Releases: microsoft/SynapseML
SynapseML v0.9.5

Building production ready distributed machine learning pipelines can be a challenge for even the most seasoned researcher or engineer. We are excited to announce the release of SynapseML v0.9.5 (Previously MMLSpark), an open-source library that aims to simplify the creation of massively scalable machine learning pipelines. SynapseML unifies several existing ML Frameworks and new MSFT algorithms in a single, scalable API that’s usable across Python, R, Scala, and Java.
Highlights
 |
 |
 |
 |
 |
|---|---|---|---|---|
| Geospatial Intelligence | Multivariate Anomaly Detection | Responsible AI at Scale | Text To Speech | Healthcare Analytics |
| Large-scale map and geocoding operations | Build custom time series anomaly detection systems | Distributed Conditional Expectation and Partial Dependence Analysis | East-to-use Neural Text to Speech for large datasets | Quickly understand entities and relationships in corpora of medical text. |
New Features
Geospatial Intelligence 🗺️
- Added support for distributed geospatial queries backed by the Azure Maps API
- Added the geospatial usage overview (#1339)
- Explore how to use the geospatial intelligence services to analyze flood risks. (#1339)
- Added the
AddressGeocodertransformer to map informal addresses to standardized adresses with latitude and longitude (#1294) - Added the
ReverseGeocodertransformer to map latitude and longitude measurements to standardized addresses. (#1339) - Added the
CheckPointInPolygon, to detect if latitude and longitude queries lie inside regions of interest (#1339)
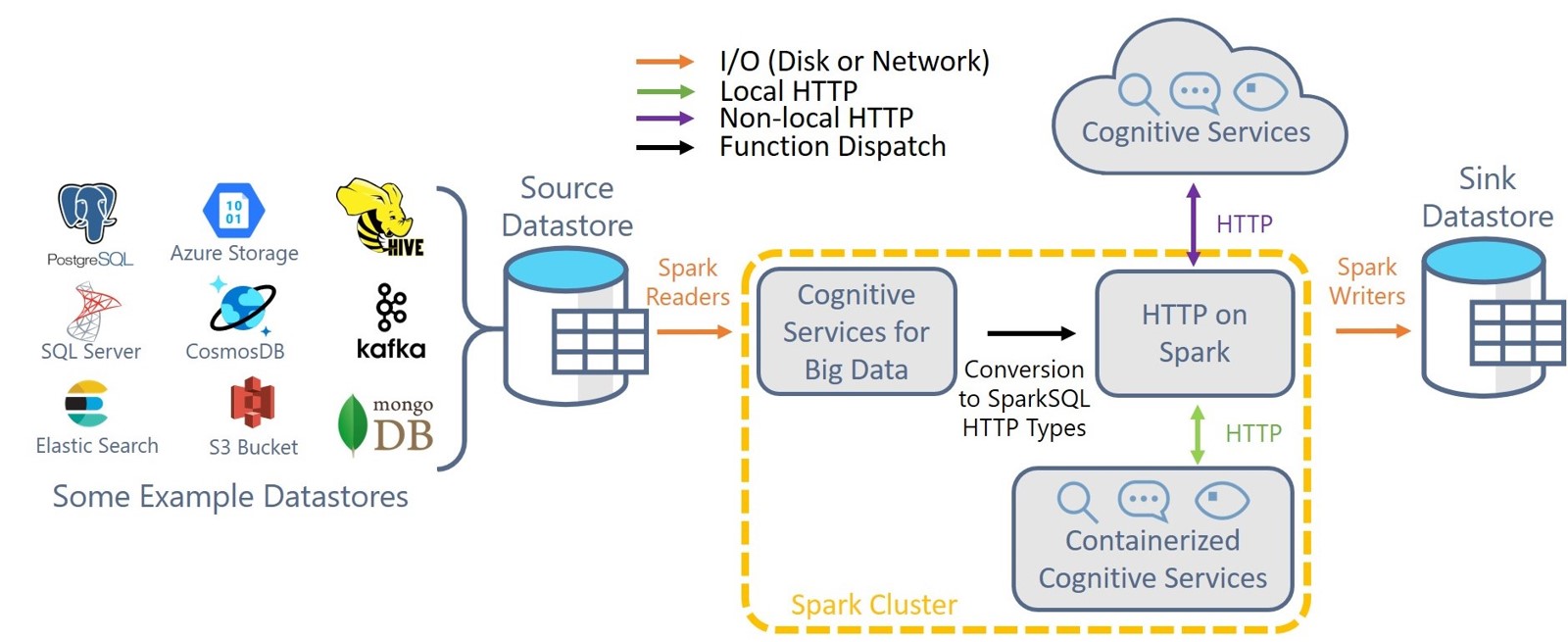
Azure Cognitive Services for Big Data 🧠
- Added the Healthcare Analytics Transformer for extracting medical information, entities, and relationships for text. [Example Usage] (#1329)
- Added the
FitMultivariateAnomalyestimator for training custom anomaly detection models on DataFrames of multivariate time series data (#1272) - Added example notebook for Multivariate Anomaly Detector
- See how to train a custom Multivariate Anomaly detector in the Estimators reference docs (#1323)
- Added simplified Text Analytics transformers that support auto-batching (#1329)
- Added the
TextToSpeechTransformer for transforming Dataframes of text to audio files with neural voice synthesis (#1320) - Added the
TextAnalyzetransformer to support executing multiple text analytics workloads within a single API call (#1267, #1312)
Responsible AI at Scale 😇
- Added Individual Conditional Expectation explanations and Partial Dependence Plots with the
ICETransformer. This tool gives detailed explanations of how features in opaque-box models affect the model prediction. (#1284) - Learn about how to use the ICETransformer through an example with the Adult Census dataset
MLFlow 🔃
LightGBM on Spark 🌳
- Improved LightGBM training performance 4x-10x by setting num_threads to be cores-1 (#1282)
- Added the predict_disable_shape_check in LightGBM (#1273)
- Reduced temporary file bloat by creating the LightGBM native temp directory lazily (#1326)
