diff --git a/ydb/docs/en/core/concepts/_includes/datamodel/blockdevice.md b/ydb/docs/en/core/concepts/_includes/datamodel/blockdevice.md
deleted file mode 100644
index bb4dfd5c8887..000000000000
--- a/ydb/docs/en/core/concepts/_includes/datamodel/blockdevice.md
+++ /dev/null
@@ -1,4 +0,0 @@
-## Network block storage volume {#volume}
-
-{{ ydb-short-name }} can be used as a platform for creating a wide range of data storage and processing systems, for example, by implementing a [network block device](https://en.wikipedia.org/wiki/Network_block_device) on {{ ydb-short-name }}. Network block devices implement an interface for a local block device, as well as ensure fault-tolerance (through redundancy) and good scalability in terms of volume size and the number of input/output operations per unit of time. The downside of a network block device is that any input/output operation on such device requires network interaction, which might increase the latency of the network device compared to the local device. You can deploy a common file system on a network block device and/or run an application directly on the block device, such as a database management system.
-
diff --git a/ydb/docs/en/core/concepts/_includes/datamodel/dir.md b/ydb/docs/en/core/concepts/_includes/datamodel/dir.md
deleted file mode 100644
index 05138506ef34..000000000000
--- a/ydb/docs/en/core/concepts/_includes/datamodel/dir.md
+++ /dev/null
@@ -1,4 +0,0 @@
-## Directories {#dir}
-
-For convenience, the service supports creating directories like in a file system, meaning the entire database consists of a directory tree, while tables and other entities are in the leaves of this tree (similar to files in the file system). A directory can host multiple subdirectories and tables. The names of the entities they contain are unique.
-
diff --git a/ydb/docs/en/core/concepts/_includes/datamodel/intro.md b/ydb/docs/en/core/concepts/_includes/datamodel/intro.md
deleted file mode 100644
index 860fc10178c1..000000000000
--- a/ydb/docs/en/core/concepts/_includes/datamodel/intro.md
+++ /dev/null
@@ -1,4 +0,0 @@
-# Data model and schema
-
-This section describes the entities that {{ ydb-short-name }} uses within DBs. The {{ ydb-short-name }} core lets you flexibly implement various storage primitives, so new entities may appear in the future.
-
diff --git a/ydb/docs/en/core/concepts/_includes/datamodel/pq.md b/ydb/docs/en/core/concepts/_includes/datamodel/pq.md
deleted file mode 100644
index 1e469fbc9fcf..000000000000
--- a/ydb/docs/en/core/concepts/_includes/datamodel/pq.md
+++ /dev/null
@@ -1,4 +0,0 @@
-## Persistent queue {#persistent-queue}
-
-A persistent queue consists of one or more partitions, where each partition is a [FIFO](https://en.wikipedia.org/wiki/FIFO_(computing_and_electronics)) [message queue](https://en.wikipedia.org/wiki/Message_queue) ensuring reliable delivery between two or more components. Data messages have no type and are data blobs. Partitioning is a parallel processing tool that helps ensure high queue bandwidth. Mechanisms are provided to implement the "at least once" and the "exactly once" persistent queue delivery guarantees. A persistent queue in {{ ydb-short-name }} is similar to a topic in [Apache Kafka](https://en.wikipedia.org/wiki/Apache_Kafka).
-
diff --git a/ydb/docs/en/core/concepts/_includes/index/how_it_works.md b/ydb/docs/en/core/concepts/_includes/index/how_it_works.md
index 6e367f632015..fd8ec12a0f98 100644
--- a/ydb/docs/en/core/concepts/_includes/index/how_it_works.md
+++ b/ydb/docs/en/core/concepts/_includes/index/how_it_works.md
@@ -1,22 +1,22 @@
-## How it works?
+## How It Works?
-Fully explaining how YDB works in detail takes quite a while. Below you can review several key highlights and then continue exploring documentation to learn more.
+Fully explaining how YDB works in detail takes quite a while. Below you can review several key highlights and then continue exploring the documentation to learn more.
-### {{ ydb-short-name }} architecture {#ydb-architecture}
+### {{ ydb-short-name }} Architecture {#ydb-architecture}
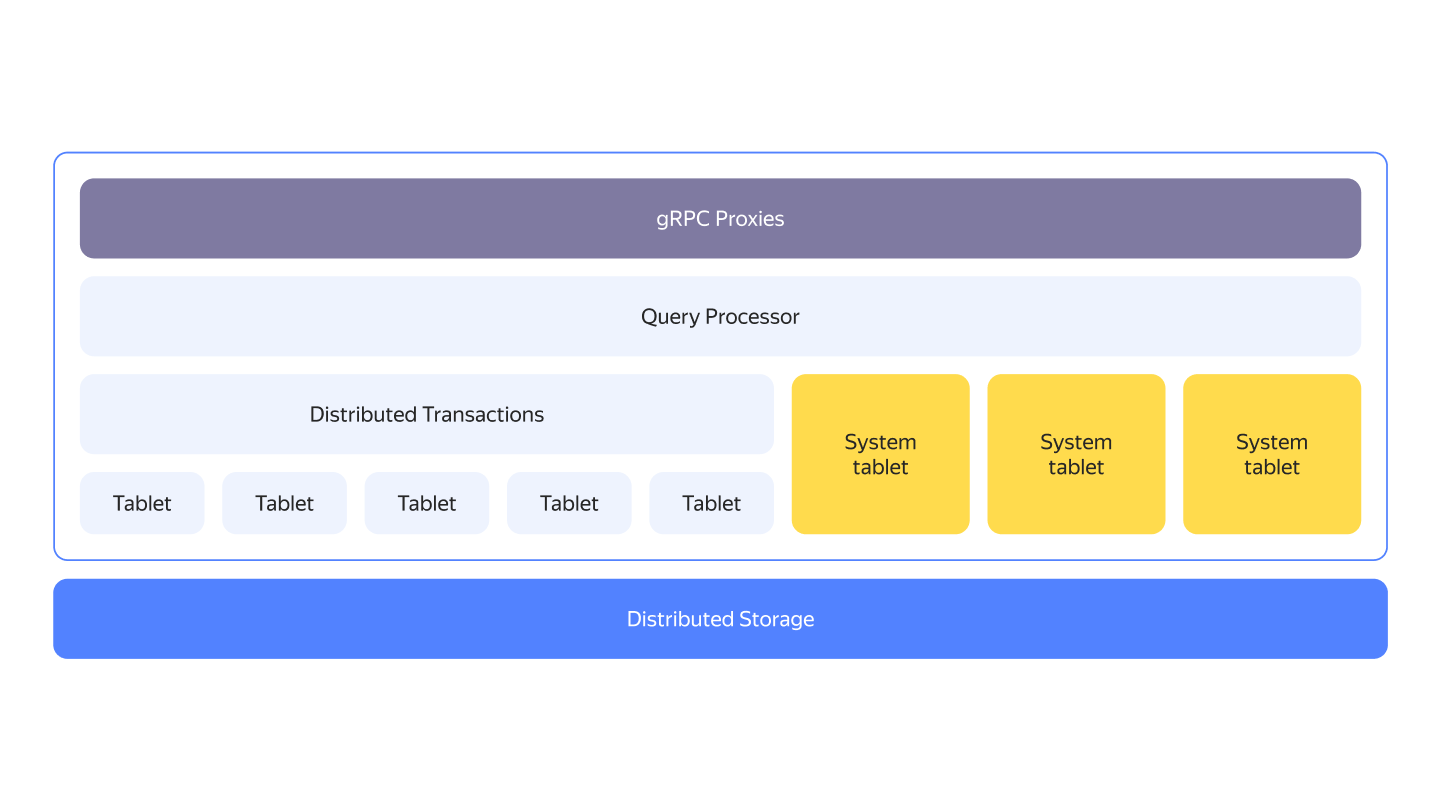
-{{ ydb-short-name }} clusters typically run on commodity hardware with shared-nothing architecture. If you look at {{ ydb-short-name }} from a bird's eye view, you'll see a layered architecture. The compute and storage layers are disaggregated, they can either run on separate sets of nodes or be co-located.
+{{ ydb-short-name }} clusters typically run on commodity hardware with a shared-nothing architecture. From a bird's eye view, {{ ydb-short-name }} exhibits a layered architecture. The compute and storage layers are disaggregated; they can either run on separate sets of nodes or be co-located.
-One of the key building blocks of {{ ydb-short-name }}'s compute layer is called a *tablet*. They are stateful logical components implementing various aspects of {{ ydb-short-name }}.
+One of the key building blocks of {{ ydb-short-name }}'s compute layer is called a *tablet*. Tablets are stateful logical components implementing various aspects of {{ ydb-short-name }}.
-The next level of detail of overall {{ ydb-short-name }} architecture is explained in the [{#T}](../../../contributor/general-schema.md) article.
+The next level of detail of the overall {{ ydb-short-name }} architecture is explained in the [{#T}](../../../contributor/general-schema.md) article.
### Hierarchy {#ydb-hierarchy}
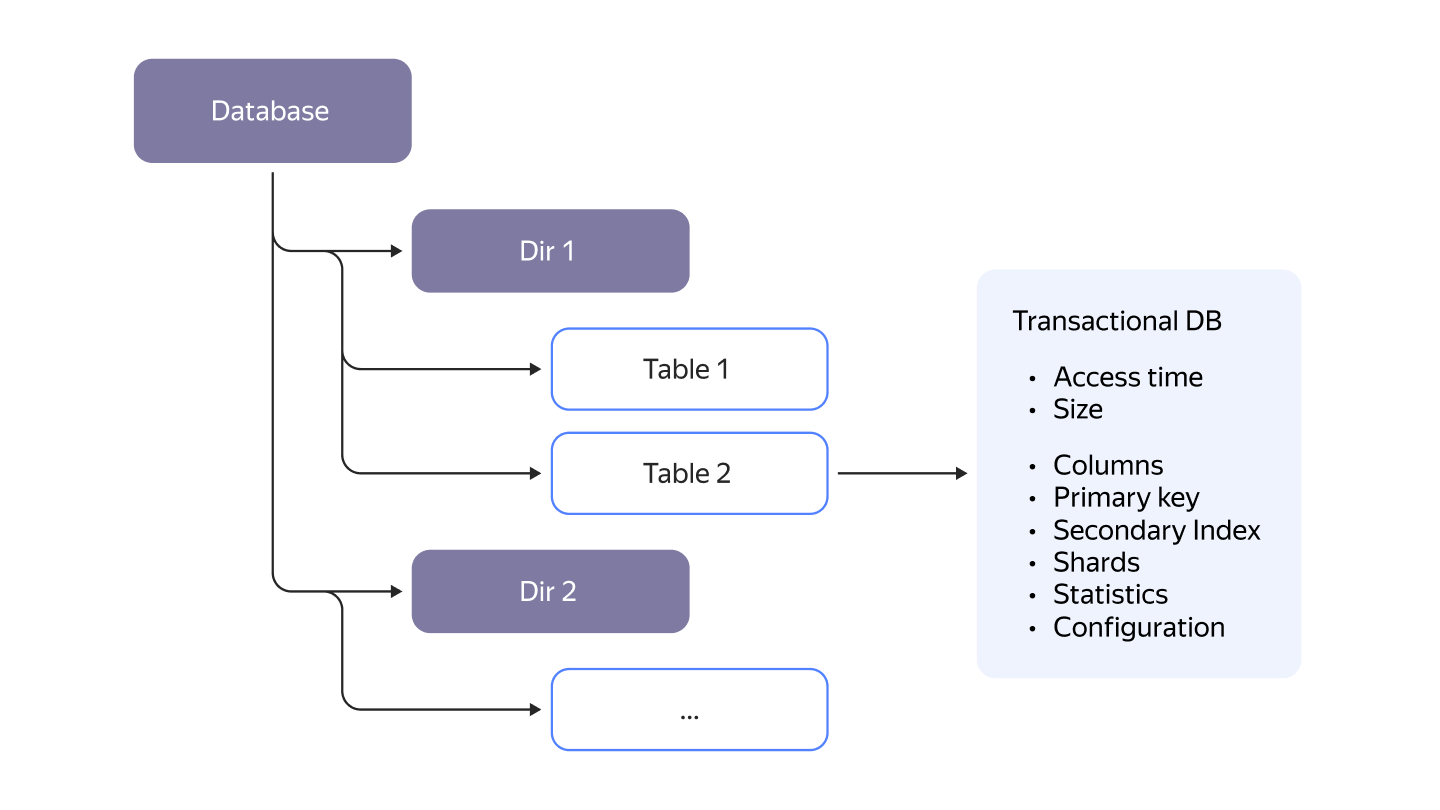
-From the user's perspective, everything inside {{ ydb-short-name }} is organized in a hierarchical structure using directories. It can have arbitrary depth depending on how you choose to organize your data and projects. Even though {{ ydb-short-name }} does not have a fixed hierarchy depth like in other SQL implementations, it will still feel familiar as this is exactly how any virtual filesystem looks like.
+From the user's perspective, everything inside {{ ydb-short-name }} is organized in a hierarchical structure using directories. It can have arbitrary depth depending on how you choose to organize your data and projects. Even though {{ ydb-short-name }} does not have a fixed hierarchy depth like in other SQL implementations, it will still feel familiar as this is exactly how any virtual filesystem looks.
### Table {#table}
@@ -27,7 +27,7 @@ From the user's perspective, everything inside {{ ydb-short-name }} is organized
* [Row-oriented tables](../../datamodel/table.md#row-tables) are designed for OLTP workloads.
* [Column-oriented tables](../../datamodel/table.md#column-tables) are designed for OLAP workloads.
-Logically, from the user’s perspective, both types of tables look the same. The main difference between row-oriented and column-oriented tables lies in how the data is physically stored. In row-oriented tables, the values of all columns in each row are stored together. In contrast, in column-oriented tables, each column is stored separately, meaning that cells from different rows are stored next to each other within the same column.
+Logically, from the user's perspective, both types of tables look the same. The main difference between row-oriented and column-oriented tables lies in how the data is physically stored. In row-oriented tables, the values of all columns in each row are stored together. In contrast, in column-oriented tables, each column is stored separately, meaning that cells from different rows are stored next to each other within the same column.
Regardless of the type, each table must have a primary key. Column-oriented tables can only have `NOT NULL` columns in primary keys. Table data is physically sorted by the primary key.
@@ -38,32 +38,32 @@ Partitioning works differently in row-oriented and column-oriented tables:
Each partition of a table is processed by a specific [tablet](../../glossary.md#tablets), called a [data shard](../../glossary.md#datashard) for row-oriented tables and a [column shard](../../glossary.md#columnshard) for column-oriented tables.
-#### Split by load {#split-by-load}
+#### Split by Load {#split-by-load}

-Data shards will automatically split into more ones as the load increases. They automatically merge back to the appropriate number when the peak load goes away.
+Data shards will automatically split into more as the load increases. They automatically merge back to the appropriate number when the peak load subsides.
-#### Split by size {#split-by-size}
+#### Split by Size {#split-by-size}
.png)
-Data shards also will automatically split when the data size increases. They automatically merge back if enough data will be deleted.
+Data shards will also automatically split when the data size increases. They automatically merge back if enough data is deleted.
-### Automatic balancing {#automatic-balancing}
+### Automatic Balancing {#automatic-balancing}
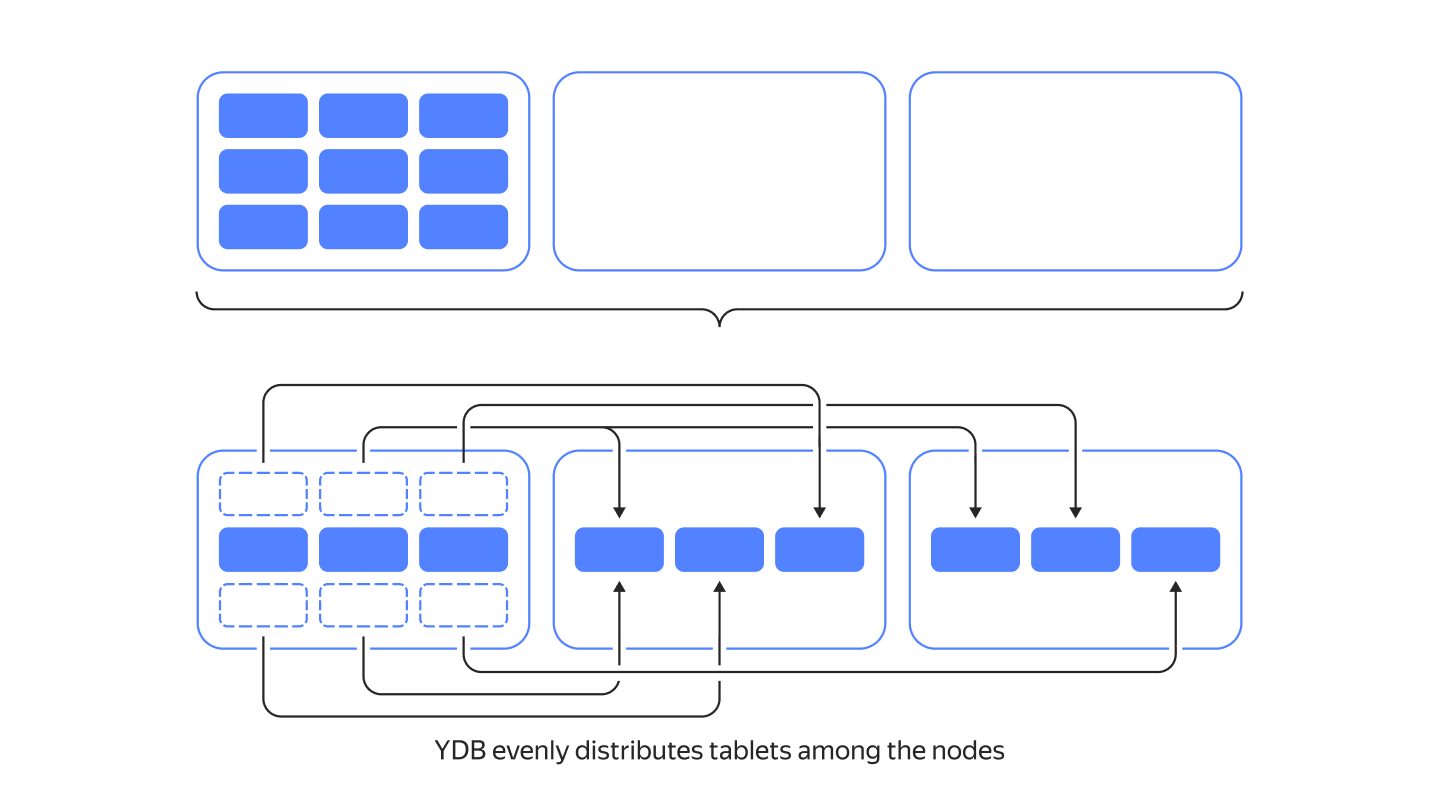
-{{ ydb-short-name }} evenly distributes tablets among available nodes. It moves heavily loaded tablets from overloaded nodes. CPU, Memory, and Network metrics are tracked to facilitate this.
