- Course Name
- Algorithmic Problem Solving
- Course Code
- 23ECSE309
- Name
- Somil Yadav
- University
- KLE Technological University, Hubballi-31
- Course Instructor
- Prakash Hegade
- Portfolio Domain
-
LinkedIn
- 🌟 Introduction
- 💼 Need of Portfolio
- 🗄️ Design
- 🎯 Objectives
- 📊 Business Use Cases
- 📚 Learning Outcomes
- 📑 References
Enhancing LinkedIn Services through Data Structures and Algorithms
LinkedIn[1] is a platform designed for professionals to connect and network within the business community. Established in 2002, the platform serves as a hub for professionals to engage with former and current coworkers, expand their professional network, collaborate within their field, exchange business concepts, explore job opportunities, and recruit potential employees. This project's portfolio delves into how utilizing data structures and algorithms can greatly improve the efficiency and effectiveness of LinkedIn, utilizing skills and knowledge from the Algorithmic Problem Solving (APS) course.
This portfolio showcases how LinkedIn can be significantly improved by enhancing recommendation systems, refining search algorithms, and addressing other key functionalities. Every scenario connects theory to real-world business problems, demonstrating how advanced algorithms can enhance LinkedIn's performance, reliability, and efficiency.
An important portfolio that targets LinkedIn is needed to handle the difficult task of improving a professional networking platform by using data structures and algorithms (DSA). Improving features like search algorithms, recommendation systems and network analysis can greatly enhance user interaction and contentment. This portfolio connects academic learning with practical implementation by using theoretical knowledge from DSA and APS courses in real-world situations. It demonstrates not just the capability to address practical issues but also shows dedication to enhancing the efficiency and effectiveness of LinkedIn services, making it a valuable resource for professional growth and innovation in the tech sector.
LinkedIn[2] has over 930 million users in 200 countries. At peak load, the site is serving nearly 5 million user profile pages a second (a user’s profile page lists things like their job history, skills, recommendations, cringy influencer posts, etc.)

The workload is extremely read-heavy, where 99% of requests are reads and less than 1% are writes (you probably spend a lot more time stalking on LinkedIn versus updating your profile).
To manage the increase in traffic, LinkedIn incorporated Couchbase (a distributed NoSQL database) into their stack as a caching layer. They’ve been able to serve 99% of requests with this caching system, which drastically reduced latency and cost.
LinkedIn[3] stores the data for user profiles (and also a bunch of other stuff like InMail messages) in a distributed document database called Espresso (this was created at LinkedIn). Prior to that, they used a relational database (Oracle) but they switched over to a document-oriented database for several reasons….
1. Horizontal Scalability Document databases are generally much easier to scale than relational databases as sharding is designed into the architecture. The relational paradigm encourages normalization, where data is split into tables with relations between them. For example, a user’s profile information (job history, location, skills, etc.) could be stored in a different table compared to their post history (stored in a user_posts table). Rendering a user’s profile page would mean doing a join between the profile information table and the user posts table.
2. Schema Flexibility LinkedIn wanted to be able to iterate on the product quickly and easily add new features to a user’s profile. However, schema migrations in large relational databases can be quite painful, especially if the database is horizontally sharded. On the other hand, document databases are schemaless, so they don’t enforce a specific structure for the data being stored. Therefore, you can have documents with very different types of data in them. Also, you can easily add new fields, change the types of existing fields or store new structures of data.
LinkedIn migrated off Oracle to Espresso in the mid-2010s and this worked extremely well. They were able to scale to 1.4 million queries per second by adding additional nodes to the cluster.

However, they eventually reached the scaling limits of Espresso where they couldn’t add additional machines to the cluster. In any distributed system, there are shared components that are used by all the nodes in the cluster. In Espresso’s case, the shared components are
- Routing Layer - responsible for directing requests to the appropriate storage node
- Metadata Store - manages metadata on node failures, replication, backups, etc.
- Coordination Service - manages the distribution of data and work amongst nodes and node replicas.
LinkedIn reached the upper limits of these shared components so they couldn’t add additional storage nodes. Resolving this scaling issue would require a major re-engineering effort. Instead, the engineers decided to take a simpler approach and add Couchbase as a caching layer to reduce pressure on Espresso.
Couchbase is a combination of ideas from Membase and CouchDB, where you have the highly scalable caching layer of Membase and the flexible data model of CouchDB. It’s both a key/value store and a document store, so you can perform Create/Read/Update/Delete (CRUD) operations using the simple API of a key/value store (add, set, get, etc.) but the value can be represented as a JSON document. With this, you can access your data with the primary key (like you would with a key/value store), or you can use N1QL (pronounced nickel). This is an SQL-like query language for Couchbase that allows you to retrieve your data arbitrarily and also do joins and aggregation.
When the Profile backend service sends a read request to Espresso, it goes to an Espresso Router node. The Router nodes maintain their own internal cache (check the article for more details on this) and first try to serve the read from there.
If the user profile isn’t cached locally in the Router node, then it will send the request to Couchbase, which will generate a cache hit or a miss (the profile wasn’t in the Couchbase cache). Couchbase is able to achieve a cache hit rate of over 99%, but in the rare event that the profile isn’t cached the request will go to the Espresso storage node.
For writes (when a user changes their job history, location, etc.), these are first done on Espresso storage nodes. The system is eventually consistent, so the writes are copied over to the Couchbase cache asynchronously.