- Added logging for number of columns and rows when creating datasets, set useSingleDatasetMode=True by default (#1222)
Infrastructure 🏭
- SynapseML now installable from Maven Central!
- SynapseML now supports spark v3.2.x
Additional Updates
Bug Fixes 🐞
- Allowed FlattenBatch to propagate non-array values (#1286)
- Fixed flaky tests (#1342)
- Fixed website bugs and migrated docSearch (#1331)
- Fixed issue where IsolationForestModel does not properly exchange params with the inner model (#1330)
- Corrected the objective param when using fobj (#1292)
- Fixed issue where broadcasted sum in breeze 1.0 breaks in Spark 3.2.0 (#1299)
- Hotfixes for R test runners (#1283)
- fix installation instruction (#1268)
- Removing broadcast hint (#1255)
- fix install instructions (#1259)
Build 🏭
- bump algoliasearch-helper from 3.6.1 to 3.6.2 in /website (#1270)
- remove some deps that cause sec issues (#1264)
Documentation 📘
- Fixed broken link to CyberML notebook (#1322)
- Added website announcement bar (#1263)
- Updated and improve readme (#1262)
- Removed references to runme in contributing.md
- Supported Math expressions in website markdown (#1278)
- Corrected Synapse typo in website (#1335)
Maintenance 🔧
- Stopped lightGBM tests from timing out (#1315)
- Fixed r test flakiness (#1314)
- Updated VerifyLightGBMClassifier.scala (#1313)
- Update speech SDK test results
- Add in missing tests in build (#1300)
- Fix flaky build steps (#1298)
- Fix website telemetry (#1261)
- Add website telemetry (#1260)
- Added missing test classes to pipeline
Contributor Spotlight
We are excited to highlight the contributions of the following SynapseML contributors:
 |
.jpg) |
 |
|---|---|---|
| Serena Ruan | Ilya Matiach | Sudhindra Kovalam |
| Serena is an engineer on the Azure Synapse team in Beijing. In this release, Serena has continued her unbelievable speed of contributions with support for Multivariate Anomaly Detection, MLFlow, and installation from Maven Central. These contributions are just a few of the many projects Serena has contributed since she joined just a few months ago! | Ilya is a prolific engineer on the Azure Machine Learning Boston team working on responsible AI. Ilya contributed LightGBM on Spark and worked tirelessly to improve and support this feature. Ilya has been an active contributor to the SynapseML project for 5 years and has built many of the tools in the library. | Sudhindra is an engineer on the Microsoft Maps team and has contributed intelligent geospatial APIs to SynapseML v0.9.5. Sudhindra developed new ways to automate generation of Spa... |
Contributors
Assets 2
SynapseML v0.9.4
Building production ready distributed machine learning pipelines can be a challenge for even the most seasoned researcher or engineer. We are excited to announce the release of SynapseML (Previously MMLSpark), an open-source library that aims to simplify the creation of massively scalable machine learning pipelines. SynapseML unifies several existing ML Frameworks and new MSFT algorithms in a single, scalable API that’s usable across Python, R, Scala, and Java.
