Reinforcement Learning from Human Feedback (RLHF) examples: Direct Preference Optimization (DPO) #513
Labels
enhancement
New feature or request
Comments
|
@danilopeixoto I've been thinking about having this in MLX LM recently. Any interest in sending a PR? It might make to do it after we have a more manageable config (#503) but that should be landed soon! |
|
To be more concrete, I'm envisioning you just set the loss in the config. e.g. |
|
This would be an awesome addition to mlx_examples! 🔥 |
|
I'm very very excited for this! Don't have the technical expertise to implement the DPO directly but would love to help in other ways (config, code cleanup) if neccessary! |
|
That makes MLX really useful for production not just a research tool! |
Closed
|
+500 waiting for this |
|
Wait for this, when will the DPO training be supported? |
This was referenced Nov 3, 2024
anupamme
added a commit
to anupamme/mlx-examples
that referenced
this issue
Feb 12, 2025
Fixes ml-explore#513 Implement the Direct Preference Optimization (DPO) method as a Reinforcement Learning from Human Feedback (RLHF) example. * **Add DPO Functions**: Add `get_batched_logps` and `dpo_loss` functions to `llms/mlx_lm/utils.py` for DPO implementation. * **Update Training Logic**: Update `llms/mlx_lm/tuner/trainer.py` to include DPO-specific training logic, including a new `dpo_loss` function and condition to check for DPO loss in the training loop. * **Add Configuration Options**: Add configuration options for DPO in `llms/mlx_lm/examples/lora_config.yaml`. * **Update Documentation**: Update `llms/mlx_lm/README.md` to include instructions for using DPO. * **Add Unit Tests**: Add `llms/tests/test_dpo.py` with unit tests for `get_batched_logps`, `dpo_loss`, and DPO-specific training logic. --- For more details, open the [Copilot Workspace session](https://copilot-workspace.githubnext.com/ml-explore/mlx-examples/issues/513?shareId=XXXX-XXXX-XXXX-XXXX).
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Introduce one Reinforcement Learning from Human Feedback (RLHF) example, such as Direct Preference Optimization (DPO) method.
Paper
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Notes
Direct Preference Optimization (DPO): A Simplified Explanation by João Lages
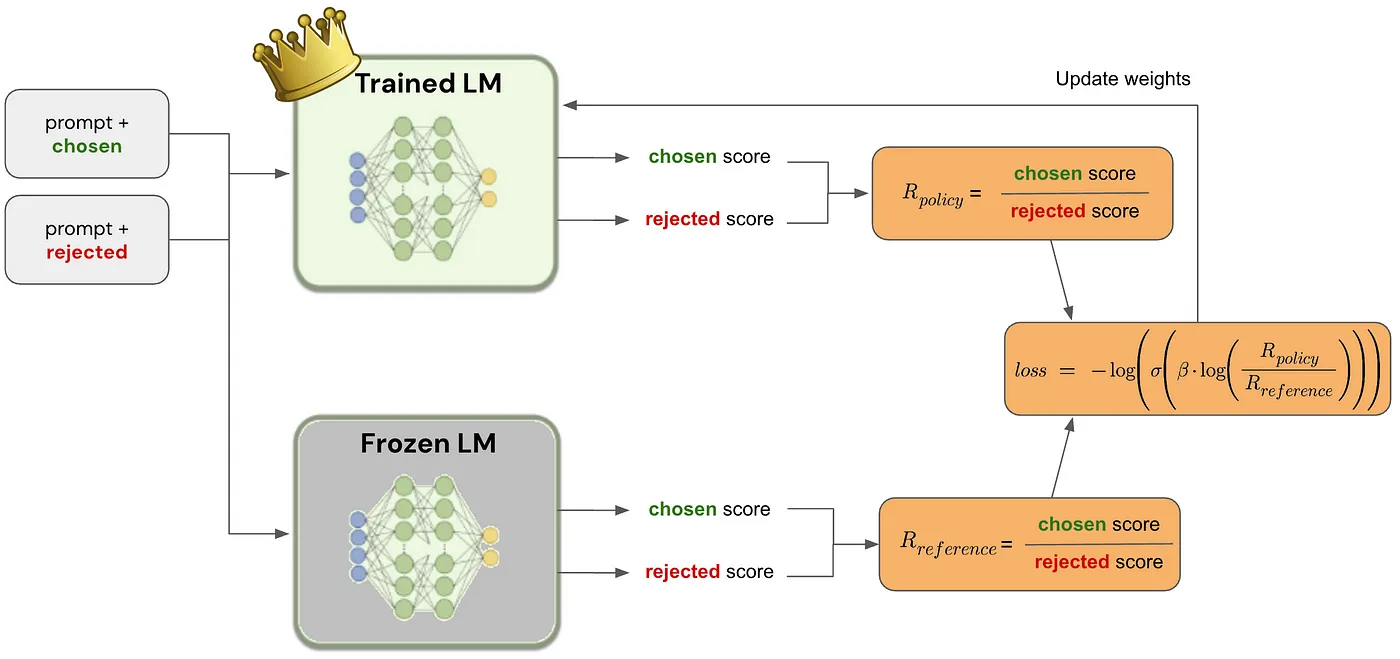
Implementation examples
Possible MLX implementation
Policy and reference log probabilities:
Loss:
Beta: The temperature parameter for the DPO loss is typically set in the range of 0.1 to 0.5. The reference model is ignored when
betaequals 0.Label smoothing: This parameter represents the conservativeness for DPO loss, assuming that preferences are noisy and can be flipped with a probability of
label_smoothing.The text was updated successfully, but these errors were encountered: