Spark 最基本的数据抽象是弹性分布式数据集(Resilient Distributed Dataset, 下文用 RDD 代指)。
传统的 MapReduce 框架之所以运行速度缓慢,很重要的原因就是有向无环图的中间计算结果需要写入硬盘这样的稳定存储介质中来防止运行结果丢失。
每次调用中间计算结果都需要要进行一次硬盘的读取,反复对硬盘进行读写操作以及潜在的数据复制和序列化操作,大大提高了计算延迟。
一个可行的设想就是在分布式内存中,存储中间计算的结果,因为对内存的读写操作速度远快于硬盘。
RDD 就是基于分布式内存的数据抽象。它不仅支持基于工作集的应用,同时具有数据流模型的特点。
RDD 表示已被分区、不可变的,并能够被并行操作的数据集合。
RDD 有以下3个基本特性:分区、不可变和并行操作。
分区代表同一个 RDD 包含的数据被存储在系统的不同节点中,这也是它可以被并行处理的前提。
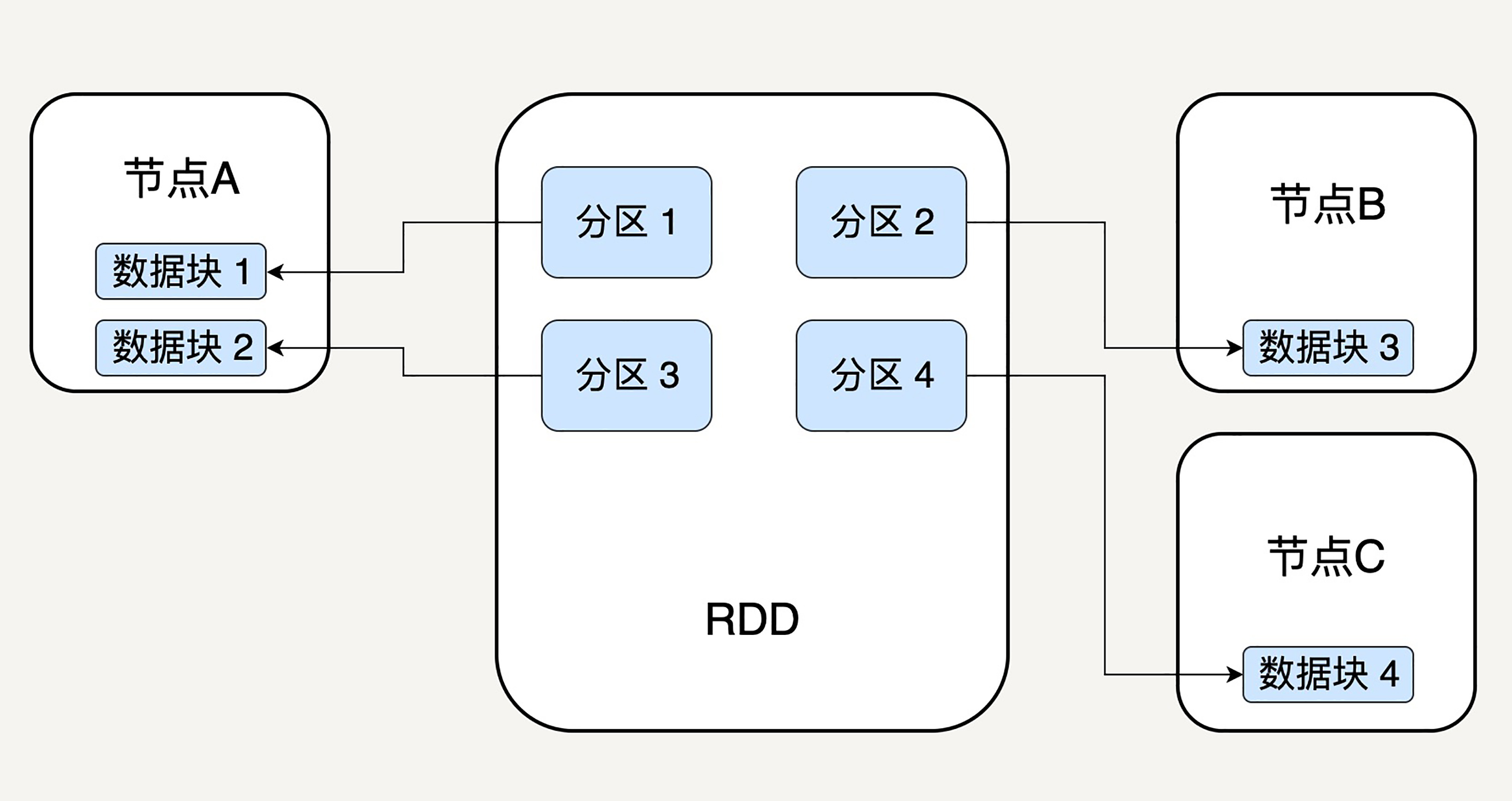
RDD 中的每个分区存有它在该 RDD 中的 index。通过 RDD 的 ID 和分区的 index 可以唯一确定对应数据块的编号,从而通过底层存储层的接口提取到数据。
在集群中,各个节点上的数据块存放在内存中,只有当内存没有空间时才会存入硬盘。这样可以最大化地减少硬盘读写的开销。