+{{ ydb-short-name }} evenly distributes tablets among available nodes. It moves heavily loaded tablets from overloaded nodes. CPU, memory, and network metrics are tracked to facilitate this.
-### Distributed Storage internals {#ds-internals}
+### Distributed Storage Internals {#ds-internals}
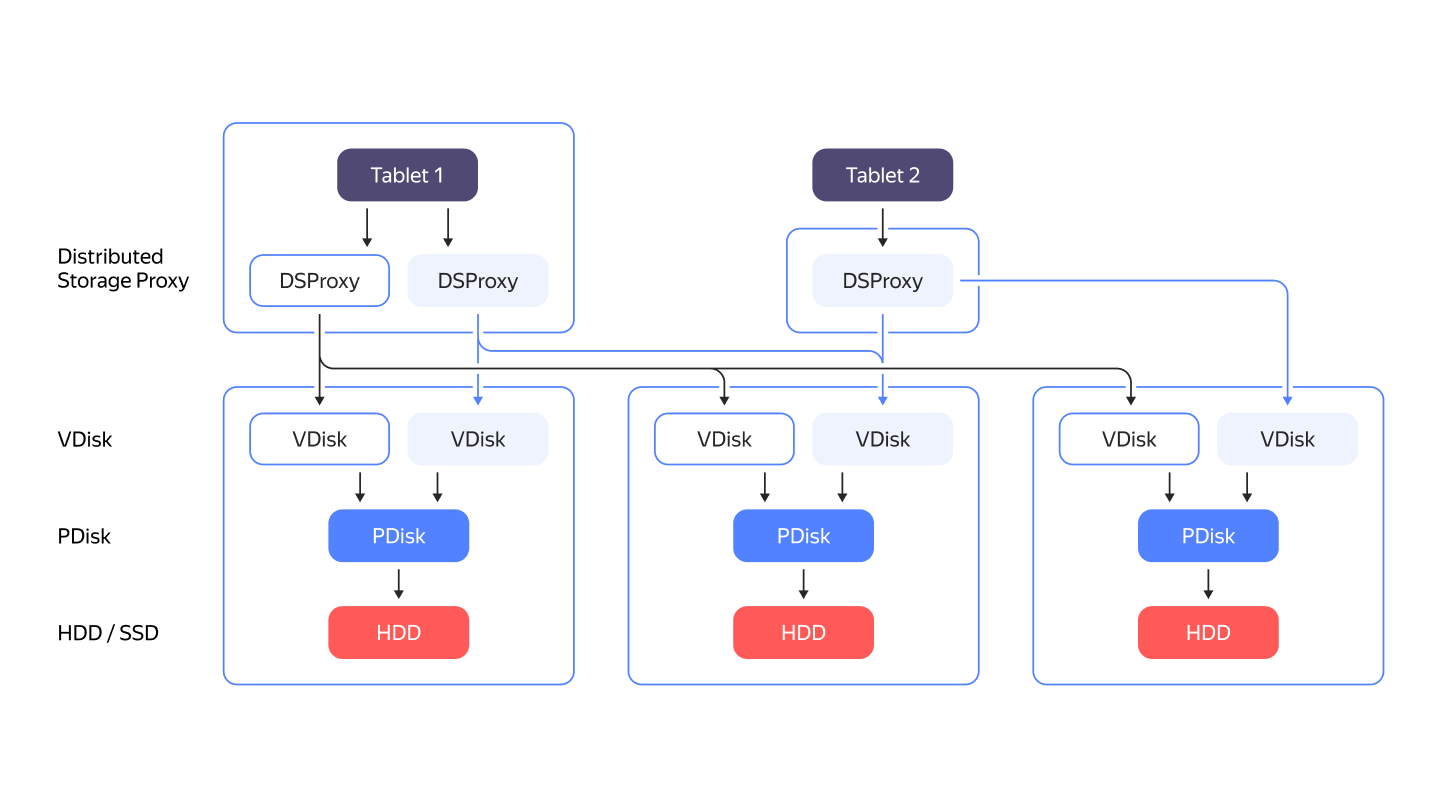
{{ ydb-short-name }} doesn't rely on any third-party filesystem. It stores data by directly working with disk drives as block devices. All major disk kinds are supported: NVMe, SSD, or HDD. The PDisk component is responsible for working with a specific block device. The abstraction layer above PDisk is called VDisk. There is a special component called DSProxy between a tablet and VDisk. DSProxy analyzes disk availability and characteristics and chooses which disks will handle a request and which won't.
-### Distributed Storage proxy (DSProxy) {#ds-proxy}
+### Distributed Storage Proxy (DSProxy) {#ds-proxy}
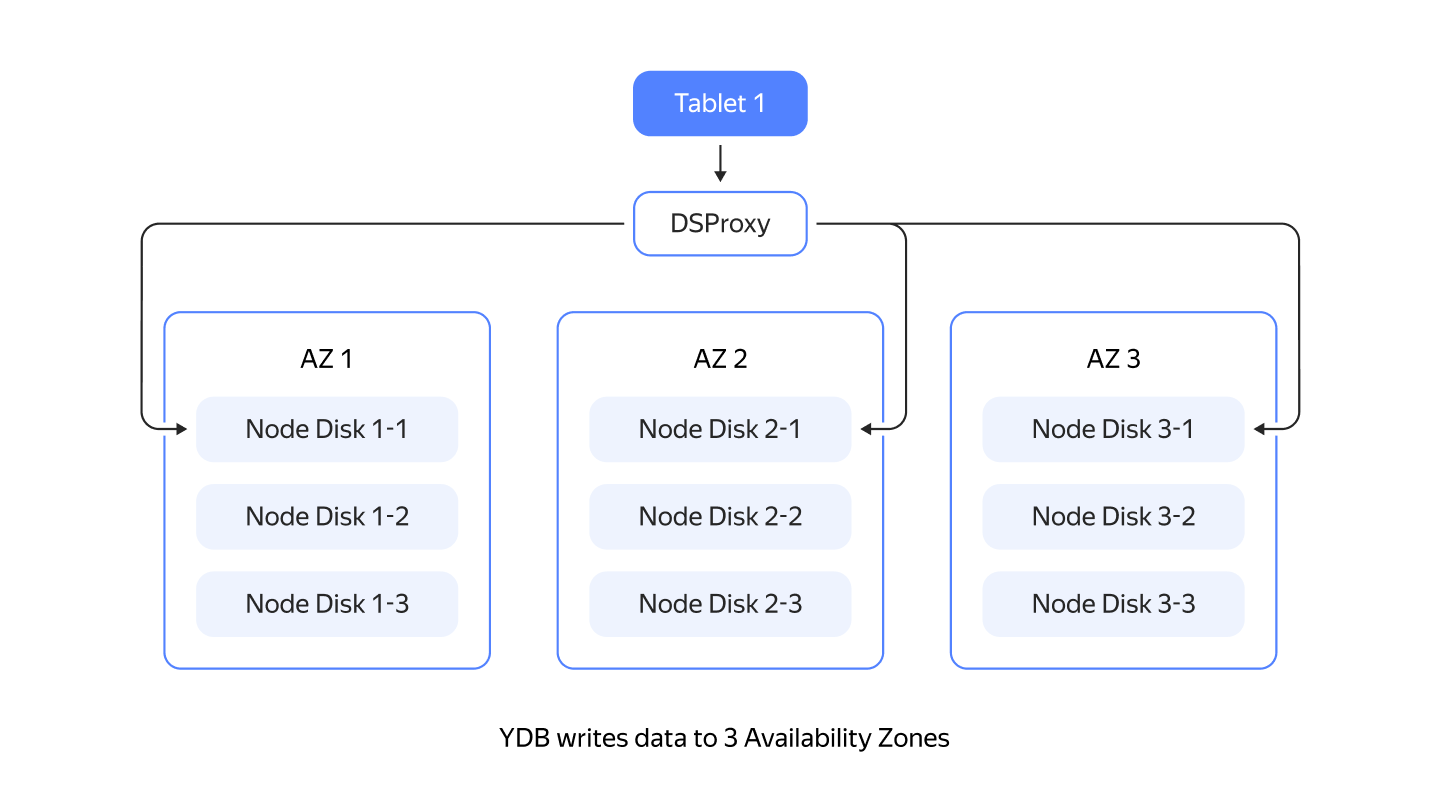
-A common fault-tolerant setup of {{ ydb-short-name }} spans 3 datacenters or availability zones (AZ). When {{ ydb-short-name }} writes data to 3 AZ, it doesn’t send requests to obviously bad disks and continues to operate without interruption even if one AZ and a disk in another AZ are lost.
\ No newline at end of file
+A common fault-tolerant setup of {{ ydb-short-name }} spans three datacenters or availability zones (AZ). When {{ ydb-short-name }} writes data to three AZs, it doesn't send requests to obviously bad disks and continues to operate without interruption even if one AZ and a disk in another AZ are lost.
\ No newline at end of file
diff --git a/ydb/docs/en/core/concepts/_includes/index/intro.md b/ydb/docs/en/core/concepts/_includes/index/intro.md
index ee7db6e9a005..cfd6d12f28fd 100644
--- a/ydb/docs/en/core/concepts/_includes/index/intro.md
+++ b/ydb/docs/en/core/concepts/_includes/index/intro.md
@@ -1,23 +1,23 @@
-# {{ ydb-short-name }} overview
+# {{ ydb-short-name }} Overview
-*{{ ydb-short-name }}* is a horizontally scalable distributed fault-tolerant DBMS. {{ ydb-short-name }} is designed for high performance with a typical server being capable of handling tens of thousands of queries per second. The system is designed to handle hundreds of petabytes of data. {{ ydb-short-name }} can operate in single data center and geo-distributed (cross data center) modes on a cluster of thousands of servers.
+*{{ ydb-short-name }}* is a horizontally scalable, distributed, fault-tolerant DBMS. It is designed for high performance, with a typical server capable of handling tens of thousands of queries per second. The system is designed to handle hundreds of petabytes of data. {{ ydb-short-name }} can operate in both single data center and geo-distributed (cross data center) modes on a cluster of thousands of servers.
{{ ydb-short-name }} provides:
-* [Strict consistency](https://en.wikipedia.org/wiki/Consistency_model#Strict_Consistency) which can be relaxed to increase performance.
-* Support for queries written in [YQL](../../../yql/reference/index.md) (an SQL dialect for working with big data).
+* [Strict consistency](https://en.wikipedia.org/wiki/Consistency_model#Strict_Consistency), which can be relaxed to increase performance.
+* Support for queries written in [YQL](../../../yql/reference/index.md), an SQL dialect for working with big data.
* Automatic data replication.
-* High availability with automatic failover in case a server, rack, or availability zone goes offline.
+* High availability with automatic failover if a server, rack, or availability zone goes offline.
* Automatic data partitioning as data or load grows.
-To interact with {{ ydb-short-name }}, you can use the [{{ ydb-short-name }} CLI](../../../reference/ydb-cli/index.md) and [SDK](../../../reference/ydb-sdk/index.md) fo C++, C#, Go, Java, Node.js, PHP, Python, and Rust.
+To interact with {{ ydb-short-name }}, you can use the [{{ ydb-short-name }} CLI](../../../reference/ydb-cli/index.md) and [SDK](../../../reference/ydb-sdk/index.md) for C++, C#, Go, Java, Node.js, PHP, Python, and Rust.
-{{ ydb-short-name }} supports a relational [data model](../../../concepts/datamodel/table.md) and manages [row-oriented](../../datamodel/table.md#row-oriented-tables) and [column-oriented](../../datamodel/table.md#column-oriented-tables) tables with a predefined schema. To make it easier to organize tables, directories can be created like in the file system. In addition to tables, {{ ydb-short-name }} supports [topics](../../topic.md) as an entity for storing unstructured messages and delivering them to multiple subscribers.
+{{ ydb-short-name }} supports a relational [data model](../../../concepts/datamodel/table.md) and manages [row-oriented](../../datamodel/table.md#row-oriented-tables) and [column-oriented](../../datamodel/table.md#column-oriented-tables) tables with a predefined schema. Directories can be created like in a file system to organize tables. In addition to tables, {{ ydb-short-name }} supports [topics](../../topic.md) for storing unstructured messages and delivering them to multiple subscribers.
-Database commands are mainly written in YQL, an SQL dialect. This gives the user a powerful and already familiar way to interact with the database.
+Database commands are mainly written in YQL, an SQL dialect, providing a powerful and familiar way to interact with the database.
-{{ ydb-short-name }} supports high-performance distributed [ACID](https://en.wikipedia.org/wiki/ACID_(computer_science)) transactions that may affect multiple records in different tables. It provides the serializable isolation level, which is the strictest transaction isolation. You can also reduce the level of isolation to raise performance.
+{{ ydb-short-name }} supports high-performance distributed [ACID](https://en.wikipedia.org/wiki/ACID_(computer_science)) transactions that may affect multiple records in different tables. It provides the serializable isolation level, the strictest transaction isolation, with the option to reduce the isolation level to enhance performance.
-{{ ydb-short-name }} natively supports different processing options, such as [OLTP](https://en.wikipedia.org/wiki/Online_transaction_processing) and [OLAP](https://en.wikipedia.org/wiki/Online_analytical_processing). The current version offers limited analytical query support. This is why we can say that {{ ydb-short-name }} is currently an OLTP database.
+{{ ydb-short-name }} natively supports different processing options, such as [OLTP](https://en.wikipedia.org/wiki/Online_transaction_processing) and [OLAP](https://en.wikipedia.org/wiki/Online_analytical_processing). The current version offers limited analytical query support, which is why {{ ydb-short-name }} is currently considered an OLTP database.
-{{ ydb-short-name }} is an open-source system. The {{ ydb-short-name }} source code is available under [Apache License 2.0](https://www.apache.org/licenses/LICENSE-2.0). Client applications interact with {{ ydb-short-name }} based on [gRPC](https://grpc.io/) that has an open specification. It allows implementing an SDK for any programming language.
+{{ ydb-short-name }} is an open-source system. The source code is available under the [Apache License 2.0](https://www.apache.org/licenses/LICENSE-2.0). Client applications interact with {{ ydb-short-name }} based on [gRPC](https://grpc.io/), which has an open specification, allowing for SDK implementation in any programming language.
diff --git a/ydb/docs/en/core/concepts/_includes/index/when_use.md b/ydb/docs/en/core/concepts/_includes/index/when_use.md
index 2c1402666f08..06ff1f3a683f 100644
--- a/ydb/docs/en/core/concepts/_includes/index/when_use.md
+++ b/ydb/docs/en/core/concepts/_includes/index/when_use.md
@@ -1,4 +1,4 @@
-## Use cases {#use-cases}
+## Use Cases {#use-cases}
{{ ydb-short-name }} can be used as an alternative solution in the following cases:
diff --git a/ydb/docs/en/core/concepts/_includes/limits-ydb.md b/ydb/docs/en/core/concepts/_includes/limits-ydb.md
index 287f32aa8017..e6ab3959b4a5 100644
--- a/ydb/docs/en/core/concepts/_includes/limits-ydb.md
+++ b/ydb/docs/en/core/concepts/_includes/limits-ydb.md
@@ -1,8 +1,8 @@
-# Database limits
+# Database Limits
This section describes the parameters of limits set in {{ ydb-short-name }}.
-## Schema object limits {#schema-object}
+## Schema Object Limits {#schema-object}
The table below shows the limits that apply to schema objects: tables, databases, and columns. The "Object" column specifies the type of schema object that the limit applies to.
The "Error type" column shows the status that the query ends with if an error occurs. For more information about statuses, see [Error handling in the API](../../reference/ydb-sdk/error_handling.md).
@@ -12,34 +12,34 @@ The "Error type" column shows the status that the query ends with if an error oc
| Database | Maximum path depth | 32 | Maximum number of nested path elements (directories, tables). | MaxDepth | SCHEME_ERROR |
| Database | Maximum number of paths (schema objects) | 10,000 | Maximum number of path elements (directories, tables) in a database. | MaxPaths | GENERIC_ERROR |
| Database | Maximum number of tablets | 200,000 | Maximum number of tablets (table shards and system tablets) that can run in the database. An error is returned if a query to create, copy, or update a table exceeds this limit. When a database reaches the maximum number of tablets, no automatic table sharding takes place. | MaxShards | GENERIC_ERROR |
-| Database | Maximum object name length | 255 | Limits the number of characters in the name of a schema object, such as a directory or a table | MaxPathElementLength | SCHEME_ERROR |
+| Database | Maximum object name length | 255 | Limits the number of characters in the name of a schema object, such as a directory or a table. | MaxPathElementLength | SCHEME_ERROR |
| Database | Maximum ACL size | 10 KB | Maximum total size of all access control rules that can be saved for the schema object in question. | MaxAclBytesSize | GENERIC_ERROR |
| Directory | Maximum number of objects | 100,000 | Maximum number of tables and child directories created in a directory. | MaxChildrenInDir | SCHEME_ERROR |
| Table | Maximum number of table shards | 35,000 | Maximum number of table shards. | MaxShardsInPath | GENERIC_ERROR |
| Table | Maximum number of columns | 200 | Limits the total number of columns in a table. | MaxTableColumns | GENERIC_ERROR |
-| Table | Maximum column name length | 255 | Limits the number of characters in a column name | MaxTableColumnNameLength | GENERIC_ERROR |
+| Table | Maximum column name length | 255 | Limits the number of characters in a column name. | MaxTableColumnNameLength | GENERIC_ERROR |
| Table | Maximum number of columns in a primary key | 20 | Each table must have a primary key. The number of columns in the primary key may not exceed this limit. | MaxTableKeyColumns | GENERIC_ERROR |
| Table | Maximum number of indexes | 20 | Maximum number of indexes other than the primary key index that can be created in a table. | MaxTableIndices | GENERIC_ERROR |
| Table | Maximum number of followers | 3 | Maximum number of read-only replicas that can be specified when creating a table with followers. | MaxFollowersCount | GENERIC_ERROR |
-| Table | Maximum number of tables to copy | 10,000 | Limit on the size of the table list for persistent table copy operations | MaxConsistentCopyTargets | GENERIC_ERROR |
+| Table | Maximum number of tables to copy | 10,000 | Limit on the size of the table list for persistent table copy operations. | MaxConsistentCopyTargets | GENERIC_ERROR |
{wide-content}
-## Size limits for stored data {#data-size}
+## Size Limits for Stored Data {#data-size}
| Parameter | Value | Error type |
| :--- | :--- | :---: |
| Maximum total size of all columns in a primary key | 1 MB | GENERIC_ERROR |
| Maximum size of a string column value | 16 MB | GENERIC_ERROR |
-## Analytical table limits
+## Analytical Table Limits
| Parameter | Value |
:--- | :---
| Maximum row size | 8 MB |
| Maximum size of an inserted data block | 8 MB |
-## Limits on query execution {#query}
+## Limits on Query Execution {#query}
The table below lists the limits that apply to query execution.
@@ -50,7 +50,7 @@ The table below lists the limits that apply to query execution.
| Maximum query text length | 10 KB | The maximum allowable length of YQL query text. | BAD_REQUEST |
| Maximum size of parameter values | 50 MB | The maximum total size of parameters passed when executing a previously prepared query. | BAD_REQUEST |
-{% cut "Legacy limits" %}
+{% cut "Legacy Limits" %}
In previous versions of {{ ydb-short-name }}, queries were typically executed using an API called "Table Service". This API had the following limitations, which have been addressed by replacing it with a new API called "Query Service".
