diff --git a/_materials/interpreting_communicating_humanities_data/05-web-publishing.md b/_materials/interpreting_communicating_humanities_data/05-web-publishing.md
index 5dee981..99dac5d 100644
--- a/_materials/interpreting_communicating_humanities_data/05-web-publishing.md
+++ b/_materials/interpreting_communicating_humanities_data/05-web-publishing.md
@@ -509,4 +509,113 @@ And the end result is a page with interactive Altair charts that are generated f
-Now the choice of adding this to the `article.html` file is partially because of how this theme was built, where each page is an article. So depending on the theme you're using this might look slightly differently. But the key to thing to know is that we cannot add JavaScript directly to a Markdown file, so we need to add it to the HTML file that Pelican generates. This distinction might seem confusing, but again ask for help if you get stuck and feel free to use these files as a template for your own projects.
\ No newline at end of file
+Now the choice of adding this to the `article.html` file is partially because of how this theme was built, where each page is an article. So depending on the theme you're using this might look slightly differently. But the key to thing to know is that we cannot add JavaScript directly to a Markdown file, so we need to add it to the HTML file that Pelican generates. This distinction might seem confusing, but again ask for help if you get stuck and feel free to use these files as a template for your own projects.
+
+## Publishing with Jupyter Notebooks
+
+Another way to publish your work is to use Jupyter Notebooks. We've previously used notebooks when experimenting with code and visualizations, and you can review [our notebooks lesson here]({{site.baseurl}}/materials/creating-curating-humanities-data/07-intro-notebooks/). Publishing Jupyter notebooks is a bit easier than building a static site, but it does require some additional steps to make sure your notebooks are accessible and interactive.
+
+### Google Colab
+
+One of the easiest ways to publish a Jupyter notebook is to use Google Colab. Google Colab is a free service that allows you to run Jupyter notebooks in the cloud, and it also provides a way to share your notebooks with others. You can read more about Google Colab here [https://colab.research.google.com/notebooks/intro.ipynb](https://colab.research.google.com/notebooks/intro.ipynb).
+
+To publish a notebook with Google Colab, you can create one directly in Drive, but I would recommend that you instead create a notebook locally like we've done in class and then publish that to GitHub. Once you have your notebook on GitHub, you can go to the following website [https://openincolab.com/](https://openincolab.com/) and paste the GitHub URL of your notebook. This will generate some HTML code that you can use in either your notebook or a Markdown file to create a link to open your notebook in Google Colab.
+
+
+
+
+
+
+
+So for example, with the following URL: `https://github.com/ZoeLeBlanc/is310-computing-humanities-2024/blob/gh-pages/assets/files/notebooks/IntroNotebooks.ipynb` we can generate the following HTML code:
+
+```bash
+
+
+
+```
+
+Which creates the following button:
+
+
+
+
+
+You can then embed this button either in your `README.md` file or the notebook itself on GitHub.
+
+### Binder
+
+Another way to publish your Jupyter notebooks is to use Binder [https://mybinder.org/](https://mybinder.org/). Binder is a free service that allows you to run Jupyter notebooks in the cloud, and it also provides a way to share your notebooks with others. You can read more in-depth documentation here [https://mybinder.readthedocs.io/en/latest/introduction.html](https://mybinder.readthedocs.io/en/latest/introduction.html).
+
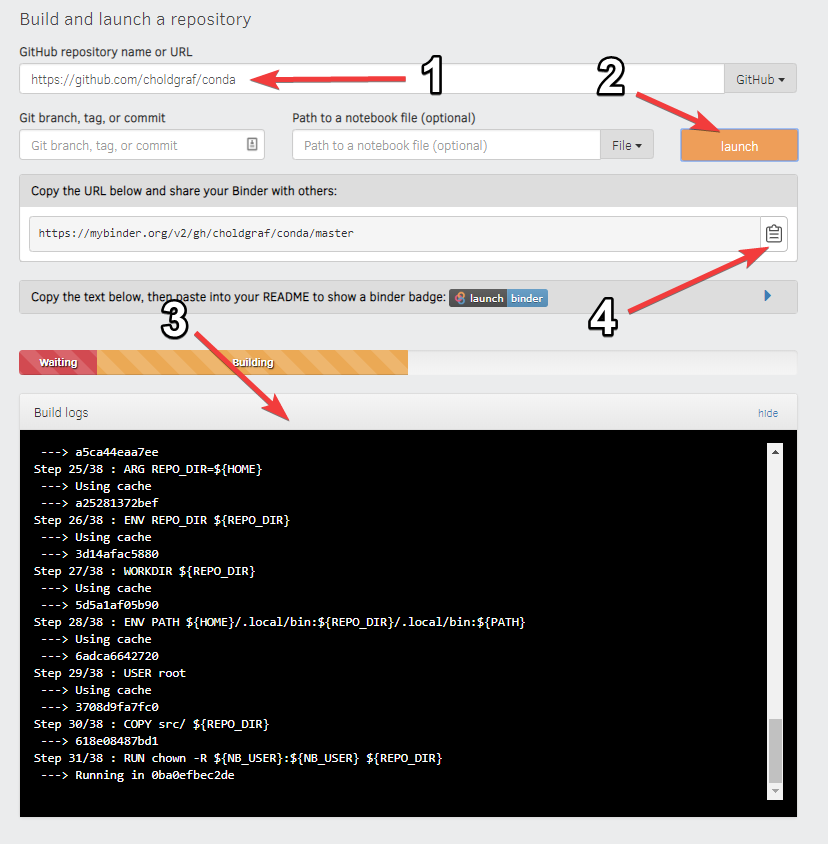
+Similar to Google Colab, Binder works with notebooks hosted in a GitHub repository. Once you have your notebook in your repository, then you can go to the Binder website and paste the URL of your repository. This will generate a link that you can share with others, and they can use it to run your notebook in the cloud.
