DeepInfant® is a Neural network system designed to predict whether and why your baby is crying.
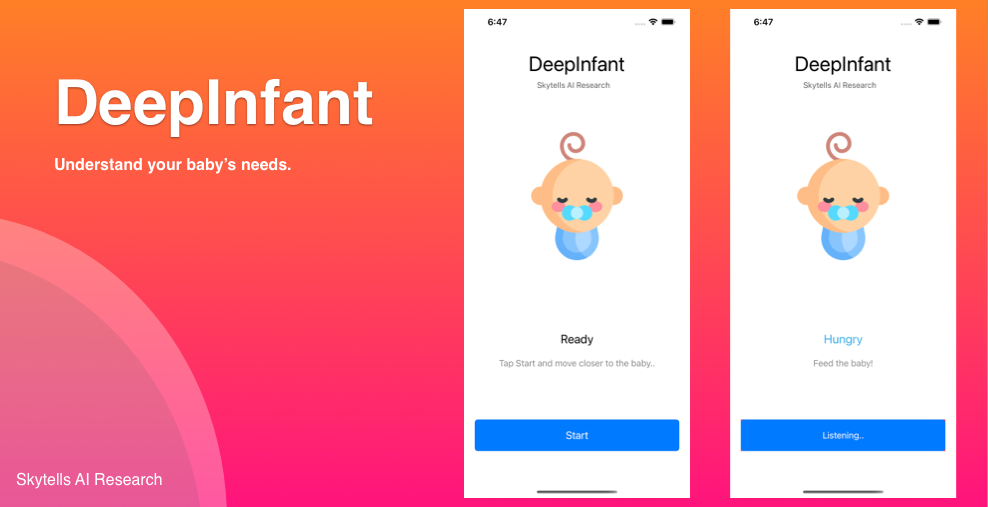
DeepInfant uses artificial intelligence and machine learning algorithms to determine which acoustic features are associated with each of a baby's needs.
For example, babies who are in pain demonstrate cries with high energy, while a fussy cry may have more periods of silence. We are preparing our findings for academic review and publication within a single well-trained model based on academic datasets.
DeepInfant is an advanced neural network system specifically engineered for infant cry classification and analysis. The system employs deep learning techniques to help caregivers accurately interpret their baby's needs in real-time. The latest version, DeepInfant V2, achieves 89% accuracy through significant architectural improvements including:
- Enhanced feature extraction using mel-spectrograms and STFT
- Hybrid CNN-LSTM architecture for better temporal modeling
- Expanded classification capabilities covering 5 distinct cry types
- Optimized model efficiency with 3x faster inference time
- Robust training on augmented datasets with over 10,000 labeled cry samples
Our research demonstrates that combining specialized audio processing with deep learning can provide reliable, real-time baby cry analysis through mobile applications, helping both parents and healthcare providers better respond to infant needs. Read our full research paper.
DeepInfant is a machine learning model that uses artificial intelligence to predict your baby's needs based on sound classification of cries.
DeepInfant was initially developed as part of a final project in the Speech Technology Course at KTH (Royal Institute of Technology, Sweden). The latest version, DeepInfant V2, has been trained using a combination of private datasets along with published datasets to improve its generalization and accuracy. The training was further enhanced based on the V1 methodologies with additional refinements to optimize performance.
Based on approaches from the babycry repository, data collection involved:
- Collection of short audio segments (~2-7 seconds).
- Labeling of audio clips using crowd-sourced and in-house volunteer annotations.
- Tagging each audio segment with:
- Presence or absence of cry,
- Potential need (e.g., hunger, discomfort, pain),
- Age and gender.
To increase the robustness and variability of the training data, DeepInfant V2 leverages augmentation techniques:
- Pitch Shifting: Modifying the pitch of the audio sample slightly to simulate different baby vocal ranges.
- Time Stretching: Speeding up or slowing down the cry without affecting pitch to capture different crying tempos.
- Adding Noise: Introducing background or white noise to simulate real-world environments (e.g., household hum, slight chatter).
These augmentations help the model generalize better and handle varying acoustic conditions.