In order to minimize the amount of traffic that gets directed to Espresso, LinkedIn used three core design principles
- Guaranteed Resilience against Couchbase Failures
- All-time Cached Data Availability
- Strictly defined SLO on data divergence
LinkedIn's scalable caching architecture, combining Espresso and Couchbase, efficiently serves millions of users. This design ensures high availability, resilience, and rapid data access while maintaining strict consistency standards.
1. Applying theoretical concepts from Data Structures and Algorithms (DSA) and Algorithmic Problem Solving (APS) course to practical, real-world problems within the LinkedIn platform.
2. Addressing specific business challenges faced by LinkedIn through the application of algorithmic problem solving.
3. Exploring and implementing algorithmic solutions that enhance LinkedIn search functionality, recommendation systems, network analysis and user engagement.
4. Optimizing network analysis and connection suggestions to foster more meaningful professional relationships.
5. Improving data processing and analytics to provide valuable insights to LinkedIn users about their profiles and industry trends.

Algorithm: Breadth First Search (BFS)
Use Case: LinkedIn aims to enhance its user experience by providing connection suggestions to users. These suggestions often include second and third-degree connections, which are people that the user does not know directly but is connected to through mutual connections.

Challenges:
- Algorithm should efficiently navigating LinkedIn's vast user network.
- Algorithm should handle dynamic and ever-growing data.
Benefits:
- BFS efficiently explores shortest paths in unweighted graphs.
- Identifies relevant connections quickly.
- Ensures real-time updates as users form new connections.
Implementation:
- Start BFS from a user's profile.
- Explore all nodes at the current level before moving to the next.
Complexity Analysis:
- The time complexity of BFS is O(V+E), where V is the number of vertices(users) and E is the number of edges(connections).
- Space Complexity: The space complexity of BFS is O(V), which is needed to store the queue and the visited nodes.
Code for Breadth First Search Algorithm [4]

Algorithm: Knuth-Morris-Pratt (KMP) Algorithm
Use Case: Recruiters on LinkedIn use the KMP algorithm to enhance job matching accuracy between job descriptions and user profiles. The KMP algorithm efficiently searches for occurrences of a "pattern" (such as skills, experiences, and qualifications) within a "text" (job descriptions or candidate profiles) by preprocessing the pattern to create a partial match table. This allows for quick identification of relevant skills and qualifications shared between job descriptions and candidate profiles.
Challenges:
- Variations in how skills and qualifications are described in profiles and job descriptions can complicate accurate matching.
- Handling large volumes of profiles and job listings efficiently, ensuring quick and accurate matching without performance degradation.
- Ensuring that identified substrings truly reflect essential job qualifications to avoid mismatches.
Benefits:
- The KMP algorithm significantly reduces the time complexity of substring search, making the matching process efficient.
- By preprocessing the pattern, the KMP algorithm avoids redundant comparisons, improving performance.
- Identifying exact matches of relevant skills ensures that job recommendations closely align with the candidate's capabilities and the employer's needs.
Implementation:
- Preprocessing the pattern to create an LPS (longest prefix suffix) array that helps in skipping unnecessary comparisons.
- Traverse through the text and pattern using two pointers, comparing characters.
- Adjust the pattern pointer based on the LPS array upon mismatches to efficiently search for occurrences of the pattern within the text.
Complexity Analysis:
- Time Complexity: O(N + M) where N is the length of the text and M is the length of the pattern.
- Space Complexity: O(M) for the partial match table.

Algorithm: Trie Data Structure with Autocomplete Feature
Use Case: LinkedIn's profile search functionality enables users to quickly find other professionals by typing in names, job titles, skills, or other relevant keywords. Utilizing a trie data structure allows for efficient and fast search capabilities, providing real-time autocomplete suggestions as users input their queries.
Challenges:
- LinkedIn faces the challenge of managing a vast and ever-growing dataset of user profiles.
- Providing fast and accurate search results demands processing user input swiftly.
- The system must handle frequent updates to the dataset as new profiles are added or existing ones are modified.
Benefits:
- The trie data structure optimizes prefix matching, facilitating quick identification and suggestion of profiles that match user queries.
- Tries efficiently manage large datasets, making them suitable for LinkedIn’s extensive database of user profiles.
- Tries support real-time updates, ensuring new profiles and changes are reflected in search results promptly.
Implementation Steps:
- Defining trie nodes with links to child nodes and markers for word endings.
- Insert profiles (names, job titles, skills) into the trie.
- Implementing search functionality that traverses the trie based on user input, providing autocomplete suggestions.
- Ensuring the trie supports dynamic updates to seamlessly add or remove profiles.
Complexity Analysis
- Time Complexity: O(N*L) where N is the number of words in the trie and L is the length of the longest word in the trie.
- Space Complexity: O(N*L+N * ALPHABET_SIZE)
Code for Trie implementing Auto Complete Feature [6]

Algorithm: Heap Sort
Use Case: LinkedIn provides real-time job recommendations to its users, ensuring they have access to the most relevant job opportunities based on their profiles, search history, and platform activity. This feature is crucial for both job seekers looking for new opportunities and employers seeking the best candidates.
Challenges:
- LinkedIn faces the challenge of efficiently processing vast amounts of job postings and user data.
- LinkedIn must constantly analyze and rank millions of job postings to deliver timely and relevant recommendations to each user.
Benefits:
- LinkedIn employs heap sort to maintain a max-heap, prioritizing job postings based on relevance scores or other criteria.
- The heap structure enables quick retrieval of top K job recommendations, ensuring users receive the most relevant opportunities promptly.
- LinkedIn dynamically updates the heap as new job postings are added or user preferences change, ensuring recommendations are always current.
Implementation
- Build a max-heap where job postings are organized based on their relevance scores.
- Implement heap sort to retrieve the top K job recommendations efficiently.
- Update the heap structure dynamically to reflect changes in job postings and user preferences.
Complexity Analysis
- Time Complexity: The time complexity of heap sort is O(nlogn), where n is the number of job postings.
- Space Complexity: O(log n), due to the recursive call stack. However, auxiliary space can be O(1) for iterative implementation.