@@ -61,7 +61,7 @@ In previous versions of {{ ydb-short-name }}, queries were typically executed us
{% endcut %}
-## Topic limits {#topic}
+## Topic Limits {#topic}
| Parameter | Value |
| :--- | :--- |
diff --git a/ydb/docs/en/core/concepts/_includes/scan_query.md b/ydb/docs/en/core/concepts/_includes/scan_query.md
index 018e5b527b49..3dfc775fad5c 100644
--- a/ydb/docs/en/core/concepts/_includes/scan_query.md
+++ b/ydb/docs/en/core/concepts/_includes/scan_query.md
@@ -1,4 +1,4 @@
-# Scan queries in {{ ydb-short-name }}
+# Scan Queries in {{ ydb-short-name }}
Scan Queries is a separate data access interface designed primarily for running analytical ad hoc queries against a DB.
@@ -6,7 +6,7 @@ This method of executing queries has the following unique features:
* Only *Read-Only* queries.
* In `SERIALIZABLE_RW` mode, a data snapshot is taken and then used for all subsequent operations. As a result, the impact on OLTP transactions is minimal (only taking a snapshot).
-* The output of a query is a data stream ([grpc stream](https://grpc.io/docs/what-is-grpc/core-concepts/)). This means scan queries have no limit on the number of rows in the result.
+* The output of a query is a data stream ([gRPC stream](https://grpc.io/docs/what-is-grpc/core-concepts/)). This means scan queries have no limit on the number of rows in the result.
* Due to the high overhead, it is only suitable for ad hoc queries.
{% note info %}
@@ -19,7 +19,7 @@ Scan queries cannot currently be considered an effective solution for running OL
* The query duration is limited to 5 minutes.
* Many operations (including sorting) are performed entirely in memory, which may lead to resource shortage errors when running complex queries.
-* A single strategy is currently in use for joins: *MapJoin* (a.k.a. *Broadcast Join*) where the "right" table is converted to a map; and therefore, must be no more than single gigabytes in size.
+* A single strategy is currently in use for joins: *MapJoin* (a.k.a. *Broadcast Join*) where the "right" table is converted to a map; and therefore, must be no more than a few gigabytes in size.
* Prepared form isn't supported, so for each call, a query is compiled.
* There is no optimization for point reads or reading small ranges of data.
* The SDK doesn't support automatic retry.
@@ -31,7 +31,7 @@ Despite the fact that *Scan Queries* obviously don't interfere with the executio
{% endnote %}
-## How do I use it? {#how-use}
+## How Do I Use It? {#how-use}
Like other types of queries, *Scan Queries* are available via the {% if link-console-main %}[management console]({{ link-console-main }}) (the query must specify `PRAGMA Kikimr.ScanQuery = "true";`),{% endif %} [CLI](../../reference/ydb-cli/commands/scan-query.md), and [SDK](../../reference/ydb-sdk/index.md).
@@ -39,7 +39,7 @@ Like other types of queries, *Scan Queries* are available via the {% if link-con
### C++ SDK {#cpp}
-To run a query using *Scan Queries*, use 2 methods from the `Ydb::TTableClient` class:
+To run a query using *Scan Queries*, use two methods from the `Ydb::TTableClient` class:
```cpp
class TTableClient {
diff --git a/ydb/docs/en/core/concepts/_includes/secondary_indexes.md b/ydb/docs/en/core/concepts/_includes/secondary_indexes.md
index 4419e61f1ea7..33df27804294 100644
--- a/ydb/docs/en/core/concepts/_includes/secondary_indexes.md
+++ b/ydb/docs/en/core/concepts/_includes/secondary_indexes.md
@@ -1,4 +1,4 @@
-# Secondary indexes
+# Secondary Indexes
{{ ydb-short-name }} automatically creates a primary key index, which is why selection by primary key is always efficient, affecting only the rows needed. Selections by criteria applied to one or more non-key columns typically result in a full table scan. To make these selections efficient, use _secondary indexes_.
@@ -9,35 +9,35 @@ The current version of {{ ydb-short-name }} implements _synchronous_ and _asynch
When a user sends an SQL query to insert, modify, or delete data, the database transparently generates commands to modify the index table. A table may have multiple secondary indexes. An index may include multiple columns, and the sequence of columns in an index matters. A single column may be included in multiple indexes. In addition to the specified columns, every index implicitly stores the table primary key columns to enable navigation from an index record to the table row.
-## Synchronous secondary index {#sync}
+## Synchronous Secondary Index {#sync}
A synchronous index is updated simultaneously with the table that it indexes. This index ensures [strict consistency](https://en.wikipedia.org/wiki/Consistency_model) through [distributed transactions](../transactions.md#distributed-tx). While reads and blind writes to a table with no index can be performed without a planning stage, significantly reducing delays, such optimization is impossible when writing data to a table with a synchronous index.
-## Asynchronous secondary index {#async}
+## Asynchronous Secondary Index {#async}
Unlike a synchronous index, an asynchronous index doesn't use distributed transactions. Instead, it receives changes from an indexed table in the background. Write transactions to a table using this index are performed with no planning overheads due to reduced guarantees: an asynchronous index provides [eventual consistency](https://en.wikipedia.org/wiki/Eventual_consistency), but no strict consistency. You can only use asynchronous indexes in read transactions in [Stale Read Only](transactions.md#modes) mode.
-## Covering secondary index {#covering}
+## Covering Secondary Index {#covering}
You can copy the contents of columns into a covering index. This eliminates the need to read data from the main table when performing reads by index and significantly reduces delays. At the same time, such denormalization leads to increased usage of disk space and may slow down inserts and updates due to the need for additional data copying.
-## Unique secondary index {#unique}
+## Unique Secondary Index {#unique}
This type of index enforces unique constraint behavior and, like other indexes, allows efficient point lookup queries. {{ ydb-short-name }} uses it to perform additional checks, ensuring that each distinct value in the indexed column set appears in the table no more than once. If a modifying query violates the constraint, it will be aborted with a `PRECONDITION_FAILED` status. Therefore, client code must be prepared to handle this status.
-A unique secondary index is a synchronous index, so the update process is the same as in the [Synchronous secondary index](#sync) section described above from a transaction perspective.
+A unique secondary index is a synchronous index, so the update process is the same as in the [Synchronous Secondary Index](#sync) section described above from a transaction perspective.
### Limitations
Currently, a unique index cannot be added to an existing table.
-## Vector index
+## Vector Index
[Vector Index](vector_indexes.md) is a special type of secondary index.
Unlike secondary indexes, which optimize equality or range searches, vector indexes allow similarity searches based on distance or similarity functions.
-## Creating a secondary index online {#index-add}
+### Creating a Secondary Index Online {#index-add}
{{ ydb-short-name }} lets you create new and delete existing secondary indexes without stopping the service. For a single table, you can only create one index at a time.
@@ -45,15 +45,15 @@ Online index creation consists of the following steps:
1. Taking a snapshot of a data table and creating an index table marked that writes are available.
- After this step, write transactions are distributed, writing to the main table and the index, respectively. The index is not yet available to the user.
+ After this step, write transactions are distributed, writing to the main table and the index, respectively. The index is not yet available to the user.
1. Reading the snapshot of the main table and writing data to the index.
- "Writes to the past" are implemented: situations where data updates in step 1 change the data written in step 2 are resolved.
+ "Writes to the past" are implemented: situations where data updates in step 1 change the data written in step 2 are resolved.
1. Publishing the results and deleting the snapshot.
- The index is ready to use.
+ The index is ready to use.
Possible impact on user transactions:
@@ -64,7 +64,7 @@ The rate of data writes is selected to minimize their impact on user transaction
Creating an index is an asynchronous operation. If the client-server connection is interrupted after the operation has started, index building continues. You can manage asynchronous operations using the {{ ydb-short-name }} CLI.
-## Creating and deleting secondary indexes {#ddl}
+## Creating and Deleting Secondary Indexes {#ddl}
A secondary index can be:
@@ -73,6 +73,6 @@ A secondary index can be:
- Deleted from an existing table with the YQL [`ALTER TABLE`](../../yql/reference/syntax/alter_table/index.md) statement or the YDB CLI [`table index drop`](../../reference/ydb-cli/commands/secondary_index.md#drop) command.
- Deleted together with the table using the YQL [`DROP TABLE`](../../yql/reference/syntax/drop_table.md) statement or the YDB CLI `table drop` command.
-## Using secondary indexes {#use}
+## Using Secondary Indexes {#use}
For detailed information on using secondary indexes in applications, refer to the [relevant article](../../dev/secondary-indexes.md) in the documentation section for developers.
diff --git a/ydb/docs/en/core/concepts/_includes/transactions.md b/ydb/docs/en/core/concepts/_includes/transactions.md
index 1e1d08830b3b..084cc3d919ae 100644
--- a/ydb/docs/en/core/concepts/_includes/transactions.md
+++ b/ydb/docs/en/core/concepts/_includes/transactions.md
@@ -1,12 +1,12 @@
-# {{ ydb-short-name }} transactions and queries
+# {{ ydb-short-name }} Transactions and Queries
This section describes the specifics of YQL implementation for {{ ydb-short-name }} transactions.
-## Query language {#query-language}
+## Query Language {#query-language}
The main tool for creating, modifying, and managing data in {{ ydb-short-name }} is a declarative query language called YQL. YQL is an SQL dialect that can be considered a database interaction standard. {{ ydb-short-name }} also supports a set of special RPCs useful in managing a tree schema or a cluster, for instance.
-## Transaction modes {#modes}
+## Transaction Modes {#modes}
By default, {{ ydb-short-name }} transactions are executed in *Serializable* mode. It provides the strictest [isolation level](https://en.wikipedia.org/wiki/Isolation_(database_systems)#Serializable) for custom transactions. This mode guarantees that the result of successful parallel transactions is equivalent to their serial execution, and there are no [read anomalies](https://en.wikipedia.org/wiki/Isolation_(database_systems)#Read_phenomena) for successful transactions.
@@ -22,7 +22,7 @@ If consistency or freshness requirement for data read by a transaction can be re
The transaction execution mode is specified in its settings when creating the transaction. See the examples for the {{ ydb-short-name }} SDK in the [{#T}](../../recipes/ydb-sdk/tx-control.md).
-## YQL language {#language-yql}
+## YQL Language {#language-yql}
Statements implemented in YQL can be divided into two classes: [Data Definition Language (DDL)](https://en.wikipedia.org/wiki/Data_definition_language) and [Data Manipulation Language (DML)](https://en.wikipedia.org/wiki/Data_manipulation_language).
@@ -31,7 +31,7 @@ For more information about supported YQL constructs, see the [YQL documentation]
Listed below are the features and limitations of YQL support in {{ ydb-short-name }}, which might not be obvious at first glance and are worth noting:
* Multi-statement transactions (transactions made up of a sequence of YQL statements) are supported. Transactions may interact with client software, or in other words, client interactions with the database might look as follows: `BEGIN; make a SELECT; analyze the SELECT results on the client side; ...; make an UPDATE; COMMIT`. We should note that if the transaction body is fully formed before accessing the database, it will be processed more efficiently.
-* {{ ydb-short-name }} does not support transactions that combine DDL and DML queries. The conventional [ACID]{% if lang == "en" %}(https://en.wikipedia.org/wiki/ACID){% endif %}{% if lang == "ru" %}(https://ru.wikipedia.org/wiki/ACID){% endif %} notion of a transactions is applicable specifically to DML queries, that is, queries that change data. DDL queries must be idempotent, meaning repeatable if an error occurs. If you need to manipulate a schema, each manipulation is transactional, while a set of manipulations is not.
+* {{ ydb-short-name }} does not support transactions that combine DDL and DML queries. The conventional [ACID](https://en.wikipedia.org/wiki/ACID) notion of a transaction is applicable specifically to DML queries, that is, queries that change data. DDL queries must be idempotent, meaning repeatable if an error occurs. If you need to manipulate a schema, each manipulation is transactional, while a set of manipulations is not.
* YQL implementation used in {{ ydb-short-name }} employs the [Optimistic Concurrency Control](https://en.wikipedia.org/wiki/Optimistic_concurrency_control) mechanism. If an entity is affected during a transaction, optimistic blocking is applied. When the transaction is complete, the mechanism verifies that the locks have not been invalidated. For the user, locking optimism means that when transactions are competing with one another, the one that finishes first wins. Competing transactions fail with the `Transaction locks invalidated` error.
* All changes made during the transaction accumulate in the database server memory and are applied when the transaction completes. If the locks are not invalidated, all the changes accumulated are committed atomically; if at least one lock is invalidated, none of the changes are committed. The above model involves certain restrictions: changes made by a single transaction must fit inside the available memory.
@@ -47,7 +47,7 @@ For efficient execution, a transaction should be formed so that the first part o
For more information about YQL support in {{ ydb-short-name }}, see the [YQL documentation](../../yql/reference/index.md).
-## Distributed transactions {#distributed-tx}
+## Distributed Transactions {#distributed-tx}
A database [table](../datamodel/table.md) in {{ ydb-short-name }} can be sharded by the range of the primary key values. Different table shards can be served by different distributed database servers (including ones in different locations). They can also move independently between servers to enable rebalancing or ensure shard operability if servers or network equipment goes offline.
@@ -55,7 +55,7 @@ A [topic](../topic.md) in {{ ydb-short-name }} can be sharded into several parti
{{ ydb-short-name }} supports distributed transactions. Distributed transactions are transactions that affect more than one shard of one or more tables and topics. They require more resources and take more time. While point reads and writes may take up to 10 ms in the 99th percentile, distributed transactions typically take from 20 to 500 ms.
-## Transactions with topics and tables {#topic-table-transactions}
+## Transactions with Topics and Tables {#topic-table-transactions}
{{ ydb-short-name }} supports transactions involving [row-oriented tables](../glossary.md#row-oriented-table) and/or [topics](../glossary.md#topic). This makes it possible to transactionally transfer data from tables to topics and vice versa, as well as between topics. This ensures that data is neither lost nor duplicated in case of a network outage or other issues. This enables the implementation of the transactional outbox pattern within {{ ydb-short-name }}.
diff --git a/ydb/docs/en/core/concepts/_includes/ttl.md b/ydb/docs/en/core/concepts/_includes/ttl.md
index 63cc21908fd8..bed7ae216836 100644
--- a/ydb/docs/en/core/concepts/_includes/ttl.md
+++ b/ydb/docs/en/core/concepts/_includes/ttl.md
@@ -1,8 +1,8 @@
-# Time to Live (TTL) and eviction to external storage
+# Time to Live (TTL) and Eviction to External Storage
This section describes how the TTL mechanism works and what its limits are.
-## How it works {#how-it-works}
+## How It Works {#how-it-works}
The table's TTL is a sequence of storage tiers. Each tier contains an expression (TTL expression) and an action. When the expression is triggered, that tier is assigned to the row. When a tier is assigned to a row, the specified action is automatically performed: moving the row to external storage or deleting it. External storage is represented by the [external data source](../datamodel/external_data_source.md) object.
@@ -46,7 +46,7 @@ The *BRO* has the following properties:
* `Uint64`.
* `DyNumber`.
-* The value in the TTL column with a numeric type (`Uint32`, `Uint64`, or `DyNumber`) is interpreted as a [Unix time]{% if lang == "en" %}(https://en.wikipedia.org/wiki/Unix_time){% endif %}{% if lang == "ru" %}(https://ru.wikipedia.org/wiki/Unix-время){% endif %} value. The following units are supported (set in the TTL settings):
+* The value in the TTL column with a numeric type (`Uint32`, `Uint64`, or `DyNumber`) is interpreted as a [Unix time](https://en.wikipedia.org/wiki/Unix_time) value. The following units are supported (set in the TTL settings):
* Seconds.
* Milliseconds.
diff --git a/ydb/docs/en/core/concepts/async-replication.md b/ydb/docs/en/core/concepts/async-replication.md
index 512ef03b7434..7149783bdbf2 100644
--- a/ydb/docs/en/core/concepts/async-replication.md
+++ b/ydb/docs/en/core/concepts/async-replication.md
@@ -1,4 +1,4 @@
-# Asynchronous replication
+# Asynchronous Replication
Asynchronous replication allows for synchronizing data between {{ ydb-short-name }} [databases](glossary.md#database) in near real time. It can also be used for data migration between databases with minimal downtime for applications interacting with these databases. Such databases can be located in the same {{ ydb-short-name }} [cluster](glossary.md#cluster) as well as in different clusters.
@@ -66,13 +66,13 @@ Replicas are created under the user account that was used to create the asynchro
{% endnote %}
-### Initial table scan {#initial-scan}
+### Initial Table Scan {#initial-scan}
During the [initial table scan](cdc.md#initial-scan) the source data is exported to changefeeds. The target runs [consumers](topic.md#consumer) that read the source data from the changefeeds and write it to replicas.
You can get the progress of the initial table scan from the [description](../reference/ydb-cli/commands/scheme-describe.md) of the asynchronous replication instance.
-### Change data replication {#replication-of-changes}
+### Change Data Replication {#replication-of-changes}
After the initial table scan is completed, the consumers read the change data and write it to replicas.
@@ -97,7 +97,7 @@ You can also get the replication lag from the [description](../reference/ydb-cli
* During asynchronous replication, you cannot [add or delete columns](../yql/reference/syntax/alter_table/columns.md) in the source tables.
* During asynchronous replication, replicas are available only for reading.
-## Error handling during asynchronous replication {#error-handling}
+## Error Handling During Asynchronous Replication {#error-handling}
Possible errors during asynchronous replication can be grouped into the following classes:
@@ -110,9 +110,9 @@ Currently, asynchronous replication that is aborted due to a critical error cann
{% endnote %}
-For more information about error classes and how to address them, refer to [Error handling](../reference/ydb-sdk/error_handling.md).
+For more information about error classes and how to address them, refer to [Error Handling](../reference/ydb-sdk/error_handling.md).
-## Asynchronous replication completion {#done}
+## Asynchronous Replication Completion {#done}
Completion of asynchronous replication might be an end goal of data migration from one database to another. In this case the client stops writing data to the source, waits for the zero replication lag, and completes replication. After the replication process is completed, replicas become available both for reading and writing. Then you can switch the load from the source database to the target database and complete data migration.
@@ -130,7 +130,7 @@ You cannot resume completed asynchronous replication.
To complete asynchronous replication, use the [ALTER ASYNC REPLICATION](../yql/reference/syntax/alter-async-replication.md) YQL expression.
-## Dropping an asynchronous replication instance {#drop}
+## Dropping an Asynchronous Replication Instance {#drop}
When you drop an asynchronous replication instance:
diff --git a/ydb/docs/en/core/concepts/cdc.md b/ydb/docs/en/core/concepts/cdc.md
index d41cdb3ca96e..d98f453df0fd 100644
--- a/ydb/docs/en/core/concepts/cdc.md
+++ b/ydb/docs/en/core/concepts/cdc.md
@@ -11,7 +11,7 @@ When adding, updating, or deleting a table row, CDC generates a change record by
* Change records are sharded across topic partitions by primary key.