This repo is published with pre-trained CoreML Models.
- DeepInfant_VGGish
- DeepInfant_AFP
- DeepInfant_V2
| Model | Feature Extraction | Training Data | Classification Window | Accuracy Improvement |
|---|---|---|---|---|
| DeepInfant_VGGish | Extra layers for classification | Limited dataset | Fixed 975ms | 75% |
| DeepInfant_AFP | Optimized for speed | Limited dataset | Flexible | 78% |
| DeepInfant_V2 | Advanced feature extraction | Expanded dataset with new cry classes | Flexible & optimized | 89% |
By integrating lessons from the babycry repository, DeepInfant V2 expands upon the initial pipeline:
-
Data Preprocessing
- Trimming or zero-padding audio files to uniform lengths (2–7 seconds).
- Applying data augmentation (pitch shifting, time stretching, noise addition).
-
Feature Extraction
- Short-Time Fourier Transform (STFT)
- Mel-Spectrogram
- Log-Mel-Spectrogram normalization
-
Model Architecture
- Convolutional Neural Networks (CNN) for spectral feature extraction.
- Recurrent layers (LSTM) for temporal context modeling.
- Fully connected layers for final classification.
-
Evaluation
- Use of cross-validation and hold-out validation sets.
- Metrics: Accuracy, Precision, Recall, F1-score.
Below is an illustrative table adapted from the babycry approach:
| Step | Description | Tools/Libraries |
|---|---|---|
| Data Labeling | Label audio segments as cry/non-cry and reason. | Crowdsource labeling, manual checks |
| Augmentation | Pitch shifting, time stretching, adding noise. | librosa, custom Python scripts |
| Feature Extraction | MFCC or Mel-spectrogram generation to represent audio features. | librosa, scipy, numpy |
| Classification | CNN, RNN, or hybrid architecture for final cry reason detection. | pytorch, fastai, tensorflow, CoreML |
| Evaluation | Evaluate model performance across multiple metrics and splits. | scikit-learn metrics, confusion matrix |
Below, we list the classes that the model can predict.
| Class | Description | Window Duration | Common Indicators |
|---|---|---|---|
| belly_pain | Indicates digestive discomfort or colic | 0.975s | High-pitched, intense crying with legs drawing up |
| burping | Need to release trapped air | 0.975s | Short, choppy cries with grunting sounds |
| cold_hot | Temperature-related discomfort | 0.975s | Whiny, continuous cry with temperature changes |
| discomfort | General unease (diaper, position) | 0.975s | Intermittent crying that changes with position |
| hungry | Need for feeding | 0.975s | Rhythmic, repetitive cry pattern with rooting |
| lonely | Seeking attention or comfort | 0.975s | Low-intensity cry that stops with holding |
| scared | Response to sudden changes/fear | 0.975s | Sharp, sudden crying with startle response |
| tired | Need for sleep | 0.975s | Grumbling cry with eye rubbing |
| unknown | Unclassified crying pattern | 0.975s | Variable patterns not matching other categories |
DeepInfant V2 is trained using a deep neural network with multiple stages of processing:
The audio clips have a sample rate of 16000 Hz and a duration of about ~7 secs. This means there are about 16000*7 numbers per second representing the audio data. We take a fast fourier transform (FFT) of a 2048 sample window, slide it by 512 samples, and repeat the process on the 7-sec clip. The resulting representation can be shown as a 2D image and is called a Short-Time Fourier Transform (STFT). Since humans perceive sound on a logarithmic scale, we'll convert the STFT to the mel scale. The librosa library lets us load an audio file and convert it to a melspectrogram:
import librosa
import librosa.display
fname = 'test-1-audio001.wav'
samples, sample_rate = librosa.load(fname)
fig = plt.figure(figsize=[4,4])
ax = fig.add_subplot(111)
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False)
ax.set_frame_on(False)
S = librosa.feature.melspectrogram(y=samples, sr=sample_rate)
librosa.display.specshow(librosa.power_to_db(S, ref=np.max))The melspectrogram of a baby crying looks like the image below:
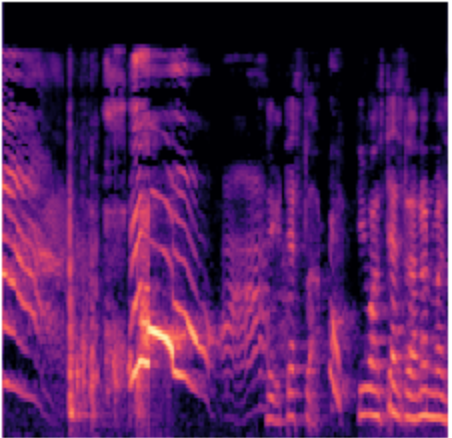
From the babycry approach, we often apply augmentations before or after extracting the Mel-Spectrogram. For instance, pitch shifting is done on the raw waveform, whereas time stretching can be applied at the waveform level or sometimes in the frequency domain.