Highlights
 |
 |
|
 |
|
|---|---|---|---|---|
| General Availability on Synapse | ONNX on Spark | Responsible AI | Form Recognition and Translation | Reinforcement Learning |
| We are ready to help you productionalize on Azure Synapse Analytics | Distributed and hardware accelerated model inference on Spark | Understand opaque-box models, measure dataset biases, Explainable Boosting Machines | Parse PDFs and translate dataframes between over 100 languages | Contextual Bandit Reinforcement Learning with Vowpal Wabbit |
New Features
General ✨
- Renamed and rebranded! Microsoft ML for Apache Spark is now SynapseML
- New modular library sub-packages for standalone install of each major set of features
- Support Spark 3.1.2 and Scala 2.12
- Support
pip install synapsemlfor python bindings
ONNX on Spark 🕸
- ONNX model inference on Spark (#1152)
- Add documention and notebooks for ONNXModel evaluation (#1164)
Cognitive Services for Big Data🧠
- Added Multilingual Translation APIs (#1108) (Tutorial)
- Added FormRecognition APIs (Invoice, IDs, BusinessCards, Layouts, Custom Models) (#1099) (Tutorial)
- Added the FormOntologyLearner to extract meaningful "ontologies" of objects from collections of forms
- Add notebook to Create a Multilingual Search Engine from Forms
- Updated Text Analytics API to V3.1 (#1193)
- Add redactedText to PIIV3 (#1247)
- Added Personally Identifying Information (PII) identification
- Added Read API
- Added Conversation Transcription API
- Cognitive service now support data exfiltration protected (DEP) VNET allowing for individualized security solutions on Synapse Analytics (Learn More)
- Added support for the m4a codec in Speech to Text models
- Added predictive maintenance notebook
- Added Cognitive Service overview notebook
- Added support for linked service authentication in Synapse Analytics
- Simple no-code support in in Synapse Analytics
Responsible AI at Scale 😇
- Added Additive Shapley Explanations (SHAP) for understanding the predictions of opaque-box models (#1077)
- New API for Locally Interpretable Model-Agnostic Explanations (LIME), now supports background distributions text models, and has the same API as SHAP (#1077)
- Added Measure transformers for Data Balance Analysis (#1218)
- Add more notebook samples for documentation (#1043)
- Documentation and notebooks for Interpretability on Spark
- Introduce Responsible AI section on website (Interpretability + DataBalanceAnalysis) (#1241)
- Adding document and notebook for Data Balance Analysis (#1226)
- Explainable Boosting Machines for performant and interpretable ML (Private preview on Synapse Analytics only)
Vowpal Wabbit 🐇
- Added ContextualBandit reinforcement learning (#896)
- Added Vowpal Wabbit Overview Notebook
LightGBM 🌳
- Added matrix type parameter and improve logic to automatically infer dataset sparsity (#1052)
- Added several parameters related to dart boosting type (#1045)
- Added chunk size parameter for copying java data to native (#1041)
- Added number of threads parameter (#1055)
- Added custom objective function to LightGBM learners (#1054)
- Added singleton dataset mode for faster performance and reduced memory usage (#1066)
- Add num iteration and start iteration parameters to LightGBM model (#1024)
- Added the average precision metric (#1034)
- Added overview notebook for LightGBM
- Moved to new streaming API for dense data to reduce memory usage
- Tuned chinking code for faster performance
Build and Infrastructure Improvements 🏭
- New Docusaurus website generation system
- E2E Tests on Synapse Analytics (#1014)
- Split library into separately installable subprojects (#1073)
- Added a unified logging and telemetry system (#1019)
- Modernized R wrapper generation
- New Automated Python test generation (#998)
- New extensible code generation system
- New two-tiered security for build secrets
- Update ubuntu version to 18.04
- Automated back-up ACR images