* Each change is only delivered once (exactly-once delivery).
* Changes by the same primary key are delivered to the same topic partition in the order they took place in the table.
-* Change record is delivered to the topic partition only after the corresponding transaction in the table has been committed.
+* Change records are delivered to the topic partition only after the corresponding transaction in the table has been committed.
## Limitations {#restrictions}
@@ -23,14 +23,14 @@ When adding, updating, or deleting a table row, CDC generates a change record by
Adding rows is a special update case, and a record of adding a row in a changefeed will look similar to an update record.
-## Virtual timestamps {#virtual-timestamps}
+## Virtual Timestamps {#virtual-timestamps}
All changes in {{ ydb-short-name }} tables are arranged according to the order in which transactions are performed. Each change is marked with a virtual timestamp which consists of two elements:
1. Global coordinator time.
-1. Unique transaction ID.
+2. Unique transaction ID.
-Using these stamps, you can arrange records from different partitions of the topic relative to each other or use them for filtering (for example, to exclude old change records).
+Using these timestamps, you can arrange records from different partitions of the topic relative to each other or use them for filtering (for example, to exclude old change records).
{% note info %}
@@ -38,13 +38,13 @@ By default, virtual timestamps are not uploaded to the changefeed. To enable the
{% endnote %}
-## Initial table scan {#initial-scan}
+## Initial Table Scan {#initial-scan}
By default, a changefeed only includes records about those table rows that changed after the changefeed was created. Initial table scan enables you to export, to the changefeed, the values of all the rows that existed at the time of changefeed creation.
The scan runs in the background mode on top of the table snapshot. The following situations are possible:
-* A non-scanned row changes in the table. The changefeed will receive, one after another: a record with the source value and a record about the update. When the same record is changed again, only the update record is exported.
+* A non-scanned row changes in the table. The changefeed will receive, one after another: a record with the source value and a record about the update. When the same record is changed again, only the update record is exported.
* A changed row is found during scanning. Nothing is exported to the changefeed because the source value has already been exported at the time of change (see the previous paragraph).
* A scanned row changes in the table. Only an update record exports to the changefeed.
@@ -64,11 +64,11 @@ During the scanning process, depending on the table update frequency, you might
{% endnote %}
-## Record structure {#record-structure}
+## Record Structure {#record-structure}
Depending on the [changefeed parameters](../yql/reference/syntax/alter_table/changefeed.md), the structure of a record may differ.
-### JSON format {#json-record-structure}
+### JSON Format {#json-record-structure}
A [JSON](https://en.wikipedia.org/wiki/JSON) record has the following structure:
@@ -154,7 +154,7 @@ Record with virtual timestamps:
{% if audience == "tech" %}
-### Amazon DynamoDB-compatible JSON format {#dynamodb-streams-json-record-structure}
+### Amazon DynamoDB-Compatible JSON Format {#dynamodb-streams-json-record-structure}
For [Amazon DynamoDB](https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/Introduction.html)-compatible document tables, {{ ydb-short-name }} can generate change records in the [Amazon DynamoDB Streams](https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/Streams.html)-compatible format.
@@ -169,7 +169,7 @@ The record structure is the same as for [Amazon DynamoDB Streams](https://docs.a
{% endif %}
-### Debezium-compatible JSON format {#debezium-json-record-structure}
+### Debezium-Compatible JSON Format {#debezium-json-record-structure}
A [Debezium](https://debezium.io)-compatible JSON record structure has the following format:
@@ -219,7 +219,7 @@ When reading using Kafka API, the Debezium-compatible primary key of the modifie
* `payload`: Key of a row that was changed. Contains names and values of the columns that are components of the primary key.
-## Record retention period {#retention-period}
+## Record Retention Period {#retention-period}
By default, records are stored in the changefeed for 24 hours from the time they are sent. Depending on usage scenarios, the retention period can be reduced or increased up to 30 days.
@@ -233,9 +233,9 @@ Deleting records before they are processed by the client will cause [offset](top
To set up the record retention period, specify the [RETENTION_PERIOD](../yql/reference/syntax/alter_table/changefeed.md) parameter when creating a changefeed.
-## Topic partitions {#topic-partitions}
+## Topic Partitions {#topic-partitions}
-By default, the number of [topic partitions](topic.md#partitioning) is equal to the number of table partitions. The number of topic partitions can be redefined by specifying [TOPIC_MIN_ACTIVE_PARTITIONS](../yql/reference/syntax/alter_table/changefeed.md) parameter when creating a changefeed.
+By default, the number of [topic partitions](topic.md#partitioning) is equal to the number of table partitions. The number of topic partitions can be redefined by specifying the [TOPIC_MIN_ACTIVE_PARTITIONS](../yql/reference/syntax/alter_table/changefeed.md) parameter when creating a changefeed.
{% note info %}
@@ -243,10 +243,10 @@ Currently, the ability to explicitly specify the number of topic partitions is a
{% endnote %}
-## Creating and deleting a changefeed {#ddl}
+## Creating and Deleting a Changefeed {#ddl}
You can add a changefeed to an existing table or erase it using the [ADD CHANGEFEED and DROP CHANGEFEED](../yql/reference/syntax/alter_table/changefeed.md) directives of the YQL `ALTER TABLE` statement. When erasing a table, the changefeed added to it is also deleted.
-## CDC purpose and use {#best_practices}
+## CDC Purpose and Use {#best_practices}
For information about using CDC when developing apps, see [best practices](../dev/cdc.md).
diff --git a/ydb/docs/en/core/concepts/column-table.md b/ydb/docs/en/core/concepts/column-table.md
index 926388448c95..43198502c55a 100644
--- a/ydb/docs/en/core/concepts/column-table.md
+++ b/ydb/docs/en/core/concepts/column-table.md
@@ -1,4 +1,4 @@
-# Сolumn-oriented table
+# Column-Oriented Table
{% note warning %}
@@ -6,7 +6,7 @@ Column-oriented {{ ydb-short-name }} tables are in the Preview mode.
{% endnote %}
-A column-oriented table in {{ ydb-short-name }} is a relational table containing a set of related data and made up of rows and columns. Unlike regular [row-oriented {{ ydb-short-name }} tables](#table) designed for [OLTP loads](https://ru.wikipedia.org/wiki/OLTP), column-oriented tables are optimized for data analytics and [OLAP loads](https://ru.wikipedia.org/wiki/OLAP).
+A column-oriented table in {{ ydb-short-name }} is a relational table containing a set of related data and made up of rows and columns. Unlike regular [row-oriented {{ ydb-short-name }} tables](#table) designed for [OLTP loads](https://en.wikipedia.org/wiki/OLTP), column-oriented tables are optimized for data analytics and [OLAP loads](https://en.wikipedia.org/wiki/OLAP).
The current primary use case for column-oriented tables is writing data with the increasing primary key, for example, event time, analyzing this data, and deleting expired data based on TTL. The optimal method of inserting data to column-oriented tables is batch writing in blocks of several megabytes.
@@ -15,7 +15,7 @@ The data batches are inserted atomically: the data will be written either to all
In most cases, working with column-oriented {{ ydb-short-name }} tables is similar to row-oriented tables. However, there are the following distinctions:
* You can only use NOT NULL columns as your key columns.
-* Data is not partitioned by the primary key but by the hash from the [partitioning columns](#olap-tables-partitioning).
+* Data is not partitioned by the primary key but by the hash from the [partitioning columns](#olap-tables-partitioning).
* A [limited set](#olap-data-types) of data types is supported.
What's currently not supported:
@@ -27,11 +27,11 @@ What's currently not supported:
* Change Data Capture
* Renaming tables
* Custom attributes in tables
-* Updating data column lists in column-oriented tables
+* Updating data column lists in column-oriented tables
* Adding data to column-oriented tables by the SQL `INSERT` operator
-* Deleting data from column-oriented tables using the SQL `DELETE` operator The data is actually deleted on TTL expiry.
+* Deleting data from column-oriented tables using the SQL `DELETE` operator. The data is actually deleted on TTL expiry.
-## Supported data types {#olap-data-types}
+## Supported Data Types {#olap-data-types}
| Data type | Can be used in
column-oriented tables | Can be used
as primary key |
---|---|---
@@ -64,7 +64,7 @@ Learn more in [{#T}](../yql/reference/types/index.md).
Unlike row-oriented {{ ydb-short-name }} tables, you cannot partition column-oriented tables by primary keys but only by specially designated partitioning keys. Partitioning keys constitute a subset of the table's primary keys.
-Unlike data partitioning in row-oriented {{ ydb-short-name }} tables, key values are not used to partition data in column-oriented tables. Hash values from keys are used instead. This way, you can uniformly distribute data across all your existing partitions. This kind of partitioning enables you to avoid hotspots at data insert, streamlining analytical queries that process (that is, read) large data amounts.
+Unlike data partitioning in row-oriented {{ ydb-short-name }} tables, key values are not used to partition data in column-oriented tables. Hash values from keys are used instead. This way, you can uniformly distribute data across all your existing partitions. This kind of partitioning enables you to avoid hotspots at data insert, streamlining analytical queries that process (that is, read) large data amounts.
How you select partitioning keys substantially affects the performance of your column-oriented tables. Learn more in [{#T}](../best_practices/pk-olap-scalability.md).
@@ -77,6 +77,6 @@ To manage data partitioning, use the `AUTO_PARTITIONING_MIN_PARTITIONS_COUNT` ad
Because it ignores all the other partitioning parameters, the system uses the same value as the upper partition limit.
-## See also {#see-also}
+## See Also {#see-also}
* [{#T}](../yql/reference/syntax/create_table.md#olap-tables)
diff --git a/ydb/docs/en/core/concepts/connect.md b/ydb/docs/en/core/concepts/connect.md
index b62c09cee8aa..05de01df45b3 100644
--- a/ydb/docs/en/core/concepts/connect.md
+++ b/ydb/docs/en/core/concepts/connect.md
@@ -1,10 +1,10 @@
-# Connecting to a database
+# Connecting to a Database
To connect to a {{ ydb-short-name }} database from the {{ ydb-short-name }} CLI or an app running the {{ ydb-short-name }} SDK, specify your [endpoint](#endpoint) and [database path](#database).
## Endpoint {#endpoint}
-An endpoint is a string structured as `protocol://host:port` and provided by a {{ ydb-short-name }} cluster owner for proper routing of client queries to its databases by way of a network infrastructure as well as for proper network connections. Cloud databases display the endpoint in the management console on the requisite DB page and also normally send it via the cloud provider's CLI. In corporate environments, endpoint names {{ ydb-short-name }} are provided by the administration team or obtained in the internal cloud management console.
+An endpoint is a string structured as `protocol://host:port` and provided by a {{ ydb-short-name }} cluster owner for proper routing of client queries to its databases by way of a network infrastructure as well as for proper network connections. Cloud databases display the endpoint in the management console on the requisite DB page and also normally send it via the cloud provider's CLI. In corporate environments, {{ ydb-short-name }} endpoint names are provided by the administration team or obtained in the internal cloud management console.
{% include [overlay/endpoint.md](_includes/connect_overlay/endpoint.md) %}
@@ -14,9 +14,9 @@ Examples:
* `grpcs://ydb.example.com` is an encrypted data interchange protocol (gRPCs) with the server running on the ydb.example.com host on an isolated corporate network and listening for connections on YDB default port 2135.
* `grpcs://ydb.serverless.yandexcloud.net:2135` is an encrypted data interchange protocol (gRPCs), public {{ yandex-cloud }} Serverless YDB server at ydb.serverless.yandexcloud.net, port 2135.
-## Database path {#database}
+## Database Path {#database}
-Database path (`database`) is a string that defines where the queried database is located in the {{ ydb-short-name }} cluster. Has the [format](https://en.wikipedia.org/wiki/Path_(computing)) and uses the `/` character as separator. It always starts with a `/`.
+Database path (`database`) is a string that defines where the queried database is located in the {{ ydb-short-name }} cluster. It has the [format](https://en.wikipedia.org/wiki/Path_(computing)) and uses the `/` character as separator. It always starts with a `/`.
A {{ ydb-short-name }} cluster may have multiple databases deployed, with their paths determined by the cluster configuration. Like the endpoint, `database` for cloud databases is displayed in the management console on the desired database page, and can also be obtained via the CLI of the cloud provider.
@@ -35,7 +35,7 @@ Examples:
* `/ru-central1/b1g8skpblkos03malf3s/etn01q5ko6sh271beftr` is a {{ yandex-cloud }} database with `etn01q3ko8sh271beftr` as ID deployed in the `b1g8skpbljhs03malf3s` cloud in the `ru-central1` region.
* `/local` is the default database for custom deployment [using Docker](../quickstart.md).
-## Connection string {#connection_string}
+## Connection String {#connection_string}
A connection string is a URL-formatted string that specifies the endpoint and path to a database using the following syntax:
@@ -48,8 +48,8 @@ Examples:
Using a connection string is an alternative to specifying the endpoint and database path separately and can be used in tools that support this method.
-## A root certificate for TLS {#tls-cert}
+## A Root Certificate for TLS {#tls-cert}
When using an encrypted protocol ([gRPC over TLS](https://grpc.io/docs/guides/auth/), or gRPCS), a network connection can only be continued if the client is sure that it receives a response from the genuine server that it is trying to connect to, rather than someone in-between intercepting its request on the network. This is assured by verifications through a [chain of trust](https://en.wikipedia.org/wiki/Chain_of_trust), for which you need to install a root certificate on your client.
-The OS that the client runs on already include a set of root certificates from the world's major certification authorities. However, the {{ ydb-short-name }} cluster owner can use its own CA that is not associated with any of the global ones, which is often the case in corporate environments, and is almost always used for self-deployment of clusters with connection encryption support. In this case, the cluster owner must somehow transfer its root certificate for use on the client side. This certificate may be installed in the operating system's certificate store where the client runs (manually by a user or by a corporate OS administration team) or built into the client itself (as is the case for {{ yandex-cloud }} in {{ ydb-short-name }} CLI and SDK).
+The OS that the client runs on already includes a set of root certificates from the world's major certification authorities. However, the {{ ydb-short-name }} cluster owner can use its own CA that is not associated with any of the global ones, which is often the case in corporate environments, and is almost always used for self-deployment of clusters with connection encryption support. In this case, the cluster owner must somehow transfer its root certificate for use on the client side. This certificate may be installed in the operating system's certificate store where the client runs (manually by a user or by a corporate OS administration team) or built into the client itself (as is the case for {{ yandex-cloud }} in {{ ydb-short-name }} CLI and SDK).
diff --git a/ydb/docs/en/core/concepts/datamodel/_includes/object-naming-rules.md b/ydb/docs/en/core/concepts/datamodel/_includes/object-naming-rules.md
index c12dfd0333be..3f69df9711a7 100644
--- a/ydb/docs/en/core/concepts/datamodel/_includes/object-naming-rules.md
+++ b/ydb/docs/en/core/concepts/datamodel/_includes/object-naming-rules.md
@@ -1,24 +1,24 @@
-## Database object naming rules {#object-naming-rules}
+## Database Object Naming Rules {#object-naming-rules}
Every [scheme object](../../../concepts/glossary.md#scheme-object) in {{ ydb-short-name }} has a name. In YQL statements, object names are specified by identifiers that can be enclosed in backticks or not. For more information on identifiers, refer to [{#T}](../../../yql/reference/syntax/lexer.md#keywords-and-ids).
Scheme object names in {{ ydb-short-name }} must meet the following requirements:
- Object names can include the following characters:
- - uppercase latin characters
- - lowercase latin characters
- - digits
- - special characters: `.`, `-`, and `_`.
+ - Uppercase Latin characters
+ - Lowercase Latin characters
+ - Digits
+ - Special characters: `.`, `-`, and `_`
- Object name length must not exceed 255 characters.
-- Objects cannot be created in folders, which names start with a dot, such as `.sys`, `.medatata`, `.sys_health`.
+- Objects cannot be created in folders which names start with a dot, such as `.sys`, `.metadata`, and `.sys_health`.
-## Column naming rules {#column-naming-rules}
+## Column Naming Rules {#column-naming-rules}
Column names in {{ ydb-short-name }} must meet the following requirements:
- Column names can include the following characters:
- - uppercase latin characters
- - lowercase latin characters
- - digits
- - special characters: `-` and `_`.
+ - Uppercase Latin characters
+ - Lowercase Latin characters
+ - Digits
+ - Special characters: `-` and `_`
- Column names must not start with the system prefix `__ydb_`.
diff --git a/ydb/docs/en/core/concepts/datamodel/_includes/table.md b/ydb/docs/en/core/concepts/datamodel/_includes/table.md
index eb7c2cfaf769..6b97f606512f 100644
--- a/ydb/docs/en/core/concepts/datamodel/_includes/table.md
+++ b/ydb/docs/en/core/concepts/datamodel/_includes/table.md
@@ -17,23 +17,23 @@ CREATE TABLE article (
Please note that currently, the `NOT NULL` constraint can only be applied to columns that are part of the primary key.
-{{ ydb-short-name }} supports the creation of both row-oriented and column-oriented tables. The primary difference between them lies in their use-cases and how data is stored on the disk drive. In row-oriented tables, data is stored sequentially in the form of rows, while in column-oriented tables, data is stored in the form of columns. Each table type has its own specific purpose.
+{{ ydb-short-name }} supports the creation of both row-oriented and column-oriented tables. The primary difference between them lies in their use cases and how data is stored on the disk drive. In row-oriented tables, data is stored sequentially in the form of rows, while in column-oriented tables, data is stored in the form of columns. Each table type has its own specific purpose.
-## Row-oriented tables {#row-oriented-tables}
+## Row-Oriented Tables {#row-oriented-tables}
Row-oriented tables are well-suited for transactional queries generated by Online Transaction Processing (OLTP) systems, such as weather service backends or online stores. Row-oriented tables offer efficient access to a large number of columns simultaneously. Lookups in row-oriented tables are optimized due to the utilization of indexes.
An index is a data structure that improves the speed of data retrieval operations based on one or several columns. It's analogous to an index in a book: instead of scanning every page of the book to find a specific chapter, you can refer to the index at the back of the book and quickly navigate to the desired page.
-Searching using an index allows you to swiftly locate the required rows without scanning through all the data. For instance, if you have an index on the “author” column and you're looking for articles written by “Gray”, the DBMS leverages this index to quickly identify all rows associated with that surname.
+Searching using an index allows you to swiftly locate the required rows without scanning through all the data. For instance, if you have an index on the "author" column and you're looking for articles written by "Gray," the DBMS leverages this index to quickly identify all rows associated with that surname.
You can create a row-oriented table through the {{ ydb-short-name }} web interface, CLI, or SDK. Regardless of the method you choose to interact with {{ ydb-short-name }}, it's important to keep in mind the following rule: the table must have at least one primary key column, and it's permissible to create a table consisting solely of primary key columns.
By default, when creating a row-oriented table, all columns are optional and can have `NULL` values. This behavior can be modified by setting the `NOT NULL` conditions for key columns that are part of the primary key. Primary keys are unique, and row-oriented tables are always sorted by this key. This means that point reads by the key, as well as range queries by key or key prefix, are efficiently executed (essentially using an index). It's permissible to create a table consisting solely of key columns. When choosing a key, it's crucial to be careful, so we recommend reviewing the article: ["Choosing a Primary Key for Maximum Performance"](../../../dev/primary-key/row-oriented.md).