In order to build the spectrograms of the audio samples needed for training the model, we'll be using the fantastic audio loader module for fastai v1 built by Jason Hartquist.
n_fft = 2048 # output of fft will have shape [1024 x n_frames]
n_hop = 512 # 50% overlap between frames
n_mels = 128 # compress 2048 dimensions to 128 via mel frequency scale
sample_rate = 16000
tfms = get_frequency_batch_transforms(n_fft=n_fft, n_hop=n_hop,
n_mels=n_mels, sample_rate=sample_rate)
batch_size = 64
data = (AudioItemList.from_folder(CRYING_PATH)
.split_by_folder()
.label_from_folder()
.databunch(bs=batch_size, tfms=tfms, equal_lengths=False))
learn = create_cnn(data, models.resnet34, metrics=accuracy)
learn.lr_find(start_lr=0.001, end_lr=1)
learn.recorder.plot()Fastai's cyclical learning rate finder runs the model against a small batch of training samples to find a good learning rate.
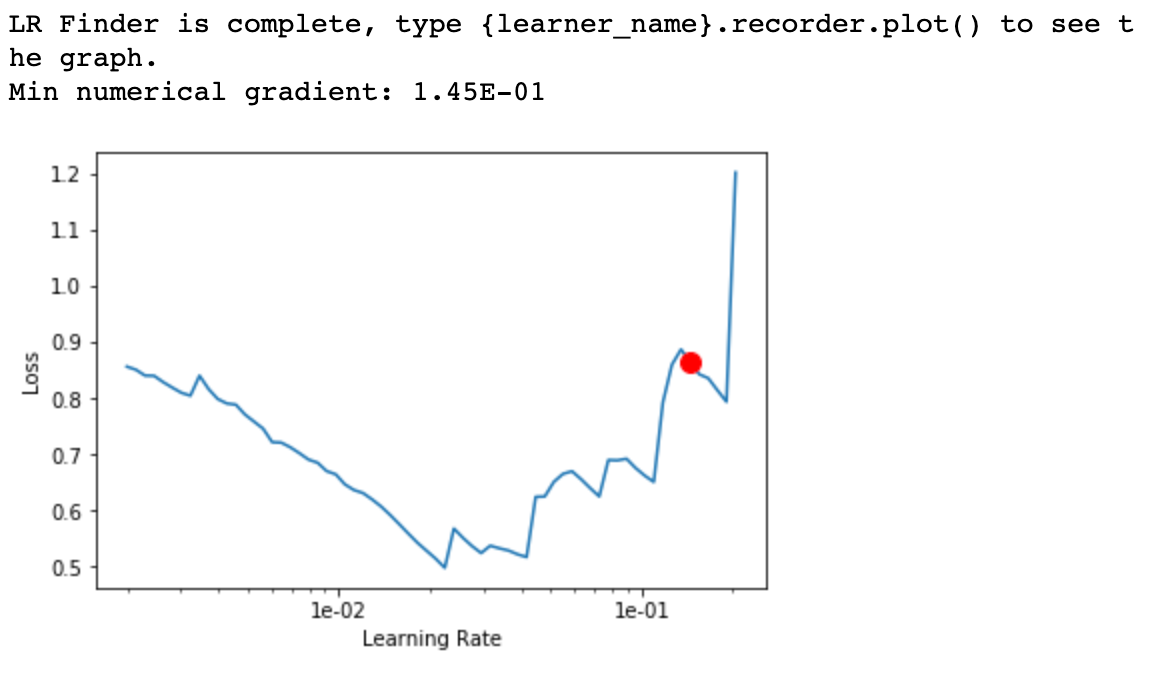
As the learning rate increases to 10e-2, you can see the model loss decrease. However, for higher learning rates, the loss begins to increase. Hence we pick 10e-2 as the learning rate for training the model.