Additional Updates
Bug Fixes 🐞
- Enable backwards compatibility for
mmlsparkpython namespace imports (#1244) - Fix publishing to maven and pypi (#1242)
- Fix broken link to notebook in Data Balance Analysis doc (#1240)
min_data_in_leafmissing from dataset parameters in lightgbm (#1239)- Fix performance issue in interpretability notebooks (#1238)
- Fixed cognitive service errors (#1176)
- Fixed flaky tests
- Rename NERPii to PII
- Fixed cog service test flakes
- Fixed setLinkedService issues in Synapse (#1177)
- Improved LGBM error message for invalid slot names (#1160)
- Fixed generated python code (#1121)
- Updated notebookUtils class path (#1118)
- Fixed LIME NaN weight output (#1117, #1112)
- Fixed Guava version issue in Azure Synapse and Databricks (#1103)
- Fixed flakiness in spark session stopping
- Fixed result parsing for forms
- Fixed explainers returning wrong results when
targetClassesColis specified - Fixed CNTKModel issue due to catalyst bug on databricks (#1076)
- Fixed null handling in bing image response (#1067)
- Avoided strange issue with databricks json parser
- Fixed dependency exclusions and build secret querying
- Fixed issue in tabular lime sampler (#1058)
- Updated Bing search URLs (#1048)
- Refactored python wrappers to use common class (#758)
- Updated java params patch (#1027)
- Added missing returns in new python lightGBM model methods
- Stop R binding generation from failing silently
- Fixed conversation transcription participant column functionality
- Reduce verbosity to...
SynapseML v0.9.2
v0.9.2
Bug Fixes 🐞
- fix publish to central maven (#1233)
- fix website (#1234)
- fix typo in sbt install
- lightgbm default params should not be specified if optional (#1232)
- fix website broken links (#1230)
- improve azure search writer error message in Array[Array[]] case
- update baseUrl and fix static images (#1217)
- Fixing flaky unit tests (#1215)
- Docker image should install openjdk-8-jre as opposed to default-… (#1211)
- Fixing flaky test
Documentation 📘
- add explanation dashboard integration example notebook (#1236)
- fix links to developer readme and R setup (#1229)
Feat
- Build our new website (#1190)
Features 🌈
- support direct pip install (#1223)
- Measure transformers for Data Balance Analysis (#1218)
- Add the FormOntologyLearner
Maintenance 🔧
- release synapseml 0.9.2 (#1237)
Performance Improvements 🚀
- website enhancement (#1221)
Acknowledgements
We would like to acknowledge the developers and contributors, both internal and external who helped create this version of SynapseML.\n
Changes:
- 81f5f80 chore: release synapseml 0.9.2 (#1237)
- 127c70a docs: add explanation dashboard integration example notebook (#1236)
- 9b9c2fb fix: fix publish to central maven (#1233)
- 7059573 fix: fix website (#1234)
- d47f014 fix: fix typo in sbt install
- 336eff5 fix: lightgbm default params should not be specified if optional (#1232)
- 3d92dd7 feat: support direct pip install (#1223)
- 2771853 docs: fix links to developer readme and R setup (#1229)
- ea91189 fix: fix website broken links (#1230)
- bbd8744 perf: website enhancement (#1221)
See More
- c5e1742 feat: Measure transformers for Data Balance Analysis (#1218)
- 73c6a65 fix: improve azure search writer error message in Array[Array[]] case
- d8344c5 feat: Add the FormOntologyLearner
- 2d81b50 fix: update baseUrl and fix static images (#1217)
- e23041f fix: Fixing flaky unit tests (#1215)
- 5d31e3e fix: Docker image should install openjdk-8-jre as opposed to default-… (#1211)
- 9623b3e Feat: Build our new website (#1190)
- 3f74133 fix: Fixing flaky test
This list of changes was auto generated.
SynapseML v0.9.1
v0.9.1
Bug Fixes 🐞
- fix readme badge
Maintenance 🔧
- Bump version to 0.9.1
Acknowledgements
We would like to acknowledge the developers and contributors, both internal and external who helped create this version of SynapseML.\n
Changes:
This list of changes was auto generated.
