Spark 是当今最流行的分布式大规模数据处理引擎,被广泛应用在各类大数据处理场景。
MapReduce 通过简单的 Map 和 Reduce 的抽象提供了一个编程模型,可以在一个由上百台机器组成的集群上并发处理大量的数据集,而把计算细节隐藏起来。各种各样的复杂数据处理都可以分解为 Map 或 Reduce 的基本元素。这样,复杂的数据处理可以分解为由多个 Job(包含一个 Mapper 和一个 Reducer)组成的有向无环图(DAG),然后每个 Mapper 和 Reducer 放到 Hadoop 集群上执行,就可以得出结果。
第一,MapReduce 模型的抽象层次低,大量的底层逻辑都需要开发者手工完成。
第二,只提供 Map 和 Reduce 两个操作。很多现实的数据处理场景并不适合用这个模型来描述。实现复杂的操作很有技巧性,也会让整个工程变得庞大以及难以维护。
第三,在 Hadoop 中,每一个 Job 的计算结果都会存储在 HDFS 文件存储系统中,所以每一步计算都要进行硬盘的读取和写入,大大增加了系统的延迟。
由于这一原因,MapReduce 对于迭代算法的处理性能很差,而且很耗资源。因为迭代的每一步都要对 HDFS 进行读写,所以每一步都需要差不多的等待时间。
第四,只支持批数据处理,欠缺对流数据处理的支持。
Spark 最基本的数据抽象叫作弹性分布式数据集(Resilient Distributed Dataset, RDD),它代表一个可以被分区(partition)的只读数据集,它内部可以有很多分区,每个分区又有大量的数据记录(record)。
Spark 提供了很多对 RDD 的操作,如 Map、Filter、flatMap、groupByKey 和 Union 等等,极大地提升了对各种复杂场景的支持。开发者既不用再绞尽脑汁挖掘 MapReduce 模型的潜力,也不用维护复杂的 MapReduce 状态机。