After training the model over a few epochs, we see an accuracy of 95% over the validation set:
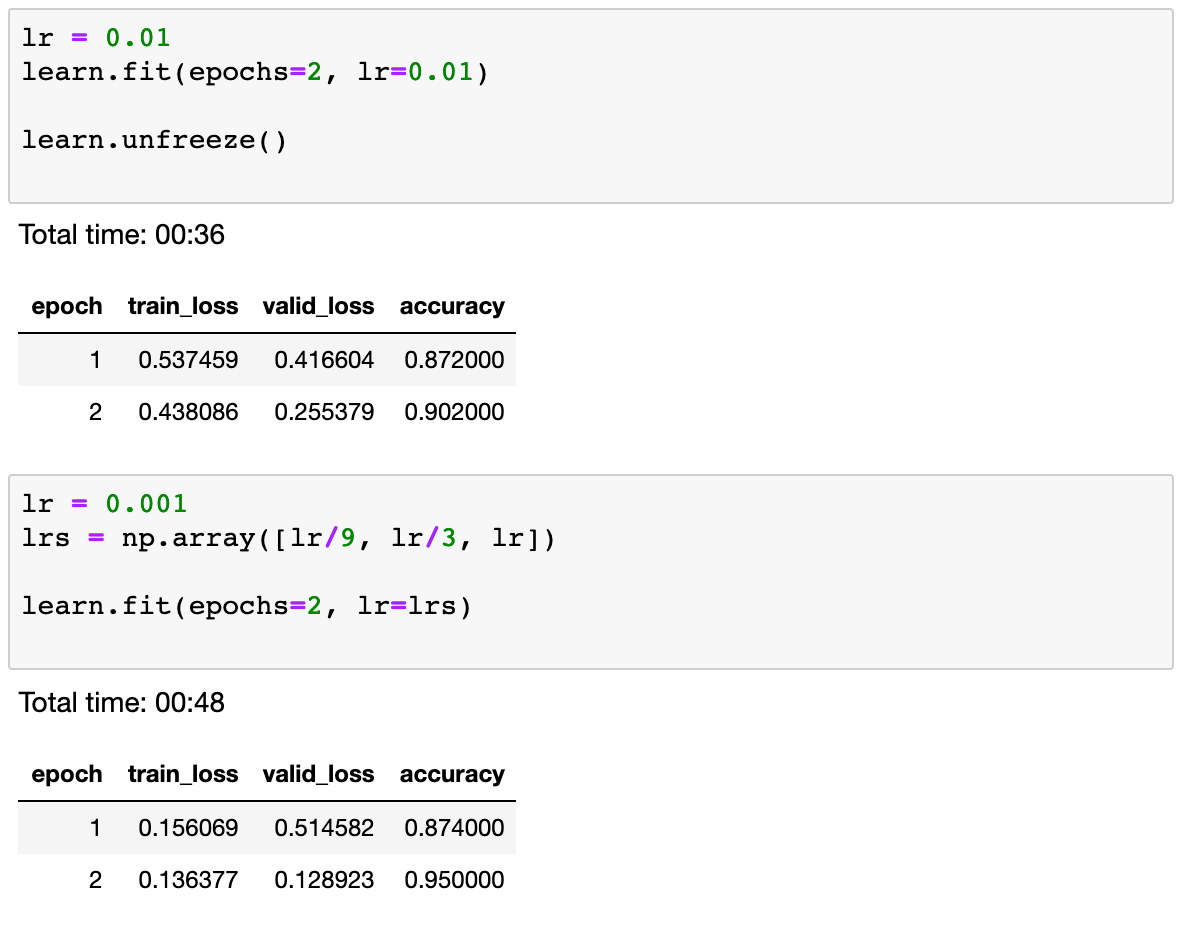
Now that we have a really good model, in order to use it in a real application, we need to be able to run predictions over an audio stream in real time.
