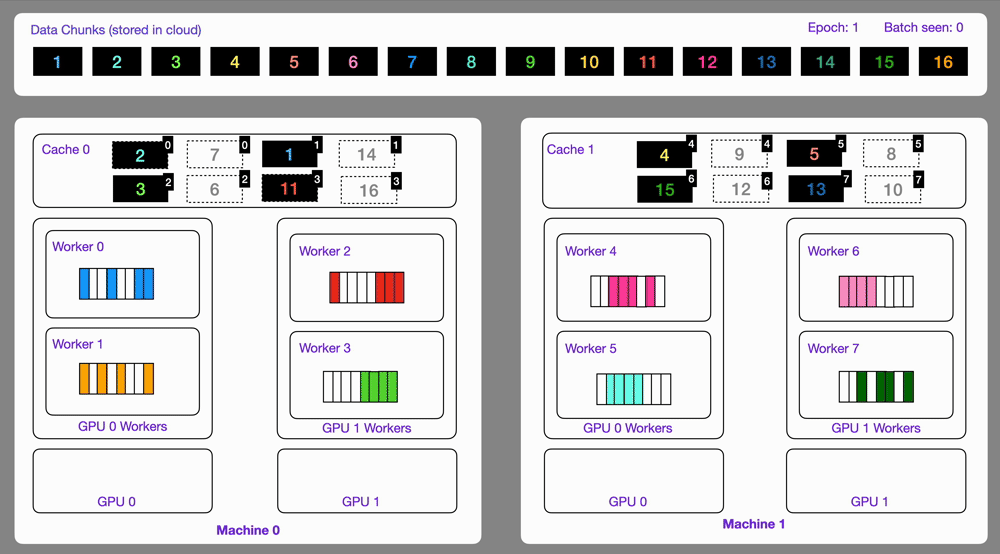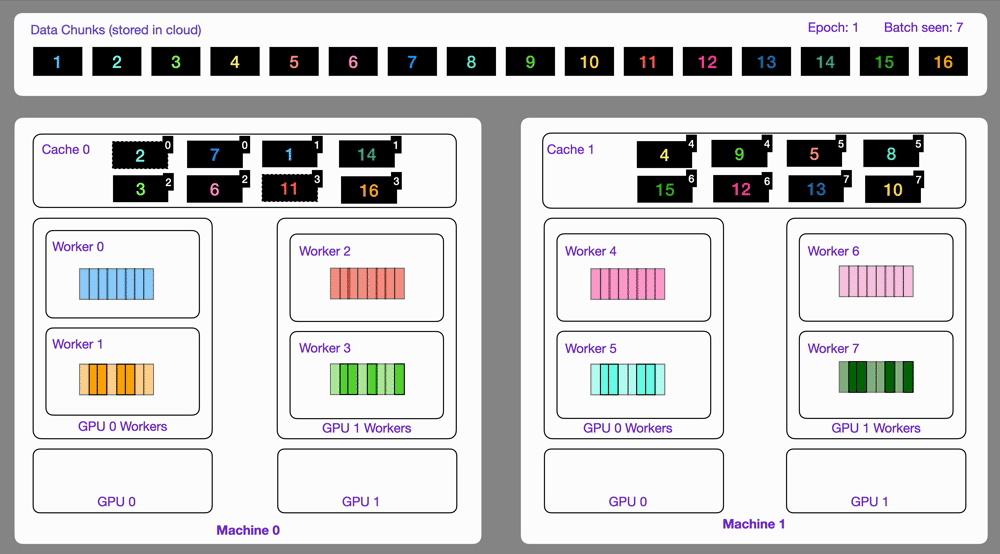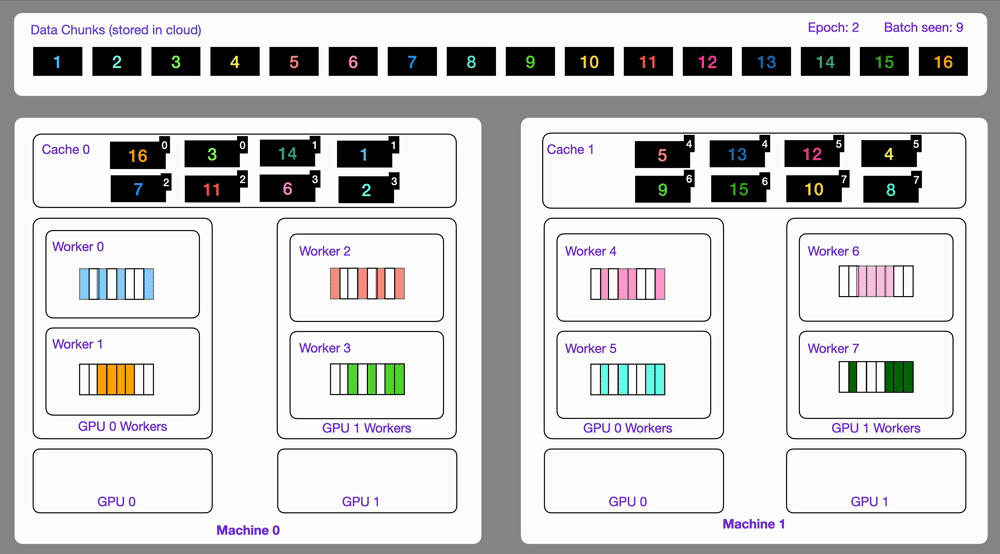 |
| 25 | + |
| 26 | +# 🎬 Getting Started |
| 27 | + |
| 28 | +## 💾 Installation |
| 29 | + |
| 30 | +Lightning Data can be installed with `pip`: |
| 31 | + |
| 32 | +<!--pytest.mark.skip--> |
| 33 | + |
| 34 | +```bash |
| 35 | +pip install --no-cache-dir git+https://github.com/Lightning-AI/pytorch-lightning.git@master |
| 36 | +``` |
| 37 | + |
| 38 | +## 🏁 Quick Start |
| 39 | + |
| 40 | +### 1. Prepare Your Data |
| 41 | + |
| 42 | +Convert your raw dataset into Lightning Streaming format using the `optimize` operator. More formats are coming... |
| 43 | + |
| 44 | +<!--pytest.mark.skip--> |
| 45 | + |
| 46 | +```python |
| 47 | +import numpy as np |
| 48 | +from lightning.data import optimize |
| 49 | +from PIL import Image |
| 50 | + |
| 51 | + |
| 52 | +# Store random images into the chunks |
| 53 | +def random_images(index): |
| 54 | + data = { |
| 55 | + "index": index, |
| 56 | + "image": Image.fromarray(np.random.randint(0, 256, (32, 32, 3), np.uint8)), |
| 57 | + "class": np.random.randint(10), |
| 58 | + } |
| 59 | + return data # The data is serialized into bytes and stored into chunks by the optimize operator. |
| 60 | + |
| 61 | +if __name__ == "__main__": |
| 62 | + optimize( |
| 63 | + fn=random_images, # The function applied over each input. |
| 64 | + inputs=list(range(1000)), # Provide any inputs. The fn is applied on each item. |
| 65 | + output_dir="my_dataset", # The directory where the optimized data are stored. |
| 66 | + num_workers=4, # The number of workers. The inputs are distributed among them. |
| 67 | + chunk_bytes="64MB" # The maximum number of bytes to write into a chunk. |
| 68 | + ) |
| 69 | + |
| 70 | +``` |
| 71 | + |
| 72 | +The `optimize` operator supports any data structures and types. Serialize whatever you want. |
| 73 | + |
| 74 | +### 2. Upload Your Data to Cloud Storage |
| 75 | + |
| 76 | +Cloud providers such as [AWS](https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html), [Google Cloud](https://cloud.google.com/storage/docs/uploading-objects?hl=en#upload-object-cli), [Azure](https://learn.microsoft.com/en-us/azure/import-export/storage-import-export-data-to-files?tabs=azure-portal-preview), etc.. provide command line client to upload your data to their storage. |
| 77 | + |
| 78 | +Here is an example with [AWS S3](https://aws.amazon.com/s3). |
| 79 | + |
| 80 | +```bash |
| 81 | +⚡ aws s3 cp --recursive my_dataset s3://my-bucket/my_dataset |
| 82 | +``` |
| 83 | + |