RDD 内部存储的数据是只读的,我们能修改并行计算单元的划分结构(例如通过 repartition 转换操作),也就是分区的数量。
不可变性代表每一个 RDD 都是只读的,它所包含的分区信息不可以被改变。
既然已有的 RDD 不可以被改变,我们只能对现有的 RDD 进行转换(Transformation)操作,得到新的 RDD 作为中间计算的结果。
对于代表中间结果的 RDD,我们只需要记住依赖关系。即只记录它是通过哪个 RDD 的哪些转换操作得来,而不用立刻去具体存储计算出的数据本身。
这样做有助于提升 Spark 的计算效率,同时可以快速错误恢复。
由于单个 RDD 的分区特性,使得它天然支持并行操作,即不同节点上的数据可以被分别处理,然后产生一个新的 RDD。
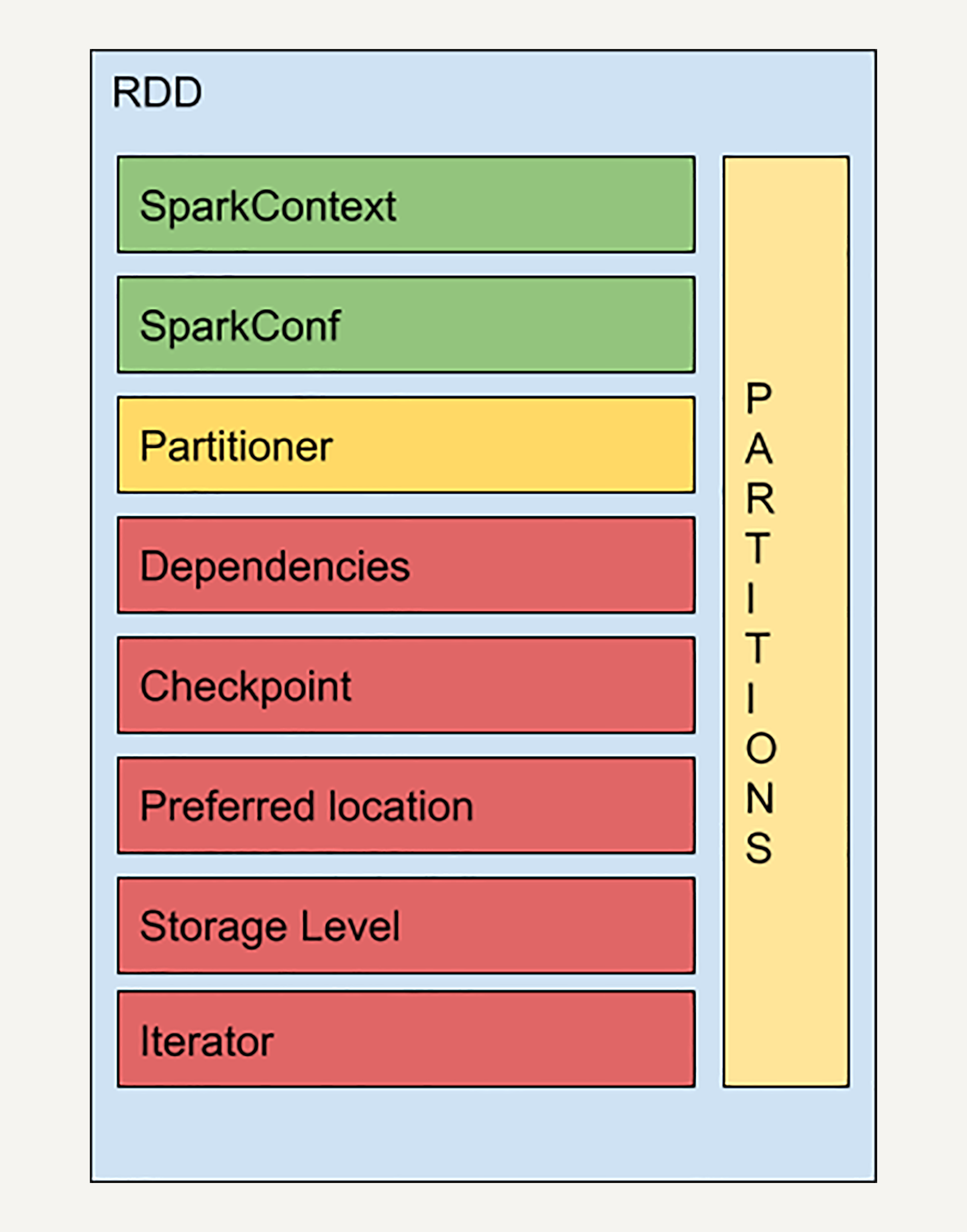
RDD 的基本特性是分区、不可变和并行计算。实际上 RDD 的结构非常复杂,让我们来看一个 RDD 的简易结构示意图:
-
SparkContext 是所有 Spark 功能的入口。它代表了与 Spark 节点的连接,可以用来创建 RDD 对象以及在节点中的广播变量等。一个线程只有一个 SparkContext。