相对于 Hadoop 的 MapReduce 会将中间数据存放到硬盘中,Spark 会把中间数据缓存在内存中,从而减少了很多由于硬盘读写而导致的延迟,大大加快了处理速度。
由于 Spark 可以把迭代过程中每一步的计算结果都缓存在内存中,所以非常适用于各类迭代算法。
在任务(task)级别上,Spark 的并行机制是多线程模型,而 MapReduce 是多进程模型。多进程模型便于细粒度控制每个任务占用的资源,但会消耗较多的启动时间。而 Spark 同一节点上的任务以多线程的方式运行在一个 JVM 进程中,可以带来更快的启动速度、更高的 CPU 利用率,以及更好的内存共享。
从狭义上来看,Spark 只是 MapReduce 的替代方案,大部分应用场景中,它还要依赖于 HDFS 和 HBase 来存储数据,依赖于 YARN 来管理集群和资源。
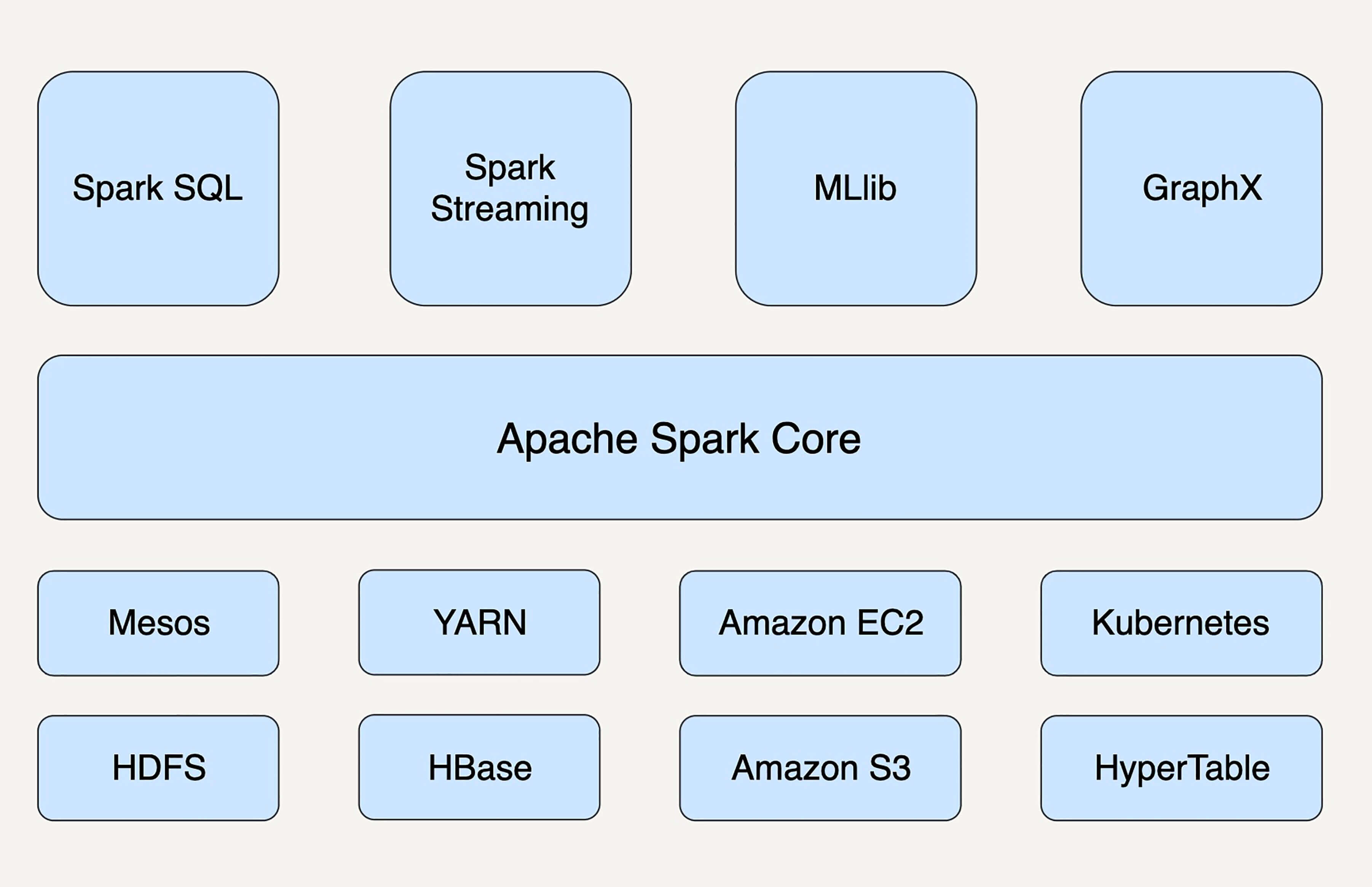
此外,作为通用的数据处理平台,Spark 有五个主要的扩展库,分别是支持结构化数据的 Spark SQL、处理实时数据的 Spark Streaming、用于机器学习的 MLlib、用于图计算的 GraphX、用于统计分析的 SparkR。这些扩展库与 Spark 核心 API 高度整合在一起,使得 Spark 平台可以广泛地应用在不同数据处理场景中。
Spark 相较于 MapReduce 的主要优势在于,极快的处理速度、易于开发及维护,和更高的适用性。
你认为有哪些 MapReduce 的缺点是在 Spark 框架中依然存在的?用什么思路可以解决?
参考答案:
mr编程模型单一,维护成本高,多个job执行时每个都要数据落盘。而spark拥有更高的抽象级别rdd,一次读取数据后便可在内存中进行多步迭代计算,对rdd的计算是多线程并发的所有很高效。 但是spark依然会存在数据倾斜的情况,在shuffle时有可能导致一个成为数据热点的情况