Algorithm: Rabin-Karp Algorithm
Use Case: LinkedIn aims to enhance user experience by detecting and suggesting similar profiles based on shared skills and experiences. This feature helps users discover like-minded professionals, potential mentors, or candidates with similar qualifications for networking or recruitment purposes.
Challenges:
- The primary challenge in profile similarity detection is efficiently comparing a vast number of profiles.
- Each profile contains multiple sections, such as skills, work experiences, and education, which need to be analyzed for similarities.
- Handling this large volume of data in real-time requires a robust algorithm that can quickly and accurately identify matching substrings.
Benefits:
- The Rabin-Karp algorithm is particularly effective for this use case due to its ability to efficiently find matching substrings within large datasets.
- By using hashing, Rabin-Karp can quickly compare sections of profiles, identifying similar skills and experiences with minimal computational overhead.
- This efficiency is crucial for real-time applications, allowing LinkedIn to provide immediate profile similarity suggestions as users update their profiles or as new users join the platform.
Implementation Steps:
- Defining a suitable hash function to generate hashes for profile sections (e.g., skills, work experiences).
- Implement Rabin-Karp to compare hashed values of profile sections to identify similar profiles.
- Continuously update the similarity suggestions as profiles are updated or new profiles are added to the platform.
Complexity Analysis
- Time Complexity: The average time complexity of Rabin-Karp for matching a pattern of length m within a text of length n is O(n + m).
- Space Complexity: The space complexity of Rabin-Karp is O(m), where m is the length of the pattern. This is required to store the hash values and the pattern itself.
Code for Rabin-Karp Algorithm [8]

Algorithm: Quick Sort
Use Case: LinkedIn aims to keep users engaged by displaying the most popular and engaging posts and articles prominently. Identifying and showcasing trending content ensures that users are presented with relevant and timely information, fostering a dynamic and interactive platform.
Challenges:
- The primary challenge in identifying and displaying trending content is efficiently handling the massive volume of data generated by user interactions.
- The algorithm must handle real-time updates to engagement metrics and ensure that the trending content list is continuously updated.
Benefits:
- Quick Sort is particularly well-suited for sorting large datasets due to its average-case time complexity of O(n log n) and its in-place sorting capability.
- For LinkedIn, Quick Sort can efficiently rank posts and articles by their engagement metrics, ensuring that the most trending content rises to the top.
- The algorithm's ability to handle large volumes of data makes it ideal for LinkedIn’s extensive content repository.
Implementation Steps:
- Implementing a partitioning function to divide content based on engagement metrics (e.g., likes, shares, comments).
- Applying Quick Sort recursively to sort posts and articles based on their engagement metrics.
- Continuously monitor and update the sorted list as new content is created or existing content's engagement metrics change.
Complexity Analysis
- Time Complexity: The average time complexity of Quick Sort is O(nlogn), where n is the number of posts or articles.
- Space Complexity: The space complexity of Quick Sort is O(log n) for the in-place version, which is needed for the recursion stack.

Algorithm: Aho-Corasick Algorithm
Use Case: LinkedIn needs to efficiently detect and prevent spam content to maintain a professional and valuable user experience. Using the Trie data structure combined with the Aho-Corasick algorithm allows LinkedIn to quickly and accurately identify spam content by matching patterns against a predefined set of spam indicators.
Challenges
- Volume of Content: Managing and scanning the vast amount of user-generated content efficiently.
- False Positives/Negatives: Ensuring the accuracy of spam detection to avoid blocking legitimate content or missing spam.
- Scalability: Maintaining performance and accuracy as the platform grows and the volume of content increases.
Benefits
- Efficient Pattern Matching: The Aho-Corasick algorithm, built on a Trie, enables fast and simultaneous multi-pattern matching, allowing LinkedIn to scan for multiple spam patterns in a single pass. This efficiency is crucial for handling large datasets.
- Low Memory Usage: The Trie structure efficiently stores and manages the spam patterns, ensuring that the algorithm uses memory proportional to the number of patterns and their lengths. This makes it scalable as the list of spam patterns grows.
- Ease of Update: Adding new spam patterns to the Trie is straightforward, ensuring that LinkedIn can adapt to emerging spam tactics quickly and without significant overhead.
Implementation Steps
- Collecting a comprehensive list of spam indicators and patterns, including keywords, phrases, and common spam content structures
- Constructing a Trie (prefix tree) using the collected spam patterns, where each node in the Trie represents a character in the pattern and the paths from the root to the leaves represent complete spam patterns
- Implementing the Aho-Corasick algorithm to create failure links in the Trie, which help to backtrack and continue the search efficiently when a partial match fails, ensuring that the algorithm can handle overlapping patterns
- Scaning user-generated content using the Aho-Corasick algorithm, matching it against the patterns stored in the Trie, so that the algorithm will efficiently identify any occurrences of the spam patterns in the content
- When a spam pattern is detected, flag the content for further review or automatic action, such as removal or alerting the user, and implement a scoring or threshold mechanism to handle false positives and ensure that legitimate content is not incorrectly flagged
Complexity Analysis:
- Time Complexity: O(n + l + z), where ‘n’ is the length of the text, ‘l’ is the length of keywords, and ‘z’ is the number of matches.
- Space Complexity: O(l * q), where ‘q’ is the length of the alphabet since that is the maximum number of children a node can have.
Code for Aho-Corasick Algorithm [10]