| 84 | +### 3. Use StreamingDataset and DataLoader |
| 85 | + |
| 86 | +```python |
| 87 | +from lightning.data import StreamingDataset |
| 88 | +from torch.utils.data import DataLoader |
| 89 | + |
| 90 | +# Remote path where full dataset is persistently stored |
| 91 | +input_dir = 's3://pl-flash-data/my_dataset' |
| 92 | + |
| 93 | +# Create streaming dataset |
| 94 | +dataset = StreamingDataset(input_dir, shuffle=True) |
| 95 | + |
| 96 | +# Check any elements |
| 97 | +sample = dataset[50] |
| 98 | +img = sample['image'] |
| 99 | +cls = sample['class'] |
| 100 | + |
| 101 | +# Create PyTorch DataLoader |
| 102 | +dataloader = DataLoader(dataset) |
| 103 | +``` |
| 104 | + |
| 105 | +## Transform data |
| 106 | + |
| 107 | +Similar to `optimize`, the `map` operator can be used to transform data by applying a function over a list of item and persist all the files written inside the output directory. |
| 108 | + |
| 109 | +### 1. Put some images on a cloud storage |
| 110 | + |
| 111 | +We generates 1000 images and upload them to AWS S3. |
| 112 | + |
| 113 | +```python |
| 114 | +import os |
| 115 | +from PIL import Image |
| 116 | +import numpy as np |
| 117 | + |
| 118 | +data_dir = "my_images" |
| 119 | +os.makedirs(data_dir, exist_ok=True) |
| 120 | + |
| 121 | +for i in range(1000): |
| 122 | + width = np.random.randint(224, 320) |
| 123 | + height = np.random.randint(224, 320) |
| 124 | + image_path = os.path.join(data_dir, f"{i}.JPEG") |
| 125 | + Image.fromarray( |
| 126 | + np.random.randint(0, 256, (width, height, 3), np.uint8) |
| 127 | + ).save(image_path, format="JPEG", quality=90) |
| 128 | +``` |
| 129 | + |
| 130 | +```bash |
| 131 | +⚡ aws s3 cp --recursive my_images s3://my-bucket/my_images |
| 132 | +``` |
| 133 | + |
| 134 | +### 2. Resize the images |
| 135 | + |
| 136 | +```python |
| 137 | +import os |
| 138 | +from lightning.data import map |
| 139 | +from PIL import Image |
| 140 | + |
| 141 | +input_dir = "s3://my-bucket/my_images" |
| 142 | +inputs = [os.path.join(input_dir, f) for f in os.listdir(input_dir)] |
| 143 | + |
| 144 | +def resize_image(image_path, output_dir): |
| 145 | + output_image_path = os.path.join(output_dir, os.path.basename(image_path)) |
| 146 | + Image.open(image_path).resize((224, 224)).save(output_image_path) |
| 147 | + |
| 148 | +if __name__ == "__main__": |
| 149 | + map( |
| 150 | + fn=resize_image, |
| 151 | + inputs=inputs, |
| 152 | + output_dir="s3://my-bucket/my_resized_images", |
| 153 | + num_workers=4, |
| 154 | + ) |
| 155 | +``` |
| 156 | + |
| 157 | +# 📚 End-to-end Lightning Studio Templates |
| 158 | + |