-
SparkConf 是一些参数配置信息。
-
Partitions 代表 RDD 中数据的逻辑结构。每个 Partition 会映射到某个节点内存或硬盘的一个数据块。
-
Partitioner 决定了 RDD 的分区方式。目前有两种主流的分区方式:Hash partitioner 和 Range partitioner,Hash就是对数据的 Key 进行散列分区,Range 则是按照 Key 的排序进行均匀分区。我们也可以创建自定义的 Partitioner。
Dependencies 是 RDD 中最重要的组件之一。通过这个组件,Spark 不需要记录每个中间计算结果,因为每一步产生的 RDD 里都会存储它的依赖关系,即它是通过哪个 RDD 经过哪个转换操作得到的。
父 RDD 的分区和子 RDD 的分区之间是否是一对一的对应关系呢?Spark 支持两种依赖关系:窄依赖(Narrow Dependency)和宽依赖(Wide Dependency)。
窄依赖就是父 RDD 的分区可以一一对应到子 RDD 的分区;宽依赖就是父 RDD 的每个分区可以被多个子 RDD 的分区使用。
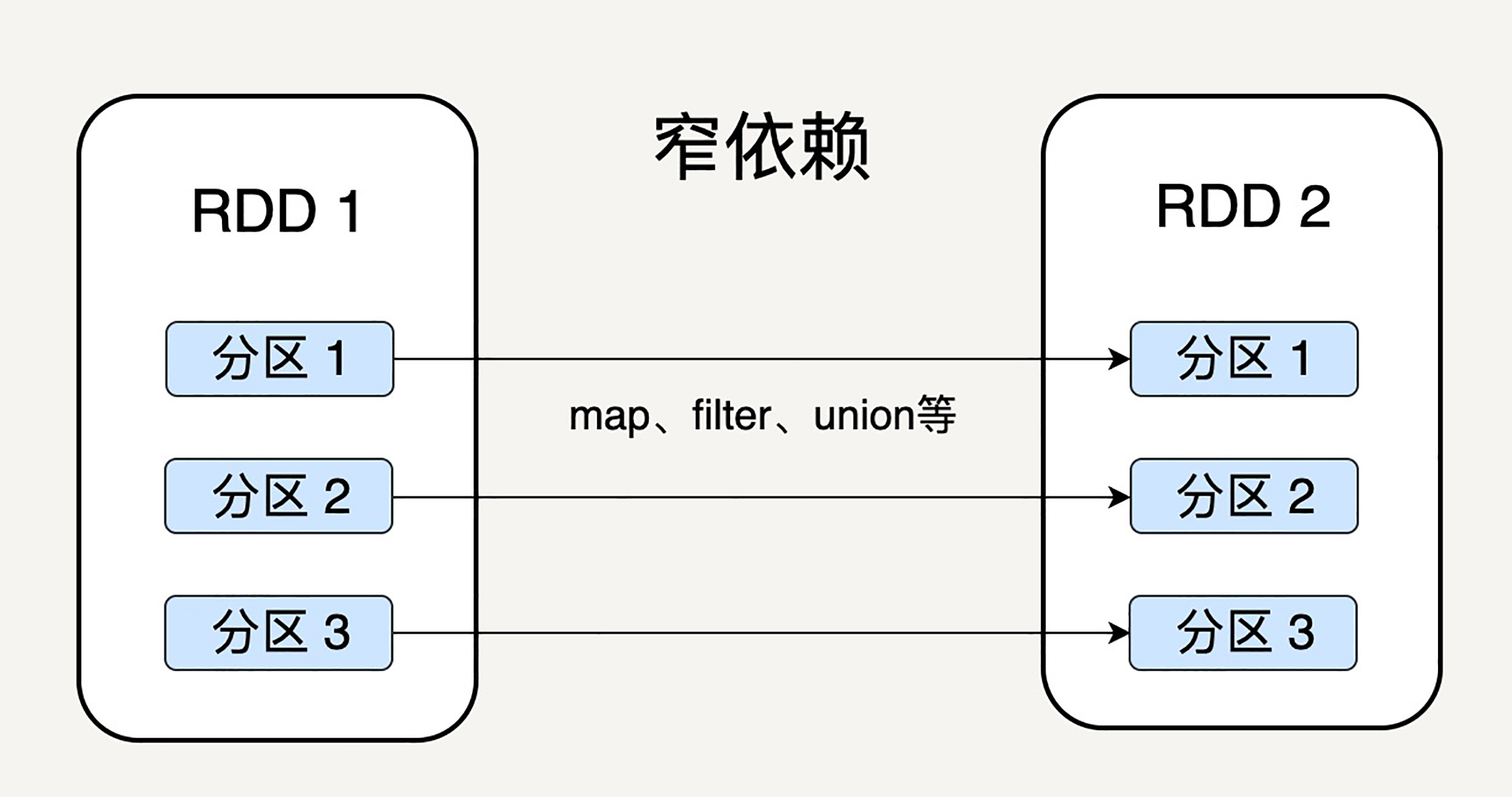