Algorithm: Trie Data Structure
Use Case: LinkedIn aims to help users optimize their profiles by providing suggestions for updates and improvements. These suggestions can include common phrases or keywords that enhance profile visibility and relevance to potential employers or connections. By leveraging a trie data structure, LinkedIn can efficiently store and retrieve these common phrases or keywords, offering users real-time, contextually relevant suggestions as they update their profiles.
Challenges
- Efficiently manage a large dictionary of phrases and keywords that are constantly evolving with industry trends.
- Provide real-time suggestions as users type, which requires fast and efficient data retrieval.
Benefits
- The trie data structure is particularly well-suited for this use case due to its ability to store and retrieve strings efficiently.
- Tries allow for fast prefix searches, which means LinkedIn can provide real-time suggestions as users type keywords or phrases into their profiles.
- This efficiency enhances user experience by offering immediate and relevant suggestions, encouraging users to optimize their profiles with industry-standard terms and phrases.
- Tries also handle large dictionaries of phrases and keywords with ease, making them scalable for LinkedIn’s extensive user base.
Algorithm Implementation
- Collecting a comprehensive list of common phrases and keywords relevant to various industries and roles
- Constructing a trie data structure using the collected phrases and keywords, where each node represents a character and paths represent complete words or phrases
- Implementing an autocomplete feature using the trie, allowing for fast prefix searches as users type
- Integrating the trie-based suggestion system into the profile update interface, providing real-time suggestions based on user input
- Regularly update the trie with new phrases and keywords to reflect evolving industry trends
Complexity Analysis
- Time Complexity: The time complexity for inserting and searching in a trie is O(L), where L is the length of the word.
- Space Complexity: The space complexity of a trie is O(AL), where A is the size of the alphabet and L is the number of words.
Code using Trie Data Structure [11]

Algorithm: Z Algorithm
Use Case: LinkedIn aims to enhance the accuracy of its search results and content recommendations by efficiently matching keywords within posts and articles. Accurate keyword matching ensures that users find relevant content quickly, whether they are searching for specific topics, industry insights, or professional advice. By leveraging the Z algorithm, LinkedIn can improve the precision of its search functionality and content recommendations, enhancing user satisfaction and engagement.
Challenges
- Each search query needs to be processed against millions of posts and articles to find relevant matches
- The algorithm must be capable of performing these matches quickly and accurately to provide real-time search results and recommendations
Benefits
- The Z algorithm is highly efficient for this use case due to its linear time complexity for pattern matching
- The Z algorithm processes the input text and pattern in O(n + m) time, where n is the length of the text and m is the length of the pattern
- This efficiency is essential for handling large datasets and providing real-time keyword matching
- By computing the Z array, the algorithm identifies all occurrences of the pattern (keyword) within the text, ensuring accurate and comprehensive matches
- This accuracy enhances the relevance of search results and content recommendations, improving user experience
Implementation
- Collecting and preprocess the dataset of posts and articles
- Constructing the Z array for the keyword (pattern) to be matched
- Implementing the Z algorithm to search for the keyword in each post and article
- Identifying and record all occurrences of the keyword within the text
- Integrating the keyword matching system into the search and recommendation engine
Complexity Analysis
- Time Complexity: The Z algorithm has a time complexity of O(n + m), where n is the length of the text and m is the length of the pattern.
- Space Complexity: The space complexity of the Z algorithm is O(n + m) to store the Z array and the input text.

Algorithm: Topological Sort Algorithm
Use Case: LinkedIn aims to recommend professional groups to users in a logical and sequential manner based on their current affiliations, interests, and activity. Joining relevant groups can significantly enhance users' professional networks, provide access to valuable content, and foster meaningful interactions. By using topological sort, LinkedIn can ensure that group recommendations follow a logical order.
Challenges
- Efficiently handle the dependencies and relationships between different groups
- Considering the hierarchical structure of professional interests and affiliations to provide meaningful and contextually relevant recommendations
Benefits
- Topological sort is particularly well-suited for this use case due to its ability to handle directed acyclic graphs (DAGs)
- In the context of group recommendations, a DAG can represent the hierarchical and dependency relationships between different professional groups
- By performing a topological sort on this graph, LinkedIn can determine a logical sequence of group recommendations, ensuring that users are introduced to groups in an order that aligns with their professional progression and interests
- This approach enhances the relevance and value of recommendations, encouraging users to join groups that are most beneficial to their professional growth
- Topological sort is efficient, with a time complexity of O(V + E), where V is the number of vertices (groups) and E is the number of edges (dependencies)
Implementation
- Identifying and represent professional groups and their hierarchical relationships as a directed acyclic graph (DAG)
- Constructing the DAG with groups as vertices and dependencies as edges
- Implementing the topological sort algorithm to process the DAG and determine a logical order of groups
- Generating group recommendations for users based on the sorted order
- Integrating the sorted group recommendations into the user interface, providing contextually relevant suggestions
Complexity Analysis
- Time Complexity: The time complexity of topological sort is O(V + E), where V is the number of vertices (groups) and E is the number of edges (dependencies).
- Space Complexity: The space complexity of topological sort is O(V + E) to store the graph representation and the resulting sorted list.
Code for Topological Sorting [13]