-### Partitioning row-oriented tables {#partitioning}
+### Partitioning Row-Oriented Tables {#partitioning}
-A row-oriented database table can be partitioned by primary key value ranges. Each partition of the table is responsible for the specific section of primary keys. Key ranges served by different partitions do not overlap. Different table partitions can be served by different cluster nodes (including ones in different locations). Partitions can also move independently between servers to enable rebalancing or ensure partition operability if servers or network equipment goes offline.
+A row-oriented database table can be partitioned by primary key value ranges. Each partition of the table is responsible for a specific section of primary keys. Key ranges served by different partitions do not overlap. Different table partitions can be served by different cluster nodes (including ones in different locations). Partitions can also move independently between servers to enable rebalancing or ensure partition operability if servers or network equipment goes offline.
If there is not a lot of data or load, the table may consist of a single shard. As the amount of data served by the shard or the load on the shard grows, {{ ydb-short-name }} automatically splits this shard into two shards. The data is split by the median value of the primary key if the shard size exceeds the threshold. If partitioning by load is used, the shard first collects a sample of the requested keys (that can be read, written, and deleted) and, based on this sample, selects a key for partitioning to evenly distribute the load across new shards. So in the case of load-based partitioning, the size of new shards may significantly vary.
@@ -41,7 +41,7 @@ The size-based shard split threshold and automatic splitting can be configured (
In addition to automatically splitting shards, you can create an empty table with a predefined number of shards. You can manually set the exact shard key split range or evenly split it into a predefined number of shards. In this case, ranges are created based on the first component of the primary key. You can set even splitting for tables that have a `Uint64` or `Uint32` integer as the first component of the primary key.
-Partitioning parameters refer to the table itself rather than to secondary indexes built on its data. Each index is served by its own set of shards and decisions to split or merge its partitions are made independently based on the default settings. These settings may become available to users in the future like the settings of the main table.
+Partitioning parameters refer to the table itself rather than to secondary indexes built on its data. Each index is served by its own set of shards, and decisions to split or merge its partitions are made independently based on the default settings. These settings may become available to users in the future like the settings of the main table.
A split or a merge usually takes about 500 milliseconds. During this time, the data involved in the operation becomes temporarily unavailable for reads and writes. Without raising it to the application level, special wrapper methods in the {{ ydb-short-name }} SDK make automatic retries when they discover that a shard is being split or merged. Please note that if the system is overloaded for some reason (for example, due to a general shortage of CPU or insufficient DB disk throughput), split and merge operations may take longer.
@@ -68,7 +68,7 @@ When choosing the minimum number of partitions, it makes sense to consider that
#### AUTO_PARTITIONING_PARTITION_SIZE_MB {#auto_partitioning_partition_size_mb}
* Type: `Uint64`.
-* Default value: `2000 MB` ( `2 GB` ).
+* Default value: `2000 MB` (`2 GB`).
The desired partition size threshold in megabytes. Recommended values range from `10 MB` to `2000 MB`. If this threshold is exceeded, a shard may split. This setting takes effect when the [`AUTO_PARTITIONING_BY_SIZE`](#auto_partitioning_by_size) mode is enabled.
@@ -86,7 +86,7 @@ Partitions are only merged if their actual number exceeds the value specified by
* Type: `Uint64`.
* Default value: `50`.
-Partitions are only split if their number doesn't exceed the value specified by this parameter. With any automatic partitioning mode enabled, we recommend that you set a meaningful value for this parameter and monitor when the actual number of partitions approaches this value, otherwise splitting of partitions will stop sooner or later under an increase in data or load, which will lead to a failure.
+Partitions are only split if their number doesn't exceed the value specified by this parameter. With any automatic partitioning mode enabled, we recommend that you set a meaningful value for this parameter and monitor when the actual number of partitions approaches this value; otherwise, splitting of partitions will stop sooner or later under an increase in data or load, which will lead to a failure.
#### UNIFORM_PARTITIONS {#uniform_partitions}
@@ -106,7 +106,7 @@ Boundary values of keys for initial table partitioning. It's a list of boundary
When automatic partitioning is enabled, make sure to set the correct value for [AUTO_PARTITIONING_MIN_PARTITIONS_COUNT](#auto_partitioning_min_partitions_count) to avoid merging all partitions into one immediately after creating the table.
-### Reading data from replicas {#read_only_replicas}
+### Reading Data from Replicas {#read_only_replicas}
When making queries in {{ ydb-short-name }}, the actual execution of a query to each shard is performed at a single point serving the distributed transaction protocol. By storing data in shared storage, you can run one or more shard followers without allocating additional storage space: the data is already stored in replicated format, and you can serve more than one reader (but there is still only one writer at any given moment).
@@ -128,9 +128,9 @@ The internal state of each of the followers is restored exactly and fully consis
Besides the data state in storage, followers also receive a stream of updates from the leader. Updates are sent in real time, immediately after the commit to the log. However, they are sent asynchronously, resulting in some delay (usually no more than dozens of milliseconds, but sometimes longer in the event of cluster connectivity issues) in applying updates to followers relative to their commit on the leader. Therefore, reading data from followers is only supported in the [transaction mode](../../transactions.md#modes) `StaleReadOnly()`.
If there are multiple followers, their delay from the leader may vary: although each follower of each of the shards retains internal consistency, artifacts may be observed from shard to shard. Please provide for this in your application code. For that same reason, it's currently impossible to perform cross-shard transactions from followers.
-### Deleting expired data (TTL) {#ttl}
+### Deleting Expired Data (TTL) {#ttl}
-{{ ydb-short-name }} supports automatic background deletion of expired data. A table data schema may define a column containing a `Datetime` or a `Timestamp` value. A comparison of this value with the current time for all rows will be performed in the background. Rows for which the current time becomes greater than the column value plus specified delay, will be deleted.
+{{ ydb-short-name }} supports automatic background deletion of expired data. A table data schema may define a column containing a `Datetime` or a `Timestamp` value. A comparison of this value with the current time for all rows will be performed in the background. Rows for which the current time becomes greater than the column value plus specified delay will be deleted.
| Parameter name | Type | Acceptable values | Update capability | Reset capability |
| ------------- | --- | ------------------- | --------------------- | ------------------ |
@@ -138,18 +138,18 @@ If there are multiple followers, their delay from the leader may vary: although
Syntax of TTL value is described in the article [{#T}](../../../yql/reference/syntax/create_table/with.md#time-to-live). For more information about deleting expired data, see [Time to Live (TTL)](../../../concepts/ttl.md).
-### Renaming a table {#rename}
+### Renaming a Table {#rename}
{{ ydb-short-name }} lets you rename an existing table, move it to another directory of the same database, or replace one table with another, deleting the data in the replaced table. Only the metadata of the table is changed by operations (for example, its path and name). The table data is neither moved nor overwritten.
-Operations are performed in isolation, the external process sees only two states of the table: before and after the operation. This is critical, for example, for table replacement: the data of the replaced table is deleted by the same transaction that renames the replacing table. During the replacement, there might be errors in queries to the replaced table that have [retryable statuses](../../../reference/ydb-sdk/error_handling.md#termination-statuses).
+Operations are performed in isolation; the external process sees only two states of the table: before and after the operation. This is critical, for example, for table replacement: the data of the replaced table is deleted by the same transaction that renames the replacing table. During the replacement, there might be errors in queries to the replaced table that have [retryable statuses](../../../reference/ydb-sdk/error_handling.md#termination-statuses).
The speed of renaming is determined by the type of data transactions currently running against the table and doesn't depend on the table size.
* [Renaming a table in YQL](../../../yql/reference/syntax/alter_table/rename.md)
* [Renaming a table via the CLI](../../../reference/ydb-cli/commands/tools/rename.md)
-### Bloom filter {#bloom-filter}
+### Bloom Filter {#bloom-filter}
Using a [Bloom filter](https://en.wikipedia.org/wiki/Bloom_filter) lets you more efficiently determine if some keys are missing in a table when making multiple point queries by primary key. This reduces the number of required disk I/O operations but increases the amount of memory consumed.
@@ -157,7 +157,7 @@ Using a [Bloom filter](https://en.wikipedia.org/wiki/Bloom_filter) lets you more
| ------------- | --- | ------------------- | --------------------- | ------------------ |
| `KEY_BLOOM_FILTER` | Enum | `ENABLED`, `DISABLED` | Yes | No |
-### Column groups {#column-groups}
+### Column Groups {#column-groups}
{{ ydb-short-name }} allows grouping columns in a table to optimize their storage and usage. The column group mechanism improves performance for partial row reads by separating table columns into multiple storage groups. The most commonly used scenario is the organization of storing rarely used attributes in a separate column group. Then you can enable data compression and/or store it on slower drives.
@@ -178,7 +178,7 @@ Accessing data in primary column group fields is faster and less resource-intens
Thus, moving some columns into a separate group accelerates reads for critical, frequently used columns (in the primary group) while slightly slowing access to other columns. Additionally, column groups enable storage parameter management - selecting device types and compression modes.
-## Column-oriented tables {#column-oriented-tables}
+## Column-Oriented Tables {#column-oriented-tables}
{% note warning %}
@@ -227,7 +227,7 @@ At the moment, not all functionality of column-oriented tables is implemented. T
* Adding data to column-oriented tables using the SQL INSERT statement.
* Deleting data from column-oriented tables using the SQL DELETE statement. In fact, deletion is only possible after the TTL data retention time has expired.
-### Partitioning column-oriented tables {#olap-tables-partitioning}
+### Partitioning Column-Oriented Tables {#olap-tables-partitioning}
Unlike row-oriented {{ ydb-short-name }} tables, you cannot partition column-oriented tables by primary keys but only by specially designated partitioning keys. Partitioning keys constitute a subset of the table's primary keys.
@@ -245,7 +245,7 @@ PARTITION BY HASH(id)
WITH (STORE = COLUMN);
```
-Unlike data partitioning in row-oriented {{ ydb-short-name }} tables, key values are not used to partition data in column-oriented tables. This way, you can uniformly distribute data across all your existing partitions. This kind of partitioning enables you to avoid hotspots at data inserta and speeding up analytical queries that process (that is, read) large amounts of data.
+Unlike data partitioning in row-oriented {{ ydb-short-name }} tables, key values are not used to partition data in column-oriented tables. This way, you can uniformly distribute data across all your existing partitions. This kind of partitioning enables you to avoid hotspots at data insertion and speeds up analytical queries that process (that is, read) large amounts of data.
How you select partitioning keys substantially affects the performance of queries to your column-oriented tables. Learn more in [{#T}](../../../dev/primary-key/column-oriented.md).
diff --git a/ydb/docs/en/core/concepts/datamodel/coordination-node.md b/ydb/docs/en/core/concepts/datamodel/coordination-node.md
index 27a14163475f..f96baac7da27 100644
--- a/ydb/docs/en/core/concepts/datamodel/coordination-node.md
+++ b/ydb/docs/en/core/concepts/datamodel/coordination-node.md
@@ -1,4 +1,4 @@
-# Coordination node
+# Coordination Node
A coordination node is an object in {{ ydb-short-name }} that allows client applications to coordinate their actions in a distributed manner. Typical use cases for coordination nodes include:
@@ -34,6 +34,6 @@ Semaphores in {{ ydb-short-name }} are **not** recursive. Thus, semaphore acquis
Working with coordination nodes and semaphores is done through [dedicated methods in {{ ydb-short-name }} SDK](../../reference/ydb-sdk/coordination.md).
-## Similar systems {#similar-systems}
+## Similar Systems {#similar-systems}
{{ ydb-short-name }} coordination nodes can solve tasks that are traditionally performed using systems such as [Apache Zookeeper](https://zookeeper.apache.org/), [etcd](https://etcd.io/), [Consul](https://www.consul.io/), and others. If a project uses {{ ydb-short-name }} for data storage along with one of these third-party systems for coordination, switching to {{ ydb-short-name }} coordination nodes can reduce the number of systems that need to be operated and maintained.
\ No newline at end of file
diff --git a/ydb/docs/en/core/concepts/datamodel/external_data_source.md b/ydb/docs/en/core/concepts/datamodel/external_data_source.md
index b1b4e76879d3..516592ec6b1c 100644
--- a/ydb/docs/en/core/concepts/datamodel/external_data_source.md
+++ b/ydb/docs/en/core/concepts/datamodel/external_data_source.md
@@ -1,5 +1,4 @@
-# External data sources
-
+# External Data Sources
An external data source is an object in {{ ydb-full-name }} that describes the connection parameters to an external data source. For example, in the case of ClickHouse, the external data source describes the network address, login, and password for authentication in the ClickHouse cluster. In the case of S3 ({{ objstorage-name }}), it describes the access credentials and the path to the bucket.
diff --git a/ydb/docs/en/core/concepts/datamodel/external_table.md b/ydb/docs/en/core/concepts/datamodel/external_table.md
index 84480766194d..4ff6b2dd3737 100644
--- a/ydb/docs/en/core/concepts/datamodel/external_table.md
+++ b/ydb/docs/en/core/concepts/datamodel/external_table.md
@@ -1,8 +1,8 @@
-# External tables
+# External Tables
Some [external data sources](external_data_source.md), such as database management systems, store data in a structured format, while others, like S3 ({{objstorage-full-name}}), store data as individual files. To work with file-based data sources, you need to understand both the file placement rules and the formats of the stored data.
-A special entity, `EXTERNAL TABLE,` describes the stored data in such sources. External tables allow you to define the schema of the stored files and the schema of file placement within the source.
+A special entity, `EXTERNAL TABLE`, describes the stored data in such sources. External tables allow you to define the schema of the stored files and the schema of file placement within the source.
A record in YQL might look like this:
diff --git a/ydb/docs/en/core/concepts/datamodel/index.md b/ydb/docs/en/core/concepts/datamodel/index.md
index fa5cab139cb6..856611520137 100644
--- a/ydb/docs/en/core/concepts/datamodel/index.md
+++ b/ydb/docs/en/core/concepts/datamodel/index.md
@@ -1,4 +1,4 @@
-# Data model and schema
+# Data Model and Schema
This section describes the entities that {{ ydb-short-name }} uses within DBs. The {{ ydb-short-name }} core lets you flexibly implement various storage primitives, so new entities may appear in the future.
@@ -13,8 +13,8 @@ This section describes the entities that {{ ydb-short-name }} uses within DBs. T
* [Topic](../topic.md)
* [Secret](secrets.md)
-* [External table](external_table.md)
-* [External data source](external_data_source.md)
+* [External Table](external_table.md)
+* [External Data Source](external_data_source.md)
[Scheme objects](../../concepts/glossary.md#scheme-object) in {{ ydb-short-name }} all follow the same naming rules described in the section below. However, requirements for column names are slightly different.
diff --git a/ydb/docs/en/core/concepts/datamodel/secrets.md b/ydb/docs/en/core/concepts/datamodel/secrets.md
index 996fe7f9b2fc..d50291e53fbf 100644
--- a/ydb/docs/en/core/concepts/datamodel/secrets.md
+++ b/ydb/docs/en/core/concepts/datamodel/secrets.md
@@ -14,7 +14,7 @@ The current syntax for working with secrets is temporary and will be changed in
{% endnote %}
-## Creating secrets {#create_secret}
+## Creating Secrets {#create_secret}
Secrets are created using an SQL query:
@@ -22,11 +22,11 @@ Secrets are created using an SQL query:
CREATE OBJECT `MySecretName` (TYPE SECRET) WITH value=`MySecretData`;
```
-## Access management {#secret_access}
+## Access Management {#secret_access}
All rights to use the secret belong to its creator. The creator can grant another user read access to the secret through [access management](#secret_access) for secrets.
-Special objects called `SECRET_ACCESS` are used to manage access to secrets. To grant permission to use the secret `MySecretName` to the user `another_user`, a `SECRET_ACCESS` object named `MySecretName:another_user` must be created.
+Special objects called `SECRET_ACCESS` are used to manage access to secrets. To grant permission to use the secret `MySecretName` to the user `another_user`, a `SECRET_ACCESS` object named `MySecretName:another_user` must be created:
```yql
CREATE OBJECT `MySecretName:another_user` (TYPE SECRET_ACCESS)
diff --git a/ydb/docs/en/core/concepts/datamodel/view.md b/ydb/docs/en/core/concepts/datamodel/view.md
index 7aab9eb3586e..323625278100 100644
--- a/ydb/docs/en/core/concepts/datamodel/view.md
+++ b/ydb/docs/en/core/concepts/datamodel/view.md
@@ -4,9 +4,9 @@ A view logically represents a table formed by a given query. The view itself con
Views are often used to:
-- hide query complexity
-- limit access to underlying data
-- provide a backward-compatible interface to emulate a table that used to exist but whose schema has changed
+- Hide query complexity
+- Limit access to underlying data
+- Provide a backward-compatible interface to emulate a table that used to exist but whose schema has changed
{% note warning %}
@@ -14,7 +14,7 @@ The scenario of creating a view to grant other users partial `SELECT` privileges
{% endnote %}
-## View invalidation
+## View Invalidation
If you drop a table that a view references, the view will become invalid. Queries against it will fail with an error caused by referencing a table that does not exist. To make the view valid again, you must provide a queryable entity with the same name (by creating or renaming a table or another view). It needs to have a schema compatible with the deleted one. The dependencies of views on tables and other views are not tracked. A `SELECT` from a view is executed like a `SELECT` from a subquery would, without any prior checks of validity. You would know that the view's query became invalid only at the moment of its execution. This approach will change in future releases: {{ ydb-short-name }} will start tracking the view's dependencies, and the default behavior would be to forbid dropping a table if there's a view referencing it.
@@ -22,12 +22,12 @@ If you drop a table that a view references, the view will become invalid. Querie
Queries are executed in two steps:
-1. compilation
-2. execution of the compiled code
+1. Compilation
+2. Execution of the compiled code
The resulting compiled code contains no evidence that the query was made using views because all the references to views should have been replaced during compilation by the queries that they represent. In practice, there must be no difference in the execution time of the compiled code (step 2) for queries made using views versus queries directly reading from the underlying tables.
-However, users might notice a little increase in the compilation time of the queries made using views compared to the compilation time of the same queries written directly. It happens because a statement reading from a view:
+However, users might notice a slight increase in the compilation time of the queries made using views compared to the compilation time of the same queries written directly. It happens because a statement reading from a view:
```yql
SELECT * FROM a_view;
@@ -50,7 +50,7 @@ SELECT * FROM hot_view;
compilation results will be cached on the {{ ydb-short-name }} server side, and you will not notice any difference in the performance of queries using views and direct queries.
-## View redefinition lag
+## View Redefinition Lag
{% note warning %}
@@ -58,15 +58,15 @@ Execution plans of queries containing views are currently cached. It might lead
{% endnote %}
-### Query compilation cache
+### Query Compilation Cache
{{ ydb-short-name }} caches query compilation results on the server side for efficiency. For small queries like `SELECT 1;` compilation can take significantly more time than the execution.
The cache entry is searched by the text of the query and some additional information, such as a user SID.