SynapseML v0.9.0
v0.9.0
Bug Fixes 🐞
- don't crash on fallback storage location (#1183)
Chore
- rename mmlspark to synapseml (#1204)
Features 🌈
- updata versions in README.md (#1205)
Maintenance 🔧
- release synapseml 0.9.0 (#1206)
Acknowledgements
We would like to acknowledge the developers and contributors, both internal and external who helped create this version of SynapseML.\n
Changes:
- a6c7fea chore: release synapseml 0.9.0 (#1206)
- 383cb95 Chore: rename mmlspark to synapseml (#1204)
- ecc6868 fix: don't crash on fallback storage location (#1183)
- 661e3e5 feat: updata versions in README.md (#1205)
This list of changes was auto generated.
MMLSpark v1.0.0-rc4
v1.0.0-rc4
Bug Fixes 🐞
- fix setLinkedService in Synapse
- fix cognitive service errors (#1176)
- fix anomaly detector test cases
- rename NERPii to PII
- fix scala style error
- fix cog service test flakes
- fix setLinkedService issues in Synapse (#1177)
- improve LGBM error message for invalid slot names (#1160)
- flaky lime test
- fix flaky conversation transcription test
- fix SpeechToTextSDK setLinedService (#1138)
- fix generated python code (#1121)
- update notebookUtils class path (#1118)
- LIME returns NaN weight if a feature contains a single value or when the sampler cannot obtain a different state for a feature due to data skew. It returns zero weights for all other features. (#1117)
- fix Guava version issue in Azure Synapse and Databricks (#1103)
- fix flakiness in spark session stopping
- Fix result parsing for forms
- LIME sometimes return nan weights (#1112)
- reformat code
- explainers return wrong results when targetClassesCol is specified
- Unit test OOM error (#1093)
- Update codeowners (#1092)
- BingImageSearch fails randomly in E2E test (#1082)
- [Workaround] CNTKModel does not output correct result (#1076)
- small issue with null in bing image response (#1067)
- fix flaky conversation transcription test
- avoid strange issue with databricks json parser
- fix dependency exclusions and build secret querying
- Fix issue in tabular lime sampler (#1058)
- Bing search URL update (#1048)
- early stopping test and average precision metric (#1034)
- refactor python wrappers to use common class (#758)
- java params patch (#1027)
- missing returns in new python lightgbm model methods
- fix issue with r bindings silently failing
- fix conversation transcription participant column functionality
- reduce verbosity to prevent RPC disassociated errors
- Fix performance slip in Featurize
- add timeout for stt
- update subscription in build secrets
- Add ffmpeg time limit enforcing for flaky streams (#1001)
- fix upload python whl file to blob(#1000)
- adding more recommendation code owners (#996)
- cleanup python tests (#994)
- Fix read schemas (#988)
- fix issue with NER suite test
- make concurrent timeout infinite
- Make rate limiting retry indefinitely
- Recommender Patch for Spark 3 Update (#982)
- fix typo in text sentimant schema
- change ints to longs for offset and duration in STT
- fix python tests in build
- fix processing sparse vector size
- Fix Double User agent setting bug
Build 🏭
- add two teired security for build secrets
- Fixing build warnings (#1080)
- update ubuntu version to 18.04
- fix build for new intellij
- fix livy dependency resolution
Doc
- add predictive maintenence notebook
- Add CyberML link to README.md (#989)
- Add example cyberML notebook (#958)
Documentation 📘
- Adding document and notebooks for ONNXModel (#1164)
- Documentation and notebooks for Interpretability on Spark
- Add explicit pointer to HDI install
- fix typo (#990)
- Bump python install to top to make it clearer
Features 🌈
- Update Text Analytics API to V3.1 (#1193)
- add NERPii
- Add Infrastructure to Run Tests on Synapse (#1014)
- rename Read to ReadImage (#1163)
- ONNX model inference on Spark (#1152)
- update DocumentTranslator to support setLinkedService in Synapse (#1151)
- add setLinkedService (#1136)
- add translator (#1108)
- add singleton dataset mode for faster performance and use old sparse dataset create method to reduce memory usage (#1066)
- add form recognizer support (#1099)
- split library into subprojects (#1073)
- new LIME and KernelSHAP explainers (#1077)
- refactor to have separate dataset utils and partition processor (#1089)
- refactoring of lightgbm code in preparation for single dataset mode (#1088)
- move partition consolidator and add LocalAggregator API (#1071)
- add number of threads parameter (#1055)
- add custom objective function to lightgbm learners (#1054)
- Add more notebook samples for documentation (#1043)