| 159 | +We have end-to-end free [Studios](https://lightning.ai) showing all the steps to prepare the following datasets: |
| 160 | + |
| 161 | +| Dataset | Data type | Studio | |
| 162 | +| -------------------------------------------------------------------------------------------------------------------------------------------- | :-----------------: | --------------------------------------------------------------------------------------------------------------------------------------: | |
| 163 | +| [LAION-400M](https://laion.ai/blog/laion-400-open-dataset/) | Image & description | [Use or explore LAION-400MILLION dataset](https://lightning.ai/lightning-ai/studios/use-or-explore-laion-400million-dataset) | |
| 164 | +| [Chesapeake Roads Spatial Context](https://github.com/isaaccorley/chesapeakersc) | Image & Mask | [Convert GeoSpatial data to Lightning Streaming](https://lightning.ai/lightning-ai/studios/convert-spatial-data-to-lightning-streaming) | |
| 165 | +| [Imagenet 1M](https://paperswithcode.com/sota/image-classification-on-imagenet?tag_filter=171) | Image & Label | [Benchmark cloud data-loading libraries](https://lightning.ai/lightning-ai/studios/benchmark-cloud-data-loading-libraries) | |
| 166 | +| [SlimPajama](https://huggingface.co/datasets/cerebras/SlimPajama-627B) & [StartCoder](https://huggingface.co/datasets/bigcode/starcoderdata) | Text | [Prepare the TinyLlama 1T token dataset](https://lightning.ai/lightning-ai/studios/prepare-the-tinyllama-1t-token-dataset) | |
| 167 | +| [English Wikepedia](https://huggingface.co/datasets/wikipedia) | Text | [Embed English Wikipedia under 5 dollars](https://lightning.ai/lightning-ai/studios/embed-english-wikipedia-under-5-dollars) | |
| 168 | +| Generated | Parquet Files | [Convert parquets to Lightning Streaming](https://lightning.ai/lightning-ai/studios/convert-parquets-to-lightning-streaming) | |
| 169 | + |
| 170 | +[Lightning Studios](https://lightning.ai) are fully reproducible cloud IDE with data, code, dependencies, etc... Finally reproducible science. |
| 171 | + |
| 172 | +# 📈 Easily scale data processing |
| 173 | + |
| 174 | +To scale data processing, create a free account on [lightning.ai](https://lightning.ai/) platform. With the platform, the `optimize` and `map` can start multiple machines to make data processing drastically faster as follows: |
| 175 | + |
| 176 | +```python |
| 177 | +from lightning.data import optimize, Machine |
| 178 | + |
| 179 | +optimize( |
| 180 | + ... |
| 181 | + num_nodes=32, |
| 182 | + machine=Machine.DATA_PREP, # You can select between dozens of optimized machines |