显然,窄依赖允许子 RDD 的每个分区可以被并行处理,而宽依赖则必须等父 RDD 的所有分区都被计算好之后才能开始处理。如上图所示,一些转换操作如 map、filter 会产生窄依赖关系,而 Join、groupBy 则会生成宽依赖关系。
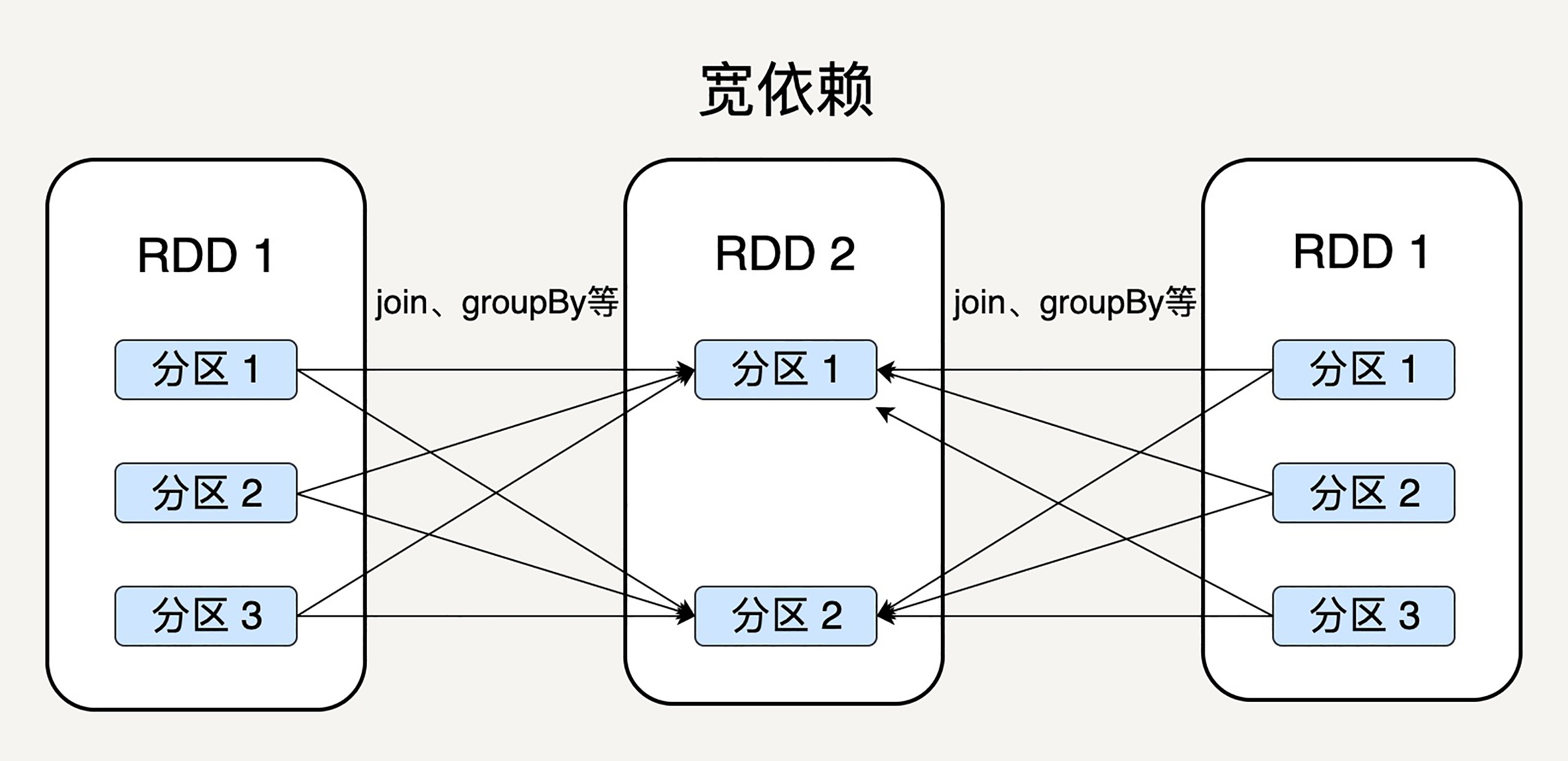
这很容易理解,因为 map 是将分区里的每一个元素通过计算转化为另一个元素,一个分区里的数据不会跑到两个不同的分区。
而 groupBy 则要将拥有所有分区里有相同 Key 的元素放到同一个目标分区,而每一个父分区都可能包含各种 Key 的元素,所以它可能被任意一个子分区所依赖。
窄依赖可以支持在同一个节点上链式执行多条命令,例如在执行了 map 后,紧接着执行 filter。
相反,宽依赖需要所有的父分区都是可用的,可能还需要调用类似 MapReduce 之类的操作进行跨节点传递。
从失败恢复的角度考虑,窄依赖的失败恢复更有效,因为它只需要重新计算丢失的父分区即可,而宽依赖牵涉到 RDD 各级的多个父分区。
弹性分布式数据集作为 Spark 的基本数据抽象,相较于 Hadoop/MapReduce 的数据模型而言,各方面都有很大的提升。
首先,它的数据可以尽可能地存在内存中,从而大大提高的数据处理的效率;