- add matrix type parameter and improve auto logic (#1052)
- add several parameters related to dart boosting type (#1045)
- added chunk size parameter for copying java data to native (#1041)
- Add MMLSpark logging infrastructure (#1019)
- Add R wrapper gen
- add num iteration and start iteration to lightgbm model (#1024)
- Refactor code generation system
- add automated python test generation infrastructure (#998)
- add TextLIME
- Add ReadAPI
- add conversation transcription
- add m4a codec
Maintenance 🔧
- bump version numbers (#1203)
- Fix pom for sbt dependencies (#1202)
- Add script to clean and back up ACR
- fix bug in testgen parallelism
- testing new build
- disable failing synapse e2e tests
- fix flaky serialization fuzzing test
- disable failing doc translator test
- fix flakiness in python tests (#1144)
- auto-update packages in docker
- fix flaky notebook
- remove ununsed code
- fix codecov logging of wrapper generation (#1098)
- update to lightgbm 3.2.110
- fix badge publishing
- upgrade lightgbm to 3.2.100
- update build to new subscription (#991)
- fix Detect face suite (#968)
- remove issue in scalastle file for new IJ
- lower threshold for STT tests
Performance Improvements 🚀
- tune chunking code, fix memory leak
- moving to new streaming API for dense data to reduce memory usage
Update
- reformat code
- update setLocation
- remove parens
- use HasSetLinkedService trait
- add more cognitive service
- add more cognitive service
- add more cognitive service
- add more cognitive service
- remove test code
- add test code
- remove testing code
- add sample code for test
- add sample code for test
- add sample code for test
- add sample code for test
- add sample code for test
- add sample code for test
- add reflection
- remove example in test files
- add class path
- add reflection
- notebook
- update spark version to 3.1.2 (#1086)
Acknowledgements
We would like to acknowledge the developers and contributors, both internal and external who helped create this version of MMLSpark.\n
Changes:
- 5fc65ab chore: bump version numbers (#1203)
- 993da81 chore: Fix pom for sbt dependencies (#1202)
- 327be83 feat: Update Text Analytics API to V3.1 (#1193)
- 6610577 fix: fix setLinkedService in Synapse
- e08a8e2 chore: Add script to clean and back up ACR
- d85aae8 fix: fix cognitive service errors (#1176)
- c6925db fix: fix anomaly detector test cases
- b52c361 fix: rename NERPii to PII
- 2ce1ba6...
MMLSpark v1.0.0-rc3
v1.0.0-rc3
Bug Fixes 🐞
- fix broken test link
- Fix incorrect indexing for determining eval prob in CB (#922)
- Update DBC path
Features 🌈
- Add Env variable parametrized UserAgent header
- Add support for ContextualBandit in the VW module (#896)
- Update text analytics api to v3 (#916)
Maintenance 🔧
- bump version to 1.0.0-rc3
Acknowledgements
We would like to acknowledge the developers and contributors, both internal and external who helped create this version of MMLSpark.
Contributors
Assets 2
MMLSpark v1.0.0-rc2

Highlights
 |
 |
 |
 |
 |
|---|---|---|---|---|
| Isolation Forest on Spark | CyberML | Speech To Text | Conditional KNN | LightGBM + SHAP |
| Distributed Nonlinear Outlier Detection | Machine Learning Tools for Cyber Security | Custom Speech to Text with Streaming Support | Scalable KNN Models with Conditional Queries | Interpret LightGBM Models using Additive Shapley Explanations |
New Features
Isolation Forest on Spark ⛺️
- Added LinkedIn's Isolation Forest outlier detection algorithm
- Read the original work for more info
CyberML 🧙♂️
- CyberML aims to provide open source tools for distributed cybersecurity workflows. This first release includes an algorithm that learns user-resource access patterns to detect anomalous access patterns. For more information see the docs
Cognitive Services for Big Data🧠
- Added
SpechToTextSDKtransformer. This new transformer transcribes raw audio files and live audio streams into text. Transcription supports realtime audio streaming, automatic splitting into utterances, and profanity detection. Supports several languages and Custom Speech Models. - added
TextSentimentV3transformer to leverage new Cognitive Services v3 API - add save and load methods to AccessAnomalyModel (#905)
- stream robustness, output audio stream to file, and custom speech
- Add m3u8 streaming for
SpeechToTextSDK - enable mp3 file streaming in stt sdk (#822)
Conditional K-Nearest Neighbors 🏡🏡
- Added
ConditionalKNNestimator and model for efficient search of high dimensional KNNs with conditional predicates. - Added Conditional KNN demo here
- Find hidden artistic connections with the Mosaic application.
