This project is a real-time Automatic Speech Recognition (ASR) client using WebSockets to stream audio to a server for transcription. It captures audio from a microphone, sends it to a WebSocket server, and prints the received transcriptions.
Before setting up the project, ensure you have the following installed:
- Python 3.10
- Conda (optional)
- Docker image (optional, recommended for environment management)
- NeMo (NVIDIA's conversational AI toolkit)
To avoid dependency conflicts, create a new conda environment:
conda create --name rt_asr python=3.10 -y
conda activate rt_asrNeMo is required for speech recognition processing. You can install it using the following command:
pip install nemo_toolkit[all]If you encounter issues, follow the official NeMo installation guide: NVIDIA NeMo GitHub.
Run the following command to install NeMo:
pip install git+https://github.com/NVIDIA/NeMo.git- PyAudio may require additional system dependencies; install them using:
sudo apt-get install sox libsndfile1 ffmpeg portaudio19-dev # (For Linux)
After activating the environment, install the required Python packages:
pip install -r requirements.txtOr you can use docker container for asr server.
To build and run the Docker container for this project, follow these steps:
docker build . -t ws_asrdocker run --gpus all -p 8766:8766 --rm ws_asrEnsure your WebSocket ASR server is running at ws://localhost:8766 before starting the client.
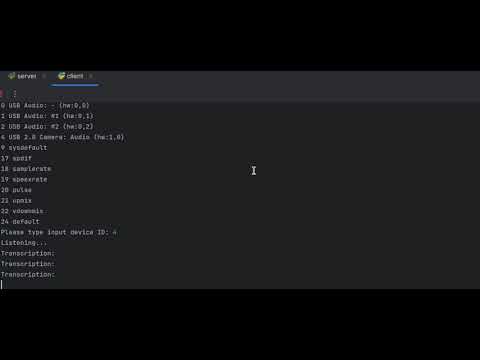
python server.pypython client.pyAfter running the client, it will list available audio input devices. Choose the appropriate device by entering its corresponding ID.
Once the connection is established, the system will capture audio and send it to the WebSocket server for transcription in real-time.
This project utilizes NeMo models trained for streaming applications, as described in the paper: Noroozi et al. "Stateful FastConformer with Cache-based Inference for Streaming Automatic Speech Recognition" (accepted to ICASSP 2024).
- Trained with limited left and right-side context to enable low-latency streaming transcription.
- Implements caching to avoid recomputation of previous activations, reducing latency further.
stt_en_fastconformer_hybrid_large_streaming_80ms- 80ms lookahead / 160ms chunk sizestt_en_fastconformer_hybrid_large_streaming_480ms- 480ms lookahead / 540ms chunk sizestt_en_fastconformer_hybrid_large_streaming_1040ms- 1040ms lookahead / 1120ms chunk sizestt_en_fastconformer_hybrid_large_streaming_multi- 0ms, 80ms, 480ms, 1040ms lookahead / 80ms, 160ms, 540ms, 1120ms chunk size
- Audio is continuously recorded in chunks and fed into the ASR model.
- Using
pyaudio, an audio input stream passes the audio to astream_callbackfunction at set intervals. - The
transcribefunction processes the audio chunk and returns transcriptions in real-time. - Chunk size determines the duration of audio processed per step.
- Lookahead size is calculated as
chunk size - 80 ms(since FastConformer models have a fixed 80ms output timestep duration).
- WebSocket Server URL: You can change the WebSocket server address in
server.pyby modifying theWS_URLvariable. - Audio Parameters: Adjust
SAMPLE_RATE,chunk_size, andENCODER_STEP_LENGTHinclient.pyto fine-tune the audio streaming behavior.
- If NeMo installation fails, refer to the NeMo Installation Guide for specific dependencies and troubleshooting steps.
- Ensure your WebSocket server is running and accessible at the correct URL.
- If no audio input devices are found, check your microphone settings and ensure that
pyaudiois correctly installed.
This project is open-source. Feel free to modify and improve it!
- The WebSocket server handling ASR is expected to be running separately.