| 183 | +) |
| 184 | +``` |
| 185 | + |
| 186 | +OR |
| 187 | + |
| 188 | +```python |
| 189 | +from lightning.data import map, Machine |
| 190 | + |
| 191 | +map( |
| 192 | + ... |
| 193 | + num_nodes=32, |
| 194 | + machine=Machine.DATA_PREP, # You can select between dozens of optimized machines |
| 195 | +) |
| 196 | +``` |
| 197 | + |
| 198 | +<div align="center"> |
| 199 | + |
| 200 | +<img alt="Lightning" src="https://pl-flash-data.s3.amazonaws.com/data-prep.jpg" width="800px" style="max-width: 100%;"> |
| 201 | + |
| 202 | +<br/> |
| 203 | + |
| 204 | +The Data Prep Job UI from the [LAION 400M Studio](https://lightning.ai/lightning-ai/studios/use-or-explore-laion-400million-dataset) where we used 32 machines with 32 CPU each to download 400 million images in only 2 hours. |
| 205 | + |
| 206 | +</div> |
| 207 | + |
| 208 | +# 🔑 Key Features |
| 209 | + |
| 210 | +## 🚀 Multi-GPU / Multi-Node |
| 211 | + |
| 212 | +The `StreamingDataset` and `StreamingDataLoader` takes care of everything for you. They automatically make sure each rank receives different batch of data. There is nothing for you to do if you use them. |
| 213 | + |
| 214 | +## 🎨 Easy data mixing |
| 215 | + |
| 216 | +You can easily experiment with dataset mixtures using the CombinedStreamingDataset. |
| 217 | + |
| 218 | +```python |
| 219 | +from lightning.data import StreamingDataset, CombinedStreamingDataset |
| 220 | +from lightning.data.streaming.item_loader import TokensLoader |
| 221 | +from tqdm import tqdm |
| 222 | +import os |
| 223 | +from torch.utils.data import DataLoader |
| 224 | + |
| 225 | +train_datasets = [ |
| 226 | + StreamingDataset( |
| 227 | + input_dir="s3://tinyllama-template/slimpajama/train/", |
| 228 | + item_loader=TokensLoader(block_size=2048 + 1), # Optimized loader for tokens used by LLMs |
| 229 | + shuffle=True, |
| 230 | + drop_last=True, |
| 231 | + ), |
| 232 | + StreamingDataset( |
| 233 | + input_dir="s3://tinyllama-template/starcoder/", |
| 234 | + item_loader=TokensLoader(block_size=2048 + 1), # Optimized loader for tokens used by LLMs |
| 235 | + shuffle=True, |
| 236 | + drop_last=True, |
| 237 | + ), |
| 238 | +] |
| 239 | + |
| 240 | +# Mix SlimPajama data and Starcoder data with these proportions: |
| 241 | +weights = (0.693584, 0.306416) |
| 242 | +combined_dataset = CombinedStreamingDataset(datasets=train_datasets, seed=42, weights=weights) |
| 243 | + |
| 244 | +train_dataloader = DataLoader(combined_dataset, batch_size=8, pin_memory=True, num_workers=os.cpu_count()) |
| 245 | + |
| 246 | +# Iterate over the combined datasets |