+
+
+
+
+
+
+
+The above figure outlines how Binder works, but essentially it creates a Docker container that runs your notebook in the cloud. This is a great way to share your work with others, and it also allows you to run your notebooks on a different machine.
+
+You'll notice in the interface for Binder there is a place to enter your GitHub repository URL, and then you can click the launch button to start the container. This will take a few minutes to build, and you'll notice that the Docker container is being built in the background. Once it's finished, you'll see the Jupyter notebook interface, and you can start running your notebook.
+
+
+
+
+
+
+
+Once that is finished, you can share the link with others, and they can use it to run your notebook in the cloud. You can also create a launch binder button that you can embed in your README file or the notebook itself on GitHub. To create the button, you can use the following code:
+
+```bash
+[](https://mybinder.org/v2/gh/ZoeLeBlanc/is310-computing-humanities-2024/gh-pages)
+```
+
+This will create the following button:
+
+[](https://mybinder.org/v2/gh/ZoeLeBlanc/is310-computing-humanities-2024/gh-pages)
+
+And you can again embed this in your `README.md` file or the notebook itself on GitHub.
+
+### Remote Data & Images
+
+Now that we have remote version of our notebooks published, we have one final issue which is how to include data or images in your notebook. You can upload files to Google Drive, but it can be a bit tricky to get the file path right and often requires providing permissions.
+
+An alternative approach is to upload your files to GitHub and then use the raw URL to load the files in your notebook.
+
+For example in the notebook above, I load the data currently as the following:
+
+```python
+import pandas as pd
+df = pd.read_csv("../web_scraping/cleaned_pudding_data.csv")
+df.head()
+```
+
+This is because I've uploaded the data to the `web_scraping` folder in the repository. However, to get this working via Google Colab or Binder, I would need to upload the data to GitHub and then use the raw URL to load the data.
+
+First, you need to find your data in GitHub and then click the raw button:
+
+
+
+
+
+
+
+That should open a new page with just the data, and you can copy the URL from the address bar:
+
+
+
+
+
+
+
+Then you just update your Python code to load the data from the URL rather than the file path:
+
+```python
+import pandas as pd
+url = "https://raw.githubusercontent.com/ZoeLeBlanc/is310-computing-humanities-2024/gh-pages/assets/files/web_scraping/cleaned_pudding_data.csv"
+df = pd.read_csv(url)
+df.head()
+```
+
+Now your notebook should be able to load the data from the URL when someone runs it in Google Colab or Binder. You can do the same thing with images or other files that you want to include in your notebook.
\ No newline at end of file
diff --git a/assets/images/binder_works.png b/assets/images/binder_works.png
new file mode 100644
index 0000000..836a961
Binary files /dev/null and b/assets/images/binder_works.png differ
diff --git a/assets/images/colab.png b/assets/images/colab.png
new file mode 100644
index 0000000..0b1e25d
Binary files /dev/null and b/assets/images/colab.png differ
diff --git a/assets/images/github_data.png b/assets/images/github_data.png
new file mode 100644
index 0000000..2cc119a
Binary files /dev/null and b/assets/images/github_data.png differ
diff --git a/assets/images/github_raw_data.png b/assets/images/github_raw_data.png
new file mode 100644
index 0000000..c229544
Binary files /dev/null and b/assets/images/github_raw_data.png differ
 +
+
+
+ +
+
+
+ +
+
+
+ +
+
+
+ +
+
+
+