-The cache is automatically updated by {{ ydb-short-name }} to stay on track with the changes made to the objects the query references. However, in the case of views, the cache is not updated in the same transaction in which the object's definition changes. It happens with a little delay.
+The cache is automatically updated by {{ ydb-short-name }} to stay on track with the changes made to the objects the query references. However, in the case of views, the cache is not updated in the same transaction in which the object's definition changes. It happens with a slight delay.
-### Example of the problem
+### Example of the Problem
Let's consider the following situation. Alice repeatedly executes the following query:
@@ -83,9 +83,9 @@ DROP VIEW some_view_which_is_going_to_be_redefined;
CREATE VIEW some_view_which_is_going_to_be_redefined ...;
```
-The text of Alice's query does not change, which means that the compilation will happen only once, and the results are going to be taken from the cache since then. Bob changes the definition of the view, and the cache entry for Alice's query should theoretically be evicted from the cache in the same transaction in which the view was redefined. However, this is not the case. Alice's query will be recompiled with a little delay, which means that for a short period of time, Alice's query will produce results that are inconsistent with the updated definition of the view. This is going to be fixed in future releases.
+The text of Alice's query does not change, which means that the compilation will happen only once, and the results are going to be taken from the cache since then. Bob changes the definition of the view, and the cache entry for Alice's query should theoretically be evicted from the cache in the same transaction in which the view was redefined. However, this is not the case. Alice's query will be recompiled with a slight delay, which means that for a short period of time, Alice's query will produce results that are inconsistent with the updated definition of the view. This is going to be fixed in future releases.
-## See also
+## See Also
* [CREATE VIEW](../../yql/reference/syntax/create-view.md)
* [ALTER VIEW](../../yql/reference/syntax/alter-view.md)
diff --git a/ydb/docs/en/core/concepts/federated_query/_includes/connector_deployment.md b/ydb/docs/en/core/concepts/federated_query/_includes/connector_deployment.md
index 4e5c1a4cdbd6..a2556e75b54c 100644
--- a/ydb/docs/en/core/concepts/federated_query/_includes/connector_deployment.md
+++ b/ydb/docs/en/core/concepts/federated_query/_includes/connector_deployment.md
@@ -1 +1 @@
-{% if oss == "true" %}Deploy the [connector](../architecture.md#connectors) {% else %}Deploy the connector{% endif %} and {% if oss == true %}[configure](../../../devops/manual/federated-queries/index.md) {% else %}configure{% endif %} the {{ ydb-short-name }} dynamic nodes to interact with it. Additionally, ensure network access from the {{ ydb-short-name }} dynamic nodes to the external data source (at the address specified in the `LOCATION` parameter of the `CREATE EXTERNAL DATA SOURCE` request). If network connection encryption to the external source was enabled in the previous step, the connector will use the system's root certificates (more details on TLS configuration can be found in the [guide](../../../devops/manual/federated-queries/connector-deployment.md) on deploying the connector).
+{% if oss == "true" %}Deploy the [connector](../architecture.md#connectors) {% else %}Deploy the connector{% endif %} and {% if oss == "true" %}[configure](../../../devops/manual/federated-queries/index.md) {% else %}configure{% endif %} the {{ ydb-short-name }} dynamic nodes to interact with it. Additionally, ensure network access from the {{ ydb-short-name }} dynamic nodes to the external data source (at the address specified in the `LOCATION` parameter of the `CREATE EXTERNAL DATA SOURCE` request). If network connection encryption to the external source was enabled in the previous step, the connector will use the system's root certificates. More details on TLS configuration can be found in the [guide](../../../devops/manual/federated-queries/connector-deployment.md) on deploying the connector.
diff --git a/ydb/docs/en/core/concepts/federated_query/_includes/predicate_pushdown.md b/ydb/docs/en/core/concepts/federated_query/_includes/predicate_pushdown.md
index c1c4ff661bb6..e3213138c8cc 100644
--- a/ydb/docs/en/core/concepts/federated_query/_includes/predicate_pushdown.md
+++ b/ydb/docs/en/core/concepts/federated_query/_includes/predicate_pushdown.md
@@ -5,7 +5,7 @@ A specific case of predicate pushdown, where filtering expressions specified aft
|Description|Example|
|---|---|
|Filters like `IS NULL`/`IS NOT NULL`|`WHERE column1 IS NULL` or `WHERE column1 IS NOT NULL`|
-|Logical conditions `OR`, `NOT`, `AND`|`WHERE column IS NULL OR column2 is NOT NULL`|
+|Logical conditions `OR`, `NOT`, `AND`|`WHERE column IS NULL OR column2 IS NOT NULL`|
|Comparison conditions `=`, `<>`, `<`, `<=`, `>`, `>=` with other columns or constants|`WHERE column3 > column4 OR column5 <= 10`|
Supported data types for filter pushdown:
diff --git a/ydb/docs/en/core/concepts/federated_query/architecture.md b/ydb/docs/en/core/concepts/federated_query/architecture.md
index 8610d93154c0..4752e336b3bb 100644
--- a/ydb/docs/en/core/concepts/federated_query/architecture.md
+++ b/ydb/docs/en/core/concepts/federated_query/architecture.md
@@ -1,6 +1,6 @@
-# Federated query processing system architecture
+# Federated Query Processing System Architecture
-## External data sources and external tables
+## External Data Sources and External Tables
A key element of the federated query processing system in {{ ydb-full-name }} is the concept of an [external data source](../datamodel/external_data_source.md). Such sources can include relational DBMS, object storage, and other data storage systems. When processing a federated query, {{ ydb-short-name }} streams data from external systems and allows performing the same range of operations on them as on local data.
@@ -26,7 +26,7 @@ Thus, connectors form an abstraction layer that hides the specifics of external
Users can deploy [one of the ready-made connectors](../../devops/manual/federated-queries/connector-deployment.md) or write their own implementation in any programming language according to the [gRPC specification](https://github.com/ydb-platform/ydb/tree/main/ydb/library/yql/providers/generic/connector/api).
-## List of supported external data sources {#supported-datasources}
+## List of Supported External Data Sources {#supported-datasources}
| Source | Support |
|--------|---------|
@@ -35,5 +35,5 @@ Users can deploy [one of the ready-made connectors](../../devops/manual/federate
| [Microsoft SQL Server](https://learn.microsoft.com/en-us/sql/?view=sql-server-ver16) | Via connector [fq-connector-go](../../devops/manual/federated-queries/connector-deployment.md#fq-connector-go) |
| [MySQL](https://www.mysql.com/) | Via connector [fq-connector-go](../../devops/manual/federated-queries/connector-deployment.md#fq-connector-go) |
| [PostgreSQL](https://www.postgresql.org/) | Via connector [fq-connector-go](../../devops/manual/federated-queries/connector-deployment.md#fq-connector-go) |
-| [S3](https://aws.amazon.com/ru/s3/) | Built into `ydbd` |
+| [S3](https://aws.amazon.com/s3/) | Built into `ydbd` |
| [{{ydb-short-name}}](https://ydb.tech/) | Via connector [fq-connector-go](../../devops/manual/federated-queries/connector-deployment.md#fq-connector-go) |
diff --git a/ydb/docs/en/core/concepts/federated_query/clickhouse.md b/ydb/docs/en/core/concepts/federated_query/clickhouse.md
index c6e7ebc8bdf6..435d91ea1824 100644
--- a/ydb/docs/en/core/concepts/federated_query/clickhouse.md
+++ b/ydb/docs/en/core/concepts/federated_query/clickhouse.md
@@ -1,4 +1,4 @@
-# Working with ClickHouse databases
+# Working with ClickHouse Databases
@@ -30,7 +30,7 @@ To work with the external ClickHouse database, the following steps must be compl
3. {% include [!](_includes/connector_deployment.md) %}
4. [Execute a query](#query) to the database.
-## Query syntax {#query}
+## Query Syntax {#query}
To work with ClickHouse, use the following SQL query form:
@@ -65,13 +65,13 @@ There are several limitations when working with ClickHouse clusters:
|`Float`|
|`Double`|
-## Supported data types
+## Supported Data Types
By default, ClickHouse columns cannot physically contain `NULL` values. However, users can create tables with columns of optional or [nullable](https://clickhouse.com/docs/en/sql-reference/data-types/nullable) types. The column types displayed in {{ ydb-short-name }} when extracting data from the external ClickHouse database will depend on whether primitive or optional types are used in the ClickHouse table. Due to the previously discussed limitations of {{ ydb-short-name }} types used to store dates and times, all similar ClickHouse types are displayed in {{ ydb-short-name }} as [optional](../../yql/reference/types/optional.md).
Below are the mapping tables for ClickHouse and {{ ydb-short-name }} types. All other data types, except those listed, are not supported.
-### Primitive data types
+### Primitive Data Types
|ClickHouse data type|{{ ydb-full-name }} data type|Notes|
|---|----|------|
@@ -93,7 +93,7 @@ Below are the mapping tables for ClickHouse and {{ ydb-short-name }} types. All
|`String`|`String`||
|`FixedString`|`String`|Null bytes in `FixedString` are transferred to `String` unchanged.|
-### Optional data types
+### Optional Data Types
|ClickHouse data type|{{ ydb-full-name }} data type|Notes|
|---|----|------|
diff --git a/ydb/docs/en/core/concepts/federated_query/greenplum.md b/ydb/docs/en/core/concepts/federated_query/greenplum.md
index 5f39c6744cae..badc8144001f 100644
--- a/ydb/docs/en/core/concepts/federated_query/greenplum.md
+++ b/ydb/docs/en/core/concepts/federated_query/greenplum.md
@@ -1,4 +1,4 @@
-# Working with Greenplum databases
+# Working with Greenplum Databases
This section provides basic information on working with external [Greenplum](https://greenplum.org) databases. Since Greenplum is based on [PostgreSQL](postgresql.md), integrations with them are similar, and some links below may lead to PostgreSQL documentation.
@@ -29,7 +29,7 @@ Follow these steps to work with an external Greenplum database:
3. {% include [!](_includes/connector_deployment.md) %}
4. [Execute a query](#query) to the database.
-## Query syntax {#query}
+## Query Syntax {#query}
The following SQL query format is used to work with Greenplum:
@@ -60,7 +60,7 @@ When working with Greenplum clusters, there are a number of limitations:
|`Float`|
|`Double`|
-## Supported data types
+## Supported Data Types
In the Greenplum database, the optionality of column values (whether a column can contain `NULL` values) is not part of the data type system. The `NOT NULL` constraint for each column is implemented as the `attnotnull` attribute in the system catalog [pg_attribute](https://www.postgresql.org/docs/current/catalog-pg-attribute.html), i.e., at the metadata level of the table. Therefore, all basic Greenplum types can contain `NULL` values by default, and in the {{ ydb-full-name }} type system, they should be mapped to [optional](../../yql/reference/types/optional.md) types.
diff --git a/ydb/docs/en/core/concepts/federated_query/index.md b/ydb/docs/en/core/concepts/federated_query/index.md
index 3b959b680314..5d883b0e37f4 100644
--- a/ydb/docs/en/core/concepts/federated_query/index.md
+++ b/ydb/docs/en/core/concepts/federated_query/index.md
@@ -1,8 +1,8 @@
-# Federated queries
+# Federated Queries
Federated queries allow retrieving information from various data sources without needing to transfer the data from these sources into {{ ydb-full-name }} storage. Currently, federated queries support interaction with ClickHouse, PostgreSQL, and S3-compatible data stores. Using YQL queries, you can access these databases without the need to duplicate data between systems.
-To work with data stored in external DBMSs, it is sufficient to create an [external data source](../datamodel/external_data_source.md). To work with unstructured data stored in S3 buckets, you additionally need to create an [external table](../datamodel/external_table.md). In both cases, it is necessary to create [secrets](../datamodel/secrets.md) objects first that store confidential data required for authentication in external systems.
+To work with data stored in external DBMSs, it is sufficient to create an [external data source](../datamodel/external_data_source.md). To work with unstructured data stored in S3 buckets, you additionally need to create an [external table](../datamodel/external_table.md). In both cases, it is necessary to create [secrets](../datamodel/secrets.md) objects first that store confidential data required for authentication in external systems.
You can learn about the internals of the federated query processing system in the [architecture](./architecture.md) section. Detailed information on working with various data sources is provided in the corresponding sections:
diff --git a/ydb/docs/en/core/concepts/federated_query/ms_sql_server.md b/ydb/docs/en/core/concepts/federated_query/ms_sql_server.md
index 8cab447789eb..32caae959b42 100644
--- a/ydb/docs/en/core/concepts/federated_query/ms_sql_server.md
+++ b/ydb/docs/en/core/concepts/federated_query/ms_sql_server.md
@@ -1,6 +1,6 @@
-# Working with Microsoft SQL Server databases
+# Working with Microsoft SQL Server Databases
-This section provides basic information about working with an external [Microsoft SQL Server](https://learn.microsoft.com/en-us/sql/?view=sql-server-ver16) databases.
+This section provides basic information about working with external [Microsoft SQL Server](https://learn.microsoft.com/en-us/sql/?view=sql-server-ver16) databases.
To work with an external Microsoft SQL Server database, you need to follow these steps:
@@ -27,7 +27,7 @@ To work with an external Microsoft SQL Server database, you need to follow these
3. {% include [!](_includes/connector_deployment.md) %}
4. [Execute a query](#query) to the database.
-## Query syntax {#query}
+## Query Syntax {#query}
The following SQL query format is used to work with Microsoft SQL Server:
@@ -58,9 +58,9 @@ When working with Microsoft SQL Server clusters, there are a number of limitatio
|`Float`|
|`Double`|
-## Supported data types
+## Supported Data Types
-In the Microsoft SQL Server database, the optionality of column values (whether the column can contain `NULL` values or not) is not a part of the data type system. The `NOT NULL` constraint for any column of any table is stored within the `IS_NULLABLE` column the [INFORMATION_SCHEMA.COLUMNS](https://learn.microsoft.com/en-us/sql/relational-databases/system-information-schema-views/columns-transact-sql?view=sql-server-ver16) system table, i.e., at the table metadata level. Therefore, all basic Microsoft SQL Server types can contain `NULL` values by default, and in the {{ ydb-full-name }} type system, they should be mapped to [optional](../../yql/reference/types/optional.md).
+In the Microsoft SQL Server database, the optionality of column values (whether the column can contain `NULL` values or not) is not a part of the data type system. The `NOT NULL` constraint for any column of any table is stored within the `IS_NULLABLE` column in the [INFORMATION_SCHEMA.COLUMNS](https://learn.microsoft.com/en-us/sql/relational-databases/system-information-schema-views/columns-transact-sql?view=sql-server-ver16) system table, i.e., at the table metadata level. Therefore, all basic Microsoft SQL Server types can contain `NULL` values by default, and in the {{ ydb-full-name }} type system, they should be mapped to [optional](../../yql/reference/types/optional.md).
Below is a correspondence table between Microsoft SQL Server types and {{ ydb-short-name }} types. All other data types, except those listed, are not supported.
diff --git a/ydb/docs/en/core/concepts/federated_query/mysql.md b/ydb/docs/en/core/concepts/federated_query/mysql.md
index 2650caaa68a3..2be7a85dc3ca 100644
--- a/ydb/docs/en/core/concepts/federated_query/mysql.md
+++ b/ydb/docs/en/core/concepts/federated_query/mysql.md
@@ -1,6 +1,6 @@
-# Working with MySQL databases
+# Working with MySQL Databases
-This section provides basic information about working with an external [MySQL](https://www.mysql.com/) databases.
+This section provides basic information about working with external [MySQL](https://www.mysql.com/) databases.
To work with an external MySQL database, you need to follow these steps:
@@ -27,7 +27,7 @@ To work with an external MySQL database, you need to follow these steps:
3. {% include [!](_includes/connector_deployment.md) %}
4. [Execute a query](#query) to the database.
-## Query syntax {#query}
+## Query Syntax {#query}
The following SQL query format is used to work with MySQL:
@@ -62,9 +62,9 @@ When working with MySQL clusters, there are a number of limitations:
|`Float`|
|`Double`|
-## Supported data types
+## Supported Data Types
-In the MySQL database, the optionality of column values (whether the column can contain `NULL` values or not) is not a part of the data type system. The `NOT NULL` constraint for any column of any table is stored within the `IS_NULLABLE` column the [INFORMATION_SCHEMA.COLUMNS](https://dev.mysql.com/doc/refman/8.4/en/information-schema-columns-table.html) system table, i.e., at the table metadata level. Therefore, all basic MySQL types can contain `NULL` values by default, and in the {{ ydb-full-name }} type system they should be mapped to [optional](../../yql/reference/types/optional.md).
+In the MySQL database, the optionality of column values (whether the column can contain `NULL` values or not) is not a part of the data type system. The `NOT NULL` constraint for any column of any table is stored within the `IS_NULLABLE` column in the [INFORMATION_SCHEMA.COLUMNS](https://dev.mysql.com/doc/refman/8.4/en/information-schema-columns-table.html) system table, i.e., at the table metadata level. Therefore, all basic MySQL types can contain `NULL` values by default, and in the {{ ydb-full-name }} type system they should be mapped to [optional](../../yql/reference/types/optional.md).
Below is a correspondence table between MySQL types and {{ ydb-short-name }} types. All other data types, except those listed, are not supported.
diff --git a/ydb/docs/en/core/concepts/federated_query/postgresql.md b/ydb/docs/en/core/concepts/federated_query/postgresql.md
index 79a9e02a4fd6..2ce59609d845 100644
--- a/ydb/docs/en/core/concepts/federated_query/postgresql.md
+++ b/ydb/docs/en/core/concepts/federated_query/postgresql.md
@@ -1,4 +1,4 @@
-# Working with PostgreSQL databases
+# Working with PostgreSQL Databases
This section provides basic information on working with external [PostgreSQL](http://postgresql.org) databases.
@@ -29,7 +29,7 @@ To work with an external PostgreSQL database, you need to follow these steps:
3. {% include [!](_includes/connector_deployment.md) %}
4. [Execute a query](#query) to the database.
-## Query syntax {#query}
+## Query Syntax {#query}
The following SQL query format is used to work with PostgreSQL:
@@ -60,7 +60,7 @@ When working with PostgreSQL clusters, there are a number of limitations:
|`Float`|
|`Double`|
-## Supported data types
+## Supported Data Types
In the PostgreSQL database, the optionality of column values (whether a column can contain `NULL` values) is not part of the data type system. The `NOT NULL` constraint for each column is implemented as the `attnotnull` attribute in the system catalog [pg_attribute](https://www.postgresql.org/docs/current/catalog-pg-attribute.html), i.e., at the metadata level of the table. Therefore, all basic PostgreSQL types can contain `NULL` values by default, and in the {{ ydb-full-name }} type system, they should be mapped to [optional](../../yql/reference/types/optional.md) types.
diff --git a/ydb/docs/en/core/concepts/federated_query/s3/_includes/path_format.md b/ydb/docs/en/core/concepts/federated_query/s3/_includes/path_format.md
index 4b15b4ea5248..dc4e41a90e2a 100644
--- a/ydb/docs/en/core/concepts/federated_query/s3/_includes/path_format.md
+++ b/ydb/docs/en/core/concepts/federated_query/s3/_includes/path_format.md
@@ -1,4 +1,4 @@
-|Path format|Description|Example|
+|Path Format|Description|Example|
|----|----|---|
|Path ends with a `/`|Path to a directory|The path `/a/` addresses all contents of the directory:
`/a/b/c/d/1.txt`
`/a/b/2.csv`|
|Path contains a wildcard character `*`|Any files nested in the path|The path `/a/*.csv` addresses files in directories:
`/a/b/c/1.csv`
`/a/2.csv`
`/a/b/c/d/e/f/g/2.csv`|
diff --git a/ydb/docs/en/core/concepts/federated_query/s3/external_data_source.md b/ydb/docs/en/core/concepts/federated_query/s3/external_data_source.md
index d97cfd257272..8e682df25fe3 100644
--- a/ydb/docs/en/core/concepts/federated_query/s3/external_data_source.md
+++ b/ydb/docs/en/core/concepts/federated_query/s3/external_data_source.md
@@ -1,4 +1,4 @@
-# Working with S3 buckets ({{objstorage-full-name}})
+# Working with S3 Buckets ({{objstorage-full-name}})
To work with S3, you need to set up a data storage connection. There is a DDL for configuring such connections. Next, let's look at the SQL syntax and the management of these settings.