| 247 | +for batch in tqdm(train_dataloader): |
| 248 | + pass |
| 249 | +``` |
| 250 | + |
| 251 | +## 🔘 Stateful StreamingDataLoader |
| 252 | + |
| 253 | +Lightning Data provides a stateful `StreamingDataLoader`. This simplifies resuming training over large datasets. |
| 254 | + |
| 255 | +Note: The `StreamingDataLoader` is used by [Lit-GPT](https://github.com/Lightning-AI/lit-gpt/blob/main/pretrain/tinyllama.py) to pretrain LLMs. The statefulness still works when using a mixture of datasets with the `CombinedStreamingDataset`. |
| 256 | + |
| 257 | +```python |
| 258 | +import os |
| 259 | +import torch |
| 260 | +from lightning.data import StreamingDataset, StreamingDataLoader |
| 261 | + |
| 262 | +dataset = StreamingDataset("s3://my-bucket/my-data", shuffle=True) |
| 263 | +dataloader = StreamingDataLoader(dataset, num_workers=os.cpu_count(), batch_size=64) |
| 264 | + |
| 265 | +# Restore the dataLoader state if it exists |
| 266 | +if os.path.isfile("dataloader_state.pt"): |
| 267 | + state_dict = torch.load("dataloader_state.pt") |
| 268 | + dataloader.load_state_dict(state_dict) |
| 269 | + |
| 270 | +# Iterate over the data |
| 271 | +for batch_idx, batch in enumerate(dataloader): |
| 272 | + |
| 273 | + # Store the state every 1000 batches |
| 274 | + if batch_idx % 1000 == 0: |
| 275 | + torch.save(dataloader.state_dict(), "dataloader_state.pt") |
| 276 | +``` |
| 277 | + |
| 278 | +## 🎥 Profiling |
| 279 | + |
| 280 | +The `StreamingDataLoader` supports profiling your data loading. Simply use the `profile_batches` argument as follows: |
| 281 | + |
| 282 | +```python |
| 283 | +from lightning.data import StreamingDataset, StreamingDataLoader |
| 284 | + |
| 285 | +StreamingDataLoader(..., profile_batches=5) |
| 286 | +``` |
| 287 | + |
| 288 | +This generates a Chrome trace called `result.json`. You can visualize this trace by opening Chrome browser at the `chrome://tracing` URL and load the trace inside. |
| 289 | + |
| 290 | +## 🪇 Random access |
| 291 | + |
| 292 | +Access the data you need when you need it. |
| 293 | + |
| 294 | +```python |
| 295 | +from lightning.data import StreamingDataset |
| 296 | + |
| 297 | +dataset = StreamingDataset(...) |
| 298 | + |
| 299 | +print(len(dataset)) # display the length of your data |
| 300 | + |
| 301 | +print(dataset[42]) # show the 42th element of the dataset |
| 302 | +``` |
| 303 | + |
| 304 | +## ✢ Use data transforms |
| 305 | + |
| 306 | +```python |
| 307 | +from lightning.data import StreamingDataset, StreamingDataLoader |
| 308 | +import torchvision.transforms.v2.functional as F |
| 309 | + |