HTTP on Spark 🌐
- Added integration with python Requests to accelerate Python Requests with HTTP on Spark!
- Optimized HTTP on Spark asynchronous performance
Vowpal Wabbit on Spark 🐇
- add barrier mode support for VW (#832)
- add support for VW readable model, invert hash and re-using a previously trained VW Spark model (#821)
- support generic numeric types for weights and labels (#817)
LightGBM on Spark 🌳
- add featuresShapCol to LightGBMClassifierModel (#863)
- Expose parameter bin_construct_sample_cnt in spark for LightGBM (#780)
- add interface function for updating learning_rate per each iteration in LightGBMDelegate (#849)
- add delegate to monitor training (#847)
- Add the option to get Feature Contributions in LightGBMBooster used by LightGBMRanker (#791)
- Add option to add tolerance to improvement in metric evolution (#786)
- added pred leaf index for LightGBMClassifier
- Adding a new param for explicitly setting slot names. (#752)
- added the top_k param for voting parallel (#762)
- Adding a feature for positive and negative bagging fraction params. (#754)
Learn More
 |
 |
 |
|---|---|---|
| MosAIc Finds Hidden Connections in World Art (Article, Demo, Webinar) | Watch the Spark Summit Europe Keynote on MMLSpark | Learn about AI for Good and MMLSpark on the MSR Podcast |
 |
 |
 |
|---|---|---|
| New Docs for the Cognitive Services for Big Data | Read our New Paper on Conditional KNN Trees | Read our New Paper on Microservices in Databases |
Bug Fixes 🐞
- Updating regular Docker Images for helm chart. (#885)
- improve error message for invalid slot names (#897)
- categorical parameter regression on dense dataset caused by missing whitespace (#909)
- fix cyberml test imports
- add "s" to failing publicwasb download
- spark.executor.cores' default value based on master when counting workers (#855)
- fix flakiness in BiLSTM notebook
- make file type case insensitive
- Add support for URI parameters and default filetypes
- remove save_resume/preserve_performance_counters options as it breaks SGD/BFGS chaining (#828)
- fix optional parsing for the CustomOutputParser (#835)
- Fix flakiness in io tests
- Improve codegen readability and added getters and setters to generated models
- move tests to a separate package and refactor common code
- added multiclass init score support (#805)
- LightGBMRanker should repartition by grouping column (#778)
- Possible multithreading issue when two scores may come in parallel they may not safely fill pointer values (#799)
- Guarantee one boosterPtr is allocated and freed per LightGBMBooster instance (#792)
- Fix subtle bug in reverse index creation
- add cap on max allowed port in network init (#759)
- added min_data_in_leaf parameter (#760)
- Reorder ADB Status Checks to fix flakiness
- increase library install timeout (#763)
- Fix an issue with the sparkContext not being instantiated at eval time
- Fix GH release bade display
- Codegen dataframe param fixes
Build 🏭
- bump version
- Ignore existing installation when running installPipPackageTask (#895)
- update ffmpeg on build server
- make python test loop easier:
- updating lightgbm to 2.3.180 (#850)
- split cog services on spark tests
- Split e2e and publishing (#836)
- Add Caching to build pipeline
- added isolation forest test to build pipeline (#800)
- exclude scala from fat jar
Code Style 🎶
- Removing redundant file in the root directory: sp.txt (#796)
- ball tree style fixes
Documentation 📘
- Adding section to readme for installing with apache livy (#785)
- Add fix for maven resolver
- Added two classification examples using Vowpal Wabbit (#733)
Maintenance 🔧
- add Roy to CODEOWNERS
- fix flaky analyze image test
- move build to new subscription (#888)
- Update ...