@@ -21,8 +21,8 @@ CREATE EXTERNAL DATA SOURCE object_storage WITH (
To set up a connection to a private bucket, you need to run a few SQL queries. First, create [secrets](../../datamodel/secrets.md) containing `AWS_ACCESS_KEY_ID` and `AWS_SECRET_ACCESS_KEY`.
```yql
- CREATE OBJECT aws_access_id (TYPE SECRET) WITH (value=``);
- CREATE OBJECT aws_access_key (TYPE SECRET) WITH (value=``);
+CREATE OBJECT aws_access_id (TYPE SECRET) WITH (value=``);
+CREATE OBJECT aws_access_key (TYPE SECRET) WITH (value=``);
```
The next step is to create an external connection named `object_storage`, which points to a specific S3 bucket named `bucket` and uses `AUTH_METHOD="AWS"`. The parameters `AWS_ACCESS_KEY_ID_SECRET_NAME`, `AWS_SECRET_ACCESS_KEY_SECRET_NAME`, and `AWS_REGION` are filled in for `AWS`. The values of these parameters are described above.
@@ -38,7 +38,7 @@ CREATE EXTERNAL DATA SOURCE object_storage WITH (
);
```
-## Using an external connection to an S3 bucket {#external-data-source-settings}
+## Using an External Connection to an S3 Bucket {#external-data-source-settings}
When working with {{ objstorage-full-name }} using [external data sources](../../datamodel/external_data_source.md), it is convenient to perform prototyping and initial data connection setup.
@@ -62,7 +62,7 @@ WITH
The list of supported formats and data compression algorithms for reading data in S3 ({{objstorage-full-name}}) is provided in the section [{#T}](formats.md).
-## Data model {#data_model}
+## Data Model {#data_model}
In {{ objstorage-full-name }}, data is stored in files. To read data, you need to specify the data format in the files, compression, and lists of fields. This is done using the following SQL expression:
@@ -89,7 +89,7 @@ Where:
* `schema_definition` — the [schema definition](#schema) of the data stored in the files.
* `format_settings` — optional [format settings](#format_settings)
-### Data schema description {#schema}
+### Data Schema Description {#schema}
The data schema description consists of a set of fields:
@@ -103,9 +103,9 @@ For example, the data schema below describes a schema field named `Year` of type
Year Int32 NOT NULL
```
-If a data field is marked as required (`NOT NULL`) but is missing in the processed file, processing such a file will result in an error. If a field is marked as optional (`NULL`), no error will occur the field is absent in the processed file, but the field will take the value `NULL`. The keyword `NULL` is optional in this context.
+If a data field is marked as required (`NOT NULL`) but is missing in the processed file, processing such a file will result in an error. If a field is marked as optional (`NULL`), no error will occur if the field is absent in the processed file, but the field will take the value `NULL`. The keyword `NULL` is optional in this context.
-### Schema inference {#inference}
+### Schema Inference {#inference}
{{ ydb-short-name }} can determine the data schema of the files inside the bucket so that you do not have to specify these fields manually.
@@ -133,19 +133,19 @@ WHERE
Where:
* `object_storage_connection_name` — the name of the external data source leading to the S3 bucket ({{ objstorage-full-name }}).
-* `file_path` — the path to the file or files inside the bucket. Wildcards `*` are supported; For more information, see [{#T}](#path_format).
+* `file_path` — the path to the file or files inside the bucket. Wildcards `*` are supported. For more information, see [{#T}](#path_format).
* `file_format` — the [data format](formats.md#formats) in the files. All formats except `raw` and `json_as_string` are supported.
* `compression` — the [compression format](formats.md#compression_formats) of the files.
As a result of executing such a query, the names and types of fields will be inferred.
-### Data path formats specified in `file_path` {#path_format}
+### Data Path Formats Specified in `file_path` {#path_format}
In {{ ydb-full-name }}, the followingdata paths are supported:
{% include [!](_includes/path_format.md) %}
-### Format settings {#format_settings}
+### Format Settings {#format_settings}
In {{ ydb-full-name }}, the following format settings are supported:
diff --git a/ydb/docs/en/core/concepts/federated_query/s3/external_table.md b/ydb/docs/en/core/concepts/federated_query/s3/external_table.md
index b3787c3500a3..6cd135ce01b7 100644
--- a/ydb/docs/en/core/concepts/federated_query/s3/external_table.md
+++ b/ydb/docs/en/core/concepts/federated_query/s3/external_table.md
@@ -1,4 +1,4 @@
-# Reading data from an external table pointing to S3 ({{ objstorage-name }})
+# Reading Data from an External Table Pointing to S3 ({{ objstorage-name }})
Sometimes, the same data queries need to be executed regularly. To avoid specifying all the details of working with this data every time a query is called, use the mode with [external tables](../../datamodel/external_table.md). In this case, the query looks like a regular query to {{ydb-full-name}} tables.
@@ -13,7 +13,7 @@ WHERE
version > 1
```
-## Creating an external table pointing to an S3 bucket ({{ objstorage-name }}) {#external-table-settings}
+## Creating an External Table Pointing to an S3 Bucket ({{ objstorage-name }}) {#external-table-settings}
To create an external table describing the S3 bucket ({{ objstorage-name }}), execute the following SQL query. The query creates an external table named `s3_test_data`, containing files in the `CSV` format with string fields `key` and `value`, located inside the bucket at the path `test_folder`, using the connection credentials specified by the [external data source](../../datamodel/external_data_source.md) object `bucket`:
@@ -39,7 +39,7 @@ Where:
You can also specify [format settings](external_data_source.md#format_settings).
-## Data model {#data-model}
+## Data Model {#data-model}
Reading data using external tables from S3 ({{ objstorage-name }}) is done with regular SQL queries as if querying a normal table.
diff --git a/ydb/docs/en/core/concepts/federated_query/s3/formats.md b/ydb/docs/en/core/concepts/federated_query/s3/formats.md
index e8acdc123734..712fa6ab816c 100644
--- a/ydb/docs/en/core/concepts/federated_query/s3/formats.md
+++ b/ydb/docs/en/core/concepts/federated_query/s3/formats.md
@@ -1,8 +1,8 @@
-# Data formats and compression algorithms
+# Data Formats and Compression Algorithms
This section describes the data formats supported in {{ ydb-full-name }} for storage in S3 and the supported compression algorithms.
-## Supported data formats {#formats}
+## Supported Data Formats {#formats}
The table below lists the data formats supported in {{ ydb-short-name }}.
@@ -161,7 +161,7 @@ This format is based on the [JSON representation](https://en.wikipedia.org/wiki/
Each file must contain:
-- a JSON object on each line, or
+- A JSON object on each line, or
- JSON objects combined into an array.
Example of valid data (data presented as a list of JSON objects):
@@ -271,7 +271,7 @@ Year,Manufacturer,Model,Price
{% endcut %}
-## Supported compression algorithms {#compression}
+## Supported Compression Algorithms {#compression}
The use of compression algorithms depends on the file formats. For all file formats except Parquet, the following compression algorithms can be used:
@@ -286,7 +286,7 @@ The use of compression algorithms depends on the file formats. For all file form
For Parquet file format, the following internal compression algorithms are supported:
-|Compression format|Name in {{ ydb-full-name }}|Read|Write|
+|Compression Format|Name in {{ ydb-full-name }}|Read|Write|
|--|--|----|-----|
|[Raw](https://en.wikipedia.org/wiki/Gzip)|raw|✓||
|[Snappy](https://en.wikipedia.org/wiki/Snappy_(compression))|snappy|✓|✓|
diff --git a/ydb/docs/en/core/concepts/federated_query/s3/partition_projection.md b/ydb/docs/en/core/concepts/federated_query/s3/partition_projection.md
index d2d01d36f8f6..c232159c08f6 100644
--- a/ydb/docs/en/core/concepts/federated_query/s3/partition_projection.md
+++ b/ydb/docs/en/core/concepts/federated_query/s3/partition_projection.md
@@ -1,6 +1,6 @@
-# Advanced partitioning
+# Eхtended Partitioning in S3 ({{ objstorage-full-name }})
-[Partitioning](partitioning.md) allows you to specify for {{ ydb-full-name }} rules for data placement in S3 ({{ objstorage-full-name }}).
+[Partitioning](partitioning.md) allows you to specify rules for {{ ydb-full-name }} data placement in S3 ({{ objstorage-full-name }}).
Assume the data in S3 ({{ objstorage-full-name }}) is stored in the following directory structure:
@@ -108,7 +108,7 @@ WITH
)
```
-## Field descriptions { #field_types }
+## Field Descriptions { #field_types }
| Field name | Description | Allowed values |
|----------------------------|----------------------------------------------------|--------------------------|
@@ -116,7 +116,7 @@ WITH
| `projection..type` | Data type of the field | `integer`, `enum`, `date`|
| `projection..XXX` | Specific properties of the type | |
-### Integer field type { #integer_type }
+### Integer Field Type { #integer_type }
It is used for columns whose values can be represented as integers ranging from 2^-63^ to 2^63^-1.
@@ -128,7 +128,7 @@ It is used for columns whose values can be represented as integers ranging from
| `projection..interval` | No, default is `1` | Specifies the step between elements within the value range. For example, a step of 3 within the range 2 to 10 will result in the values: 2, 5, 8 | 2
11 |
| `projection..digits` | No, default is `0` | Specifies the number of digits in the number. If the number of significant digits in the number is less than the specified value, the value is padded with leading zeros up to the specified number of digits. For example, if .digits=3 is specified and the number 2 is passed, it will be converted to 002 | 2
4 |
-### Enum field type { #enum_type }
+### Enum Field Type { #enum_type }
It is used for columns whose values can be represented as a set of enumerated values.
@@ -137,7 +137,7 @@ It is used for columns whose values can be represented as a set of enumerated va
| `projection..type` | Yes | Data type of the field | enum |
| `projection..values` | Yes | Specifies the allowable values, separated by commas. Spaces are not ignored | 1, 2
A,B,C |
-### Date field type { #date_type }
+### Date Field Type { #date_type }
It is used for columns whose values can be represented as dates. The allowable date range is from 1970-01-01 to 2105-01-01.
@@ -150,7 +150,7 @@ It is used for columns whose values can be represented as dates. The allowable d
| `projection..unit` | No, default is `DAYS` | Time interval units. Allowed values: `YEARS`, `MONTHS`, `WEEKS`, `DAYS`, `HOURS`, `MINUTES`, `SECONDS`, `MILLISECONDS` | SECONDS
YEARS |
| `projection..interval` | No, default is `1` | Specifies the step between elements within the value range with the specified dimension in `projection..unit`. For example, for the range 2021-02-02 to 2021-03-05 with a step of 15 and the dimension DAYS, the values will be: 2021-02-17, 2021-03-04 | 2
6 |
-## Working with the NOW macro substitution
+## Working with the NOW Macro Substitution
1. A number of arithmetic operations with the NOW macro substitution are supported: adding and subtracting time intervals. For example: `NOW-3DAYS`, `NOW+1MONTH`, `NOW-6YEARS`, `NOW+4HOURS`, `NOW-5MINUTES`, `NOW+6SECONDS`. The possible usage options for the macro substitution are described by the regular expression: `^\s*(NOW)\s*(([\+\-])\s*([0-9]+)\s*(YEARS?|MONTHS?|WEEKS?|DAYS?|HOURS?|MINUTES?|SECONDS?)\s*)?$`
2. Allowed interval dimensions: YEARS, MONTHS, WEEKS, DAYS, HOURS, MINUTES, SECONDS, MILLISECONDS.
@@ -162,7 +162,7 @@ It is used for columns whose values can be represented as dates. The allowable d
- The earliest possible date is `1970-01-01` (time 0 in [Unix time](https://en.wikipedia.org/wiki/Unix_time)). If the result of calculations is a date earlier than the minimum, the entire query fails with an error.
- The latest possible date is `2105-12-31` (the maximum date in [Unix time](https://en.wikipedia.org/wiki/Unix_time)). If the result of calculations is a date later than the maximum, the entire query fails with an error.
-## Path templates { #storage_location_template }
+## Path Templates { #storage_location_template }
Data in S3 ({{objstorage-full-name}}) buckets can be placed in directories with arbitrary names. The `storage.location.template` setting allows you to specify the naming rules for the directories where the data is stored.
@@ -170,4 +170,4 @@ Data in S3 ({{objstorage-full-name}}) buckets can be placed in directories with
|---------------------------|----------------------------------------------------|--------------------------|
| `storage.location.template` | Path template for directory names. The path is specified as a text string with parameter macro substitutions `...${}...${}...` | `root/a/${year}/b/${month}/d`
`${year}/${month}` |
-If the path contains the characters `$`, `\`, or the characters `{}`, they must be escaped with the `\` character. For example, to work with a directory named `my$folder`, it needs to be specified as`my\$folder`.
+If the path contains the characters `$`, `\`, or the characters `{}`, they must be escaped with the `\` character. For example, to work with a directory named `my$folder`, it needs to be specified as `my\$folder`.
diff --git a/ydb/docs/en/core/concepts/federated_query/s3/partitioning.md b/ydb/docs/en/core/concepts/federated_query/s3/partitioning.md
index f63ed76d3414..fd8912c71350 100644
--- a/ydb/docs/en/core/concepts/federated_query/s3/partitioning.md
+++ b/ydb/docs/en/core/concepts/federated_query/s3/partitioning.md
@@ -1,4 +1,4 @@
-# Data partitioning in S3 ({{ objstorage-full-name }})
+# Data Partitioning in S3 ({{ objstorage-full-name }})
In S3 ({{ objstorage-full-name }}), it is possible to store very large volumes of data. At the same time, queries to this data may not need to touch all the data but only a part of it. If you describe the rules for marking the storage structure of your data in {{ydb-full-name}}, then data that is not needed for the query can even be skipped from being read from S3 ({{ objstorage-full-name }}). This mechanism significantly speeds up query execution without affecting the result.
@@ -66,7 +66,7 @@ The example above shows working with data at the level of [connections](../../da
{% endnote %}
-## Syntax { #syntax }
+## Syntax {#syntax}
When working at the connection level, partitioning is set using the `partitioned_by` parameter, where the list of columns is specified in JSON format.
@@ -107,7 +107,7 @@ month=03
year=2021
```
-## Supported data types
+## Supported Data Types
Partitioning is possible only with the following set of YQL data types:
@@ -117,7 +117,7 @@ Partitioning is possible only with the following set of YQL data types:
When using other types for specifying partitioning, an error is returned.
-## Supported storage path formats
+## Supported Storage Path Formats
The storage path format, where the name of each directory explicitly specifies the column name, is called the "[Hive-Metastore format](https://en.wikipedia.org/wiki/Apache_Hive)" or simply the "Hive format."
diff --git a/ydb/docs/en/core/concepts/federated_query/s3/write_data.md b/ydb/docs/en/core/concepts/federated_query/s3/write_data.md
index e6e100bd9dfb..a0356dee2135 100644
--- a/ydb/docs/en/core/concepts/federated_query/s3/write_data.md
+++ b/ydb/docs/en/core/concepts/federated_query/s3/write_data.md
@@ -1,8 +1,8 @@
-# Writing data to S3 buckets ({{ objstorage-full-name }})
+# Writing Data to S3 Buckets ({{ objstorage-full-name }})
In {{ ydb-full-name }}, you can use [external connections](#connection-write) or [external tables](#external-table-write) to write data to the {{ objstorage-full-name }} bucket.
-## Writing data via external connection {#connection-write}
+## Writing Data via External Connection {#connection-write}
Using connections for data writing is convenient for prototyping and initial setup. The SQL expression demonstrates writing data directly to an external data source.
@@ -20,7 +20,7 @@ The data will be written to the specified path. In this mode, the resulting file
When working with external connections, only read (`SELECT`) and insert (`INSERT`) operations are possible; other types of operations are not supported.
-## Writing data via external tables {#external-table-write}
+## Writing Data via External Tables {#external-table-write}
If you need to write data regularly, doing this using external tables is convenient. In this case, there is no need to specify all the details of working with this data in each query. To write data to the bucket, create an [external table](external_table.md) in S3 ({{ objstorage-full-name }}) and use the usual SQL `INSERT INTO` statement:
diff --git a/ydb/docs/en/core/concepts/federated_query/ydb.md b/ydb/docs/en/core/concepts/federated_query/ydb.md
index 852b8edc76c6..c7ad01c866d9 100644
--- a/ydb/docs/en/core/concepts/federated_query/ydb.md
+++ b/ydb/docs/en/core/concepts/federated_query/ydb.md
@@ -1,10 +1,10 @@
-# Working with {{ ydb-short-name }} databases
+# Working with {{ ydb-short-name }} Databases
{{ ydb-full-name }} can act as an external data source for another {{ ydb-full-name }} database. This section discusses the organization of collaboration between two independent {{ ydb-short-name }} databases in federated query processing mode.
To connect to an external {{ ydb-short-name }} database from another {{ ydb-short-name }} database acting as the federated query engine, the following steps need to be performed on the latter:
-1. Prepare authentication data to access the remote {{ ydb-short-name }} database. Currently, in federated queries to {{ ydb-short-name }}, the only available authentication method is [login and password](../../security/authentication.md#static-credentials) (other methods are not supported). The password to the external database is stored as a [secret](../datamodel/secrets.md):
+1. Prepare authentication data to access the remote {{ ydb-short-name }} database. Currently, in federated queries to {{ ydb-short-name }}, the only available authentication method is [login and password](../../security/authentication.md#static-credentials) (other methods are not supported). The password to the external database is stored as a [secret](../datamodel/secrets.md):
```yql
CREATE OBJECT ydb_datasource_user_password (TYPE SECRET) WITH (value = "");
@@ -27,7 +27,7 @@ To connect to an external {{ ydb-short-name }} database from another {{ ydb-shor
3. {% include [!](_includes/connector_deployment.md) %}
4. [Execute a query](#query) to the external data source.