| 310 | +class ImagenetStreamingDataset(StreamingDataset): |
| 311 | + |
| 312 | + def __getitem__(self, index): |
| 313 | + image = super().__getitem__(index) |
| 314 | + return T.resize(image, (224, 224)) |
| 315 | + |
| 316 | +dataset = ImagenetStreamingDataset(...) |
| 317 | +dataloader = StreamingDataLoader(dataset, batch_size=4) |
| 318 | + |
| 319 | +for batch in dataloader: |
| 320 | + print(batch.shape) |
| 321 | + # Out: (4, 3, 224, 224) |
| 322 | +``` |
| 323 | + |
| 324 | +## ⚙️ Disk usage limits |
| 325 | + |
| 326 | +Limit the size of the cache holding the chunks. |
| 327 | + |
| 328 | +```python |
| 329 | +from lightning.data import StreamingDataset |
| 330 | + |
| 331 | +dataset = StreamingDataset(..., max_cache_size="10GB") |
| 332 | +``` |
| 333 | + |
| 334 | +## 💾 Support yield |
| 335 | + |
| 336 | +When processing large files like compressed [parquet files](https://en.wikipedia.org/wiki/Apache_Parquet), you can use python yield to process and store one item at the time. |
| 337 | + |
| 338 | +```python |
| 339 | +from pathlib import Path |
| 340 | +import pyarrow.parquet as pq |
| 341 | +from lightning.data import optimize |
| 342 | +from tokenizer import Tokenizer |
| 343 | +from functools import partial |
| 344 | + |
| 345 | +# 1. Define a function to convert the text within the parquet files into tokens |
| 346 | +def tokenize_fn(filepath, tokenizer=None): |
| 347 | + parquet_file = pq.ParquetFile(filepath) |
| 348 | + # Process per batch to reduce RAM usage |
| 349 | + for batch in parquet_file.iter_batches(batch_size=8192, columns=["content"]): |
| 350 | + for text in batch.to_pandas()["content"]: |
| 351 | + yield tokenizer.encode(text, bos=False, eos=True) |
| 352 | + |
| 353 | +# 2. Generate the inputs |
| 354 | +input_dir = "/teamspace/s3_connections/tinyllama-template" |
| 355 | +inputs = [str(file) for file in Path(f"{input_dir}/starcoderdata").rglob("*.parquet")] |
| 356 | + |
| 357 | +# 3. Store the optimized data wherever you want under "/teamspace/datasets" or "/teamspace/s3_connections" |
| 358 | +outputs = optimize( |
| 359 | + fn=partial(tokenize_fn, tokenizer=Tokenizer(f"{input_dir}/checkpoints/Llama-2-7b-hf")), # Note: You can use HF tokenizer or any others |
| 360 | + inputs=inputs, |
| 361 | + output_dir="/teamspace/datasets/starcoderdata", |
| 362 | + chunk_size=(2049 * 8012), |
| 363 | +) |
| 364 | +``` |
| 365 | + |
| 366 | +# ⚡ Contributors |
| 367 | + |
| 368 | +We welcome any contributions, pull requests, or issues. If you use the Streaming Dataset for your own project, please reach out to us on Slack or Discord. |
0 commit comments