其次它是分区存储,所以天然支持并行处理;
而且它还存储了每一步骤计算结果之间的依赖关系,从而大大提升了数据容错性和错误恢复的正确率,使 Spark 更加可靠。
窄依赖是指父 RDD 的每一个分区都可以唯一对应子 RDD 中的分区,那么是否意味着子 RDD 中的一个分区只可以对应父 RDD 中的一个分区呢?如果子 RDD 的一个分区需要由父 RDD 中若干个分区计算得来,是否还算窄依赖?
对于思考题:
窄依赖就是父 RDD 的分区可以一一对应到子 RDD 的分区,宽依赖就是父 RDD 的每个分区可以被多个子 RDD 的分区使用。
这句话说明了,窄依赖的父RDD必须有一个对应的子RDD,也就是说父RDD的一个分区只能被子RDD一个分区使用,但是反过来子RDD的一个分区可以使用父RDD的多个分区。
第一个疑问,窄依赖子RDD的分区不一定只对应父RDD的一个分区,只要满足被子RDD分区利用的父RDD分区不被子RDD的其他分区利用就算窄依赖。
第二个疑问,其实上面已经做了回答,只有当子RDD分区依赖的父RDD分区不被其他子RDD分区依赖,这样的计算就是窄依赖,否则是宽依赖。
最后,总结以下,就是只有父RDD的分区被多个子RDD的分区利用的时候才是宽依赖,其他的情况就是窄依赖。
窄:一子多父,一子一父,宽:一父多子。