Contributors
Assets 2
mmlspark-v1.0.0-rc1
v1.0.0-rc1
Features 🌈
- Add brands and objects to
AnalyzeImagetransformer - Add label conversion for VW binary classifier (0/1 -> -1/1) (#700)
- Add VowpalWabbit ngram support (#696)
- Add automatic schema inference for writing to Azure Search (#704)
- Add metric parameter to lightgbm learners (#672)
Bug Fixes 🐞
- Vowpal Wabbit kwargs + improvements (#692)
- Fix cast errors for label, weight, and init score columns
- Fix probabilities and some win errors
- Fix barrier execution mode with repartition for spark standalone (#651)
- Mitigate flakiness in
SpeechToTexttest
Build 🏭
- Add ability to create fat jars (#702)
- Make Databricks tests use instance pools to remove state (#673)
Code Refactoring 💎
- Clean up distributed and continuous HTTP tests
- Clean up LightGBM tests
Documentation 📘
- Example notebook of VW vs LightGBM (#641)
- Update Cognitive Service docs (#659)
- Fix typo in Spark Serving sdocs (#656)
- Add centOS to VW on spark docs
Maintenance 🔧
- Improve code-quality
- Update lightgbm to 2.2.400
- Move build to new Azure subscription (#661)
Acknowledgements
We would like to acknowledge the developers and contributors, both internal and external who helped create this version of MMLSpark.\n
Changes:
- 8d31c02 chore: Bump Version Number to 1.0.0-rc1
- 2701aed fixed early stopping test for validation (#711)
- 6b07829 docs: Example notebook of VW vs LightGBM (#641)
- 163dead fix:fix num cores per executor if config not specified (#709)
- bc0e010 chore: ignore flaky test for now
- ea7d899 feat: Add brands and objects to analyze image transformer
- 04a2fbd feat: added label conversion for VW binary classifier (0/1 -> -1/1) (#700)
- da124d7 feat: Add VowpalWabbit ngram support (#696)
- a44dafd fix validation data and ranker preprocessing
- 4037869 feat: Add automatic schema inference for writing to Azure Search (#704)
See More
- 77bb678 update lightgbm to 2.3.100, remove generateMissingLabels, fix lightgbm getting stuck on unbalanced data
- 2e45613 build: Add ability to create fat jars (#702)
- 035fcd9 cleanup duplication in unit tests (#695)
- 932ec86 adding debug for client mode issue and future investigations
- 95061d0 fix: Vowpal Wabbit kwargs + improvements (#692)
- 3ea5bc5 fix: cast errors for label, weight and init score columns
- f2bf39f fix categorical handling on lightgbm learners
- 671b688 re-enabling windows tests for lightgbm
- 8361ead add eval_at parameter to lightgbm ranker
- c0921fb Better error message when the group column is not a Int/Long
- 05a2bef fix: update lightgbm to 2.2.400, fix probabilities and some win errors
- 16ea090 chore: imporve code-quality
- ef14350 build: databricks tests use instance pools to remove state (#673)
- 8b27d88 feat: add metric parameter to lightgbm learners (#672)
- 9805996 fix: fix barrier execution mode with repartition for spark standalone (#651)
- 1e186ad chore: move to new subscription (#661)
- 360f2f7 refactor: clean up distributed HTTP tests
- 5eedc93 fix: mitigate flakiness in speechToText test
- 0290386 refactor: clean up continuous http tests
- 8ed3aeb refactor: clean up LightGBM tests
- f99c9f4 docs: Update Cog Service docs (#659)
- df089cd docs: fix typo in spark serving docs (#656)
- b369244 docs: add vw to related software
- 876553a docs: add links to readme
- 8136022 docs: change paper badge color
- f974a6a docs: improve README
- 8190eb5 Add links to API documentation
- 241a486 docs: add centOS to vw on spark docs
This list of changes was auto generated.
v0.18.1
v0.18.1
Bug Fixes 🐞
- fix lightgbm stuck in multiclass scenario and added stratified repartition transformer (#618)
- fix schema issue with databricks e2e tests (#653)
- update VW dependency to 8.7.0.2 built on CentOS and optimized for portability (#652)
Build 🏭
- add proper secrets to publishing step (#650)
Documentation 📘
- Remove script action section
Maintenance 🔧
- bump version number
Acknowledgements
We would like to acknowledge the developers and contributors, both internal and external who helped create this version of MMLSpark.
Ilya Matiach, Markus Cozowicz
Changes:
- 62946d1 chore: bump version number
- d518b8a fix: fix lightgbm stuck in multiclass scenario and added stratified repartition transformer (#618)
- 85fb3fc fix: fix schema issue with databricks e2e tests (#653)
- 258cafb fix: update VW dependency to 8.7.0.2 built on CentOS and optimized for portability (#652)
- 376cc6a build: add proper secrets to publishing step (#650)
- 0be08e9 docs: Remove script action section
This list of changes was auto generated.