Algorithm: Radix Sort
Use Case: LinkedIn aims to identify trending skills that are frequently mentioned in user profiles and job postings. By doing so, LinkedIn can provide insights into current industry demands and help users enhance their profiles to align with market trends. Additionally, identifying trending skills can help LinkedIn suggest relevant courses and learning materials to users, further enhancing their professional development.
Challenges
- Efficiently sorting and analyzing the large volume of data from millions of profiles and job postings
- Processing this data quickly to provide real-time updates on trending skills
- Handling the diverse ways in which skills are listed and ensuring accurate frequency counts
Benefits
- Radix Sort is particularly well-suited for this use case due to its linear time complexity for sorting large datasets
- Unlike comparison-based sorting algorithms, Radix Sort processes each digit of the numbers (or characters in the case of strings) in a fixed number of passes, making it highly efficient for sorting large volumes of data
- This efficiency is crucial for processing the vast amount of data generated by LinkedIn users
- Radix Sort can handle the diverse representations of skills by sorting them based on their frequency of appearance
Implementation
- Collecting and preprocess data from user profiles and job postings to extract mentioned skills
- Assigning frequency counts to each skill based on their occurrences in the collected data
- Using Radix Sort to sort the skills based on their frequency counts in linear time
- Identifying the top trending skills from the sorted list
Complexity Analysis
- Time Complexity: The time complexity of Radix Sort is O(nk), where n is the number of items and k is the number of digits in the largest number (or characters in the longest string).
- Space Complexity: The space complexity of Radix Sort is O(n + k), which is needed to hold the temporary arrays during sorting.

Algorithm: Quick Select Algorithm
Use Case: LinkedIn aims to enhance its security measures by identifying and prioritizing the detection of fraudulent accounts based on suspicious activity metrics. Detecting and mitigating fraudulent activity is crucial to maintaining the integrity and trustworthiness of the platform. By using the Quick Select algorithm, LinkedIn can efficiently identify the top K suspicious accounts, allowing for focused and effective fraud detection efforts.
Challenges
- Identifying accounts exhibiting unusual or suspicious behaviors, such as high volumes of connection requests, message spamming, or profile views
- Quickly identify the most suspicious accounts to prioritize investigative efforts
Benefits
- The Quick Select algorithm is particularly well-suited for this use case due to its efficiency in finding the k-th smallest (or largest) element in an unsorted list
- Quick Select operates in O(n) average time complexity, making it ideal for quickly identifying the top K suspicious accounts based on predefined activity metrics
- By focusing only on the most suspicious accounts, LinkedIn can allocate resources more effectively, ensuring timely intervention and reducing the risk of fraudulent activity
Implementation
- Collecting and preprocess data on user activity metrics, such as connection requests, messages sent, and profile views
- Defining a scoring system to quantify suspicious activity based on these metrics
- Applying the Quick Select algorithm to identify the top K accounts with the highest suspicious activity scores
- Prioritizing these top K accounts for further investigation and potential action
Complexity Analysis
- Time Complexity: The average time complexity of Quick Select is O(n), where n is the number of accounts.
- Space Complexity: The space complexity of Quick Select is O(1) for the iterative version, making it space-efficient and suitable for large datasets.
Code for Quick Sort Algorithm [15]


Algorithm: Merge Sort
Use Case: LinkedIn needs to efficiently sort messages and notifications to enhance user experience by presenting the most relevant and timely information. Sorting can be based on various criteria such as timestamp, priority, or user-defined preferences.
Challenges
- Handling the large volume of data generated by LinkedIn users
- Ensuring the sorting algorithm is efficient and scalable to process data in real-time
- Accommodating different sorting criteria such as time received, importance, or user-defined preferences
Benefits
- Merge Sort is an excellent choice for this use case due to its stable and efficient sorting capabilities
- It has a time complexity of O(n log n) for both worst and average cases, making it reliable for large datasets
- Merge Sort works by recursively dividing the data into smaller subarrays, sorting them, and then merging them back together
- This divide-and-conquer approach ensures that the algorithm performs well even with large volumes of messages and notifications
- Merge Sort is stable, meaning it preserves the relative order of equal elements, which is important when sorting by multiple criteria
Implementation
- Collecting and preprocess messages and notifications data, ensuring each item has the necessary attributes for sorting (e.g., timestamp, priority)
- Defining the sorting criteria (e.g., first by timestamp, then by priority)
- Implementing the Merge Sort algorithm to recursively divide the messages and notifications into smaller subarrays
- Sorting each subarray based on the defined criteria
- Merging the sorted subarrays back together to form a single sorted list
Complexity Analysis
- **Time Complexity:**Merge Sort has a time complexity of O(n log n) for all cases (worst, average, and best).
- Space Complexity: The space complexity of Merge Sort is O(n) due to the auxiliary space required for merging.