We use the pyaudio library to read audio samples from the device microphone and then convert the audio data into numpy arrays and feed it to the model.
while True:
frames = [] # A python-list of chunks(numpy.ndarray)
for _ in range(0, int(RATE / CHUNKSIZE * RECORD_SECONDS)):
data = stream.read(CHUNKSIZE, exception_on_overflow=False)
frames.append(np.fromstring(data, dtype=np.float32))
npdata = np.hstack(frames)
audio_clip = AudioClip.from_np(npdata, RATE)
run_pred(audio_clip)The above code reads a 7-sec audio clip from the microphone and loads that into memory. It converts it to a numpy array and runs the model on them to get a prediction. This simple piece of code is now ready to be deployed to a service or an embedded device and be used in real applications!
The audio files should contain baby cry samples, with the corresponding tagging information encoded in the filenames. The samples were tagged by the contributors themselves. So here's how to parse the filenames.
0D1AD73E-4C5E-45F3-85C4-9A3CB71E8856-1430742197-1.0-m-04-hu.caf
- App instance UUID (36 chars): 0D1AD73E-4C5E-45F3-85C4-9A3CB71E8856
- Unix epoch timestamp: 1430742197 (Mon, 04 May 2015 12:23:17 GMT)
- App version: 1.0
- Gender: m (male)
- Age: 04 (0-4 weeks)
- Reason: hu (hunger)
0c8f14a9-6999-485b-97a2-913c1cbf099c-1431028888092-1.7-m-26-sc.3gp
- App instance UUID (36 chars): 0c8f14a9-6999-485b-97a2-913c1cbf099c
- Unix epoch timestamp: 1431028888092 (milliseconds)
- App version: 1.7
- Gender: m (male)
- Age: 26 (2 to 6 months old)
- Reason: sc (discomfort)
- m - male
- f - female
- 04 - 0 to 4 weeks old
- 48 - 4 to 8 weeks old
- 26 - 2 to 6 months old
- 72 - 7 months to 2 years old
- 22 - more than 2 years old
- hu - hungry
- bu - needs burping
- bp - belly pain
- dc - discomfort
- ti - tired
This repo contains an example of using DeepInfant_VGGish, DeepInfant_AFP, or DeepInfant_V2 models to build an iOS app that analyzes a baby's cry sound and pushes prediction results with a tip on how to deal with each predicted result.
If you use DeepInfant in your research, please cite the following paper:
@article{DeepInfant,
title={DeepInfant: A Deep Learning Model for Infant Cry Classification and Analysis},
author={Skytells AI Research},
year={2025}
}
For further assistance or inquiries, please reach out to the Skytells AI Research team at research@skytells.ai or visit our website at https://my.skytells.io.
[1] aqibsaeed/Urban-Sound-Classification, https://github.com/aqibsaeed/Urban-Sound-Classification, 2016
[2] Yong Xu, Qiuqiang Kong, Qiang Huang, Wenwu Wang, & Mark D. Plumbley (2017) Attention and Localization based on a Deep Convolutional Recurrent Model for Weakly Supervised Audio Tagging. arXiv:1703.06052v1
[3] Sharath Adavanne, Pasi Pertilä & Tuomas Virtanen (2017) Sound Event Detection Using Spatial Features and Convolutional Recurrent Neural Network. arXiv:1706.02291v1
DeepInfant is licensed under the Apache License 2.0.
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
Copyright 2025 Skytells AI Research
DeepInfant V2 is built on proprietary datasets along with publicly available datasets, ensuring robustness and real-world effectiveness in baby cry analysis.