Algorithm: Trie Data Structure
Use Case: LinkedIn's ATS (Applicant Tracking System) score calculation aims to evaluate resumes based on specific parameters such as keywords, experience, education, and skills. A Trie data structure can be effectively used to store and match keywords and phrases from resumes, enabling quick and efficient scoring.
Challenges
- Handling large volumes of resumes
- Accurately matching keywords and phrases
- Ensuring that the scoring algorithm is efficient and scalable
- Processing resumes quickly to provide meaningful scores based on predefined criteria
Benefits
- Tries allow for fast insertion and search operations, making them ideal for matching keywords and phrases in resumes
- Tries can handle a large number of keywords and phrases, ensuring scalability as the database of resumes grows
- Tries provide exact matches for keywords and phrases, improving the accuracy of the ATS scoring system
Implementation
- Defining a list of keywords, phrases, and parameters relevant to the ATS scoring criteria
- Constructing a Trie data structure to store these keywords and phrases
- Preprocessing resumes to extract relevant information such as keywords, experience, education, and skills
- Inserting the extracted keywords and phrases from each resume into the Trie for quick lookup
- Implementing a scoring algorithm that searches the Trie for matches and calculates a score based on the frequency and relevance of matched keywords and phrases
Complexity Analysis
- Time Complexity: O(NL) for calculating ATS score, where N is the number of words in the resume and L is the average length of words.
- Space Complexity: O(ML+NL), where M is the number of unique keywords in the Trie, L is the average length of words in the Trie, and N is the number of words in the resume.
Code using Trie Data Structure [11]

Algorithm: Hash Table
Use Case: LinkedIn allows users to mark posts or ads as "not interested," aiming to personalize content by excluding unwanted items from their feed. A Hash Table (HashMap) can efficiently manage and retrieve these preferences, ensuring that marked posts or ads are appropriately filtered out.
Challenges
- Ensuring fast retrieval of user preferences
- Scalability to handle a large number of users and posts
- Minimizing memory usage while maintaining efficient operations
- Handling concurrent updates and providing real-time feedback to users without compromising performance
Benefits
- Hash Tables provide O(1) average-time complexity for insertions, deletions, and lookups, making them ideal for quick retrieval of user preferences.
- Hash Tables use a fixed amount of memory proportional to the number of entries, optimizing memory usage compared to data structures like trees.
- Hash Tables can scale with LinkedIn’s growing user base and content volume, ensuring that the system remains responsive and efficient over time.
Implementation
- Implementing a Hash Table to store user preferences for "not interested" posts or ads, using the post or ad identifier as keys.
- Providing interfaces for users to mark items as "not interested" and update the Hash Table accordingly.
- Ensuring efficient retrieval of user preferences using the Hash Table to filter out marked items from the user's feed.
- Optimizing Hash Table operations to handle concurrent updates and maintain real-time responsiveness.
Complexity Analysis
- Time Complexity: Insertion, deletion, and lookup operations in a Hash Table have an average time complexity of O(1). In rare cases, these operations can degrade to O(n).
- Space Complexity: The space complexity of a Hash Table is O(n), where n is the number of entries (user IDs with associated sets of "not interested" item IDs).
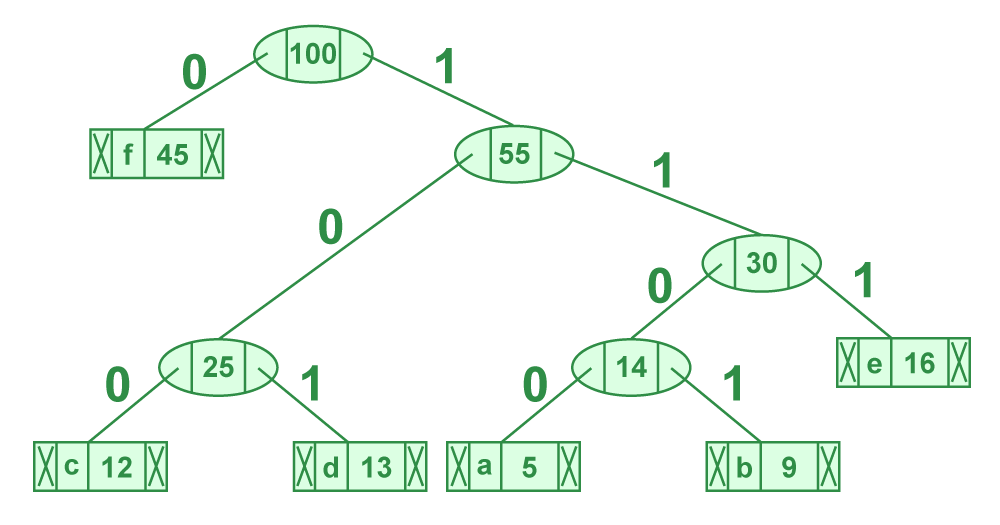
Algorithm: Huffman Coding
Use Case: Huffman coding, a widely used entropy encoding algorithm, is adept at achieving significant compression ratios by assigning shorter codes to more frequent symbols or data segments. This approach proves particularly effective in compressing images and videos, where reducing redundancy in pixel values or frames can lead to substantial savings in storage or transmission bandwidth.
Challenges
- Balancing compression ratio with computational complexity
- Ensuring that decompression does not degrade visual fidelity
- Efficiently handling diverse data distributions within images and videos
Benefits
- By assigning shorter codes to frequently occurring symbols, Huffman coding reduces the overall size of image and video files.
- The algorithm optimizes compression based on varying data distributions, enhancing efficiency across different types of content.
- Huffman-encoded data can be decompressed quickly, facilitating rapid access to compressed media for viewing or editing.
Implementation
- Analyzing the frequency of symbols (e.g., pixel values, frame patterns) within images or videos to build a Huffman tree.
- Generating Huffman codes based on symbol frequencies, assigning shorter codes to more frequent symbols.
- Encoding images or video frames using the generated Huffman codes to achieve compression.
- Storing or transmit the Huffman-encoded data, ensuring efficient use of storage or bandwidth.
- Implementing a decompression algorithm that reconstructs images or video frames from Huffman-encoded data.
Complexity Analysis
- Time Complexity: The Huffman tree and encoding/decoding operations typically operate in O(n log n) time complexity, where n represents the number of symbols or data segments being processed.
- Space Complexity: The space overhead in Huffman coding is O(n) space, where n is the number of unique symbols or data segments.

Algorithm: Dynamic Programming
Use Case: LinkedIn computes the Social Selling Index (SSI) score to quantify a user's effectiveness in social selling activities. Using dynamic programming, LinkedIn calculates this score based on several key metrics.
Challenges:
- Metric Integration: Incorporating diverse metrics like profile completeness, network influence, engagement, and content quality.
- Complexity Management: Handling the complexity of metric interactions and their contributions to the overall score.
- Real-time Updates: Ensuring timely updates reflecting users' current activities and network dynamics.
Benefits:
- Provides a numerical score reflecting user engagement and effectiveness in social selling.
- Enables users to monitor their progress and identify areas for improvement.
- Facilitates comparison against peers and industry standards.
Implementation:
- Defining metrics such as profile completeness, network reach, engagement rate, and content relevance.
- Using dynamic programming to maintain states representing cumulative contributions of each metric.
- Computing the SSI score iteratively by optimizing metric contributions to maximize user engagement and effectiveness.
Complexity Analysis:
- Time Complexity: Calculating set difference involves iterating through sections, resulting in a time complexity of O(n), where n is the total number of sections (average case for set operations).
- Space Complexity: Storing sets requires O(m + k) space, where m is the number of existing sections and k is the number of recommended sections.
Code using Dynamic Programming [19]

Algorithm: KD Tree
Use Case: LinkedIn users frequently seek nearby networking events such as conferences, meetups, and seminars relevant to their industry or interests. Implementing a KD Tree allows efficient geographic search to discover events based on proximity to a user's location, enhancing user engagement and facilitating community interaction.
Challenges:
- Handling diverse event locations and formats across different regions and countries.
- Ensuring precise geographic proximity calculations to recommend relevant events.
- Efficiently managing and querying a large number of event locations and user queries.
Benefits:
- Enables users to discover and attend relevant networking events conveniently located near them.
- Facilitates interaction and networking opportunities among professionals sharing similar interests or industries.
- Supports LinkedIn's mission to connect professionals worldwide by providing access to diverse and accessible networking events.
Implementation:
- Storing event locations in a KD Tree data structure, which organizes spatial data for efficient range searches.
- Utilizing KD Tree algorithms to perform nearest neighbor searches, identifying events closest to a user's specified location.
- Presenting search results to users, displaying relevant events based on proximity and user preferences.
Complexity Analysis:
- Time Complexity: Search Operation, O(log n), where n is the number of event locations stored in the KD Tree. This ensures efficient retrieval of nearby events.
- Space Complexity: Storage of KD Tree, O(n), where n is the number of event locations, accounting for the spatial partitioning and storage overhead.
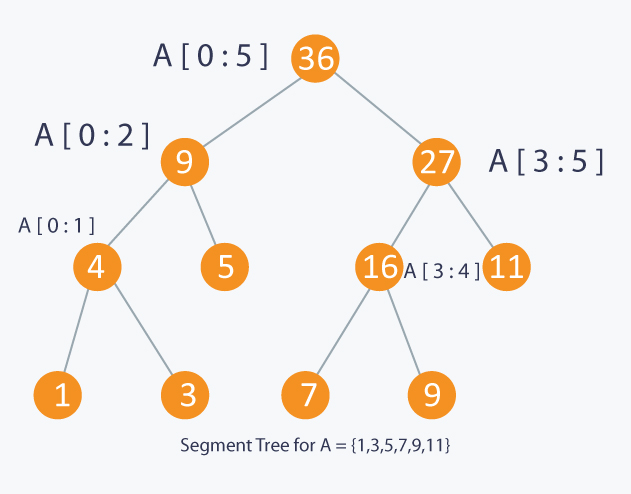
Algorithm: Lazy Propagation
Use Case: LinkedIn optimizes content display by employing Lazy Propagation to update content metrics based on user interactions effectively. This approach ensures that relevant and engaging content is prominently featured to increase user engagement and interaction on the platform.
Challenges:
- Ensuring that content metrics reflect current user interactions without introducing delays.
- Maintaining consistency across distributed systems while updating aggregate metrics based on user behavior.
- Handling large volumes of user interactions and ensuring efficient computation and propagation of metrics.
Benefits:
- Displays content that is more relevant and engaging to users based on their interactions, improving overall user satisfaction.
- Promotes interaction by featuring content that users are more likely to find valuable, thereby increasing user engagement metrics.
- Reduces computational overhead by deferring updates until necessary, optimizing resource utilization in content management.
Implementation:
- Representing content metrics (e.g., views, likes, shares) using lazy propagation techniques to delay updates until metrics are accessed or modified.
- Implementing lazy propagation to aggregate and propagate content metrics based on user interactions, ensuring efficient computation.
- Use updated metrics to optimize content display algorithms, promoting content with higher engagement metrics to users.
Complexity Analysis:
- Time Complexity: Update Operation, O(log n), where n is the number of content items or interactions. Lazy propagation minimizes the number of updates by deferring computations until necessary, optimizing overall time complexity.
- Space Complexity: Storage of Metrics, O(n), where n is the number of content items or interactions, plus additional space for storing propagation structures. This ensures efficient storage and retrieval of updated metrics.
Code for Lazy Propagation [21]

Algorithm: B-Tree
Use Case: LinkedIn can optimize the storage and retrieval of large-scale profile data using B-Trees. This balanced tree data structure efficiently manages and accesses extensive datasets, supporting LinkedIn's diverse profile information requirements across its vast user base.
Challenges:
- Handling massive volumes of profile data while ensuring efficient insertion, deletion, and retrieval operations.
- Supporting rapid growth and diversity in user profiles and associated data without compromising performance.
- Managing complex queries related to professional profiles, connections, and network interactions.
Benefits:
- B-Trees enable quick access to profile data with logarithmic time complexity for insertion, deletion, and retrieval operations.
- Supports LinkedIn's scalability needs by efficiently organizing and managing large datasets of profile information.
- Ensures data integrity and reliability by maintaining balanced tree structures suitable for transactional and query-intensive applications.
Implementation:
- Storing profile data in B-Trees to maintain balanced tree structures optimized for efficient data retrieval and management.
- Utilizing B-Tree properties to enhance query performance, supporting rapid access to user profiles and associated information.
- Managing memory and disk space efficiently to accommodate growing volumes of profile data and ensure responsive data access.
Complexity Analysis:
- Time Complexity: Insertion, Deletion, Retrieval, O(log n), where n is the number of profiles stored in the B-Tree. This ensures efficient handling of large-scale data operations.
- Space Complexity: Storage of B-Tree, O(n), where n is the number of profiles, plus additional space for tree structure overhead. B-Trees maintain efficient use of memory and disk space for large datasets.
- Applying theoretical knowledge from Algorithmic Problem Solving (APS) courses to real-world scenarios.
- Enhancing problem-solving skills through practical application of data structures and algorithms (DSA).
- Designing and implementing algorithms for specific functionalities like recommendation systems and search optimization.
- Creating clear and informative GitHub READMEs to effectively communicate project details and usage instructions.
- Developing well-structured and documented code to ensure readability and maintainability.
- Customizing themes and layouts in Jekyll for dynamic and responsive website development.
- Applying Data Structures and Algorithms (DSA) to solve real-world problems efficiently.
- Implementing competitive programming (CP) algorithms to optimize solutions for algorithmic challenges.
- Leveraging GitHub as a collaborative platform for version control and project management.
- Using Jekyll for rapid prototyping and deployment of websites with minimal configuration.
-
[1] LinkedIn: https://in.linkedin.com/
-
[2] Wikipedia: https://en.wikipedia.org/wiki/LinkedIn
-
[3] LinkedIn Blog: https://blog.quastor.org/p/linkedin-serves-5-million-user-profiles-per-second
-
[4] Breadth First Search Algorithm: https://www.hackerearth.com/practice/algorithms/graphs/breadth-first-search/tutorial/
-
[5] KMP Algorithm: https://cp-algorithms.com/string/prefix-function.html
-
[6] Trie Auto Complete Feature: https://www.geeksforgeeks.org/auto-complete-feature-using-trie/
-
[7] Heap Sort: https://www.hackerearth.com/practice/algorithms/sorting/heap-sort/tutorial/
-
[8] Robin Karp Algorithm: https://cp-algorithms.com/string/rabin-karp.html
-
[9] Quick Sort: https://www.geeksforgeeks.org/quick-sort-algorithm/
-
[10] Aho Corasick Algorithm: https://cp-algorithms.com/string/aho_corasick.html
-
[11] Trie Data Structure: https://www.hackerearth.com/practice/data-structures/advanced-data-structures/trie-keyword-tree/tutorial/
-
[12] Z Algorithm: https://cp-algorithms.com/string/z-function.html
-
[13] Topological Sort Algorithm: https://www.geeksforgeeks.org/topological-sorting/
-
[14] Radix Sort: https://www.javatpoint.com/radix-sort
-
[15] Quick Select Algorithm: https://www.geeksforgeeks.org/quickselect-algorithm/
-
[16] Merge Sort Algorithm: https://www.geeksforgeeks.org/merge-sort/
-
[17] Heap Data Structure: https://www.geeksforgeeks.org/heap-data-structure/
-
[18] Huffman Coding and Decoding: https://www.topcoder.com/thrive/articles/huffman-coding-and-decoding-algorithm
-
[19] Dyanamic Programming: https://cp-algorithms.com/dynamic_programming/intro-to-dp.html
-
[20] K Dimensional Tree: https://www.geeksforgeeks.org/search-and-insertion-in-k-dimensional-tree/
-
[21] Lazy propagation in Segment Tree: https://www.geeksforgeeks.org/lazy-propagation-in-segment-tree/
-
[22] B tree: https://www.geeksforgeeks.org/introduction-of-b-tree-2/