-## Query syntax {#query}
+## Query Syntax {#query}
To retrieve data from tables of the external {{ ydb-short-name }} database, the following form of SQL query is used:
@@ -69,7 +69,7 @@ There are several limitations when working with external {{ ydb-short-name }} da
|`String`|
|`Utf8`|
-## Supported data types
+## Supported Data Types
When working with tables located in the external {{ ydb-short-name }} database, users have access to a limited set of data types. All other types, except for those listed below, are not supported. In some cases the type conversion is performed, meaning that the columns of the table from the external {{ ydb-short-name }} database may change their type after being read by the {{ ydb-short-name }} database processing the federated query.
diff --git a/ydb/docs/en/core/concepts/index.md b/ydb/docs/en/core/concepts/index.md
index 1b1f91c0b653..ad9b169e2afd 100644
--- a/ydb/docs/en/core/concepts/index.md
+++ b/ydb/docs/en/core/concepts/index.md
@@ -4,6 +4,6 @@
{% include [concepts/index/how_it_works.md](_includes/index/how_it_works.md) %}
-## What's next?
+## What's Next?
If you are interested in more specifics about various aspects of YDB, check out neighboring articles in this documentation section. If you are ready to jump into more practical content, you can continue to the [quick start](../quickstart.md) or [YQL](../dev/yql-tutorial/index.md) tutorials.
\ No newline at end of file
diff --git a/ydb/docs/en/core/concepts/mvcc.md b/ydb/docs/en/core/concepts/mvcc.md
index fa0684c5d1fb..b6109730fbad 100644
--- a/ydb/docs/en/core/concepts/mvcc.md
+++ b/ydb/docs/en/core/concepts/mvcc.md
@@ -2,25 +2,25 @@
This article describes how {{ ydb-short-name }} uses MVCC.
-## {{ ydb-short-name }} transactions
+## {{ ydb-short-name }} Transactions
-{{ ydb-short-name }} transactions run at serializable isolation level by default, which in layman's terms means it's as if they executed in some serial order without overlapping. While technically any order is allowed, in practice, {{ ydb-short-name }} also guarantees non-stale reads (modifications committed before the transaction started will be visible). With {{ ydb-short-name }} you may run these transactions interactively (users may have client-side logic between queries), which uses optimistic locks for conflict detection. When two transactions overlap in time and have conflicts (e.g. both transactions read the same key, observe its current value, and then try to update it) one of them will commit successfully, but the other will abort and will need to be retried.
+{{ ydb-short-name }} transactions run at serializable isolation level by default, which in layman's terms means it's as if they executed in some serial order without overlapping. While technically any order is allowed, in practice, {{ ydb-short-name }} also guarantees non-stale reads (modifications committed before the transaction started will be visible). With {{ ydb-short-name }} you may run these transactions interactively (users may have client-side logic between queries), which uses optimistic locks for conflict detection. When two transactions overlap in time and have conflicts (e.g., both transactions read the same key, observe its current value, and then try to update it), one of them will commit successfully, but the other will abort and will need to be retried.
{{ ydb-short-name }} is a distributed database that splits OLTP tables into DataShard tablets, partitioned using the table's primary key, and each storing up to ~2GB of user data. Tablets are fault-tolerant replicated state machines over the shared log and shared storage, which may quickly migrate between different compute nodes. DataShards tablets implement low-level APIs for accessing corresponding partition data and support distributed transactions.
Distributed transactions in {{ ydb-short-name }} are based on the ideas of [Calvin](https://cs.yale.edu/homes/thomson/publications/calvin-sigmod12.pdf), distributing deterministic transactions across multiple participants using a predetermined order of transactions. Every participant receives a substream of the global transaction stream (that involves this participant). Since each participant receives deterministic transactions in the same relative order, the database as a whole eventually reaches a consistent deterministic state (where each participant reached the same decision to commit or abort), even when different participants execute their substreams at different speeds. It's important to note that this does not make {{ ydb-short-name }} eventually consistent and transactions always observe a consistent state at their point in time. Deterministic distributed transactions have a limitation in that they need to know all participants ahead of time, but {{ ydb-short-name }} uses them as a building block, executing multiple deterministic transactions as phases of a larger user transaction. In practice, only the final commit phase runs as a distributed transaction since {{ ydb-short-name }} tries to transform other phases into simple single-shard operations as much as possible while preserving serializable isolation guarantees.
-Having a predetermined order of transactions becomes a concurrency bottleneck, as when you have a slow transaction that has to wait for something, all transactions down the line have to wait as well. This necessitates a good out-of-order execution engine, that is able to reorder transactions that don't conflict while preserving externally visible guarantees. Out-of-order execution alone can't help when transactions actually conflict, however. One example from the past is when a wide read was waiting for data from a disk it blocked all writes that fell into the same range, stalling the pipeline. Implementing MVCC reads lifted that restriction.
+Having a predetermined order of transactions becomes a concurrency bottleneck, as when you have a slow transaction that has to wait for something, all transactions down the line have to wait as well. This necessitates a good out-of-order execution engine that is able to reorder transactions that don't conflict while preserving externally visible guarantees. Out-of-order execution alone can't help when transactions actually conflict, however. One example from the past is when a wide read was waiting for data from a disk, it blocked all writes that fell into the same range, stalling the pipeline. Implementing MVCC reads lifted that restriction.
-## What is MVCC
+## What Is MVCC
-MVCC (Multi-Version Concurrency Control) is a way to improve database concurrency by storing multiple row versions as they have been at different points in time. This allows readers to keep reading from a database snapshot without blocking writers. Databases don't overwrite rows but make a modified copy of them instead, tagged with some version information, keeping older row versions intact. Older row versions are garbage collected eventually, e.g. when there are no readers left that could possibly read them.
+MVCC (Multi-Version Concurrency Control) is a way to improve database concurrency by storing multiple row versions as they have been at different points in time. This allows readers to keep reading from a database snapshot without blocking writers. Databases don't overwrite rows but make a modified copy of them instead, tagged with some version information, keeping older row versions intact. Older row versions are garbage collected eventually, e.g., when there are no readers left that could possibly read them.
-A simple and naive way of adding MVCC to a sorted KV store is to store multiple values for each key, e.g. using keys tagged with a version suffix and skipping versions that are not visible to the current transaction/snapshot. Many databases go this route one way or another. Bear in mind, that such a naive approach leads to data bloat, as multiple copies of data need to be stored and older versions may be difficult to find and remove. It also causes degraded range query performance, as the query execution engine needs to skip over many unnecessary versions, until it finds the right one, or until it finds the next key.
+A simple and naive way of adding MVCC to a sorted KV store is to store multiple values for each key, e.g., using keys tagged with a version suffix and skipping versions that are not visible to the current transaction/snapshot. Many databases go this route one way or another. Bear in mind that such a naive approach leads to data bloat, as multiple copies of data need to be stored and older versions may be difficult to find and remove. It also causes degraded range query performance, as the query execution engine needs to skip over many unnecessary versions until it finds the right one or until it finds the next key.
-## Why {{ ydb-short-name }} needs MVCC
+## Why {{ ydb-short-name }} Needs MVCC
-{{ ydb-short-name }} table shards store data in a sorted KV store, implemented as a write-optimized [LSM tree](glossary.md#lsm-tree), and historically they did not use MVCC. Since the order of transactions is predetermined externally (using Coordinators, somewhat similar to sequencers in the original Calvin paper), {{ ydb-short-name }} heavily relies on reordering transaction execution at each participant, which is correct as long as such reordering cannot be observed externally, and it doesn't change the final outcome. Without MVCC reordering is impeded by read-write conflicts, e.g. when a write cannot start execution until a particularly wide read is complete. With MVCC writes no longer need to wait for conflicting reads to complete, and reads only ever need to wait for preceding conflicting writes to commit. This makes the out-of-order engine's job easier and improves the overall throughput.
+{{ ydb-short-name }} table shards store data in a sorted KV store, implemented as a write-optimized [LSM tree](glossary.md#lsm-tree), and historically they did not use MVCC. Since the order of transactions is predetermined externally (using Coordinators, somewhat similar to sequencers in the original Calvin paper), {{ ydb-short-name }} heavily relies on reordering transaction execution at each participant, which is correct as long as such reordering cannot be observed externally, and it doesn't change the final outcome. Without MVCC, reordering is impeded by read-write conflicts, e.g., when a write cannot start execution until a particularly wide read is complete. With MVCC, writes no longer need to wait for conflicting reads to complete, and reads only ever need to wait for preceding conflicting writes to commit. This makes the out-of-order engine's job easier and improves the overall throughput.
| Timestamp | Statement | Without MVCC | With MVCC | Description |
| --- | --- | --- | --- | --- |
@@ -31,44 +31,44 @@ A simple and naive way of adding MVCC to a sorted KV store is to store multiple
{{ ydb-short-name }} without MVCC also had to take additional steps to preserve data consistency. Interactive transactions may consist of multiple read operations, where each read was performed at a different point in time, and {{ ydb-short-name }} had to perform special checks to ensure conflicting transactions did not perform writes between the read and commit time. This was not ideal for our users, as even pure read-only transactions were often failing with serializability errors and had to be retried.
-After implementing MVCC using global versions (shared with deterministic distributed transactions), it became possible to perform reads in a transaction using a global snapshot. This means pure read-only transactions no longer fail with serializability errors and rarely need to be retried by the user, improving throughput in read-heavy use cases. Transactions also acquired a "repeatable read" property, which means if you perform several selects from the same table transaction will not fail and observe the same (globally consistent) result.
+After implementing MVCC using global versions (shared with deterministic distributed transactions), it became possible to perform reads in a transaction using a global snapshot. This means pure read-only transactions no longer fail with serializability errors and rarely need to be retried by the user, improving throughput in read-heavy use cases. Transactions also acquired a "repeatable read" property, which means if you perform several selects from the same table, the transaction will not fail and will observe the same (globally consistent) result.

-## How {{ ydb-short-name }} stores MVCC data
+## How {{ ydb-short-name }} Stores MVCC Data
DataShard tablets currently store a single table partition in a write-optimized LSM tree, where for each primary key we store row operation with a set of column updates. During searches, we merge updates from multiple levels and get the final row state. Compactions similarly merge updates from multiple levels and write a resulting aggregate row update.
-One of our design goals when adding MVCC was minimal degradation to existing workloads, and that meant queries, especially range queries, with the most recent version needed to be fast. That meant using common approaches like adding a version suffix to keys was out of the question. Instead, when a row in an [SST](glossary.md#sst) (sorted string table, part of an LSM tree) has multiple versions we only store the most recent version in the main data page, marking it with a flag signaling "history" data is present. Older row versions are stored in a special "history" companion SST, where for each marked row id we store row versions in descending order. When we read from a snapshot, we detect if the most recent row version is too recent, and perform a binary search in the history SST instead. Once we found a row version corresponding to a snapshot we apply its updates to the final row state. We also use the fact that LSM tree levels roughly correspond to their write time, allowing us to stop searching once the first matching row is found for a given snapshot. For each level below that we only need to apply the most recent row to the final row state, which limits the number of merges to at most the number of levels, which is usually small.
+One of our design goals when adding MVCC was minimal degradation to existing workloads, and that meant queries, especially range queries, with the most recent version needed to be fast. That meant using common approaches like adding a version suffix to keys was out of the question. Instead, when a row in an [SST](glossary.md#sst) (sorted string table, part of an LSM tree) has multiple versions, we only store the most recent version in the main data page, marking it with a flag signaling "history" data is present. Older row versions are stored in a special "history" companion SST, where for each marked row id we store row versions in descending order. When we read from a snapshot, we detect if the most recent row version is too recent and perform a binary search in the history SST instead. Once we find a row version corresponding to a snapshot, we apply its updates to the final row state. We also use the fact that LSM tree levels roughly correspond to their write time, allowing us to stop searching once the first matching row is found for a given snapshot. For each level below that, we only need to apply the most recent row to the final row state, which limits the number of merges to at most the number of levels, which is usually small.

-Rows in SSTs are effectively deltas, nonetheless, they are stored as pre-merged from the viewpoint of a given SST, which helps with both search and compaction complexity. Let's imagine a hypothetical situation where the user writes 1 million updates to some key K, each time modifying one of a multitude of columns. As a write-optimized storage, we prefer blind writes and don't read the full row before updating and writing a new updated row, instead, we write an update that says "update column C for key K". If we didn't store pre-merged state at each level, soon there would have been 1 million deltas for the key K, each at a different version. Then each read would potentially need to consider applying all 1 million deltas to the row. Instead, we merge updates at the same level into aggregate updates, starting with memtable (where the previous row state is always in memory and we don't need to read from disk). When compacting several levels into a new SST we only need to iterate over each update version and merge it with the most recent version in the SSTs below, this limits either merge complexity at compaction (the number of merges for each version is limited by the number of levels) and at read time, while still allowing us to perform blind writes.
+Rows in SSTs are effectively deltas; nonetheless, they are stored as pre-merged from the viewpoint of a given SST, which helps with both search and compaction complexity. Let's imagine a hypothetical situation where the user writes 1 million updates to some key K, each time modifying one of a multitude of columns. As a write-optimized storage, we prefer blind writes and don't read the full row before updating and writing a new updated row; instead, we write an update that says "update column C for key K". If we didn't store pre-merged state at each level, soon there would have been 1 million deltas for the key K, each at a different version. Then each read would potentially need to consider applying all 1 million deltas to the row. Instead, we merge updates at the same level into aggregate updates, starting with memtable (where the previous row state is always in memory and we don't need to read from disk). When compacting several levels into a new SST, we only need to iterate over each update version and merge it with the most recent version in the SSTs below; this limits either merge complexity at compaction (the number of merges for each version is limited by the number of levels) and at read time, while still allowing us to perform blind writes.

Eventually, we mark version ranges as deleted and no longer readable, after which compactions allow us to garbage collect unnecessary row versions automatically (unreachable versions are skipped over and not emitted when writing new SSTs). We also store a small per-version histogram for each SST, so we can detect when too much unnecessary data accumulates in the LSM tree and trigger additional compactions for garbage collection.
-## How {{ ydb-short-name }} uses MVCC
+## How {{ ydb-short-name }} Uses MVCC
MVCC allows DataShards to improve the reordering of transactions, but we can do even better by leveraging global snapshots, so we use global timestamps as version tags, which correspond to global order already used by deterministic distributed transactions. This allows us to create global snapshots by choosing a correct global timestamp. Using such snapshots to read from DataShards effectively allows the database to observe a consistent snapshot at that point in logical time.
-When we perform the first read in an interactive or multi-stage transaction, we choose a snapshot timestamp that is guaranteed to include all previously committed transactions. Currently, this is just a timestamp that corresponds to the last timestamp sent out by Coordinators. This timestamp may be slightly in the future (as some transactions in-flight from Coordinators to DataShards may not have started executing yet), but usually not by much, and since transactions are inflight they are expected to be executed soon. Most importantly this timestamp is guaranteed to be equal to or larger than any commit timestamp already observed by the client, so when this timestamp is generated for new reads, those reads are guaranteed to include all previously finished writes.
+When we perform the first read in an interactive or multi-stage transaction, we choose a snapshot timestamp that is guaranteed to include all previously committed transactions. Currently, this is just a timestamp that corresponds to the last timestamp sent out by Coordinators. This timestamp may be slightly in the future (as some transactions in-flight from Coordinators to DataShards may not have started executing yet), but usually not by much, and since transactions are inflight, they are expected to be executed soon. Most importantly, this timestamp is guaranteed to be equal to or larger than any commit timestamp already observed by the client, so when this timestamp is generated for new reads, those reads are guaranteed to include all previously finished writes.
We then use this snapshot for reads without any additional coordination between participants, as snapshots are already guaranteed to be globally consistent across the database. To guarantee snapshots include all relevant changes and are not modified later, DataShards may need to wait until they received all write transactions that must have happened before that snapshot, but only conflicting writes need to execute before the read may start. DataShards also guarantee that any data observed by the snapshot is frozen and won't be modified later by concurrent transactions (effectively guaranteeing repeatable read), but this only applies to observed changes. Anything not yet observed is in a state of flux and is free to be modified until logical time advances well past the snapshot at every participant in the database. An interesting consequence of this is that some later writes may be reordered before the snapshot, which is allowed under serializable snapshot isolation.
-When interactive transactions perform writes their changes are buffered and the final distributed commit transaction checks (using optimistic locks) that transaction did not have any conflicting changes between its read (snapshot) and commit time, which effectively simulates moving all reads forward to the commit point in time, only committing when it's possible. Interactive transactions also detect when they read from "history" data and mark such transactions as read-only, since we already know moving this read forward in time (to a future commit timestamp) would be impossible. If a user attempts to perform writes in such a transaction we return a serialization error without any additional buffering or communication. If it turns out a transaction was read-only there's no serialization violation (we have been reading from a consistent snapshot after all), and we only need to perform some cleanup, returning success to the user. Before {{ ydb-short-name }} introduced global MVCC snapshots we had to always check locks at commit time, which made it a struggle to perform wide reads under a heavy write load.
+When interactive transactions perform writes, their changes are buffered and the final distributed commit transaction checks (using optimistic locks) that the transaction did not have any conflicting changes between its read (snapshot) and commit time, which effectively simulates moving all reads forward to the commit point in time, only committing when it's possible. Interactive transactions also detect when they read from "history" data and mark such transactions as read-only, since we already know moving this read forward in time (to a future commit timestamp) would be impossible. If a user attempts to perform writes in such a transaction, we return a serialization error without any additional buffering or communication. If it turns out a transaction was read-only, there's no serialization violation (we have been reading from a consistent snapshot after all), and we only need to perform some cleanup, returning success to the user. Before {{ ydb-short-name }} introduced global MVCC snapshots, we had to always check locks at commit time, which made it a struggle to perform wide reads under a heavy write load.
-## Keeping fast KeyValue performance
+## Keeping Fast KeyValue Performance
-While {{ ydb-short-name }} supports complicated distributed transactions between multiple shards and tables, it's important to also support fast single-shard transactions. Internally such transactions are called "immediate" and they historically don't use any additional coordination. For example when a transaction only reads or writes a single key in a table we only want to communicate with a single shard that the key belongs to and nothing else. At first glance it runs contrary to the use of global MVCC timestamps, however, we may use local uncoordinated timestamps (possibly different at each DataShard), which are still correct global timestamps. Each distributed transaction is assigned a timestamp that consists of two numbers (step, txId), where a step is a coordination tick, often configured to increase every 10ms, and txId is a globally unique transaction id. Immediate transactions don't have a step, since they are not processed by coordinators, and while txId is unique it is not guaranteed to always increase, so we cannot use it for write timestamps without risking these timestamps going back in time. There's an important distinction, however, since immediate transactions don't have to be repeatable, their read/write timestamp does not have to be unique. That's why we allow them to share a timestamp with some next transaction in the queue (effectively executing "just before" that transaction). When the queue is empty we use a broadcasted coordinator time (the maximum step acknowledged by shards, so shard is guaranteed there will be no transactions up to that step's end) and a maximum number as txId (effectively executing "just before" that step ends).
+While {{ ydb-short-name }} supports complicated distributed transactions between multiple shards and tables, it's important to also support fast single-shard transactions. Internally such transactions are called "immediate" and they historically don't use any additional coordination. For example, when a transaction only reads or writes a single key in a table, we only want to communicate with a single shard that the key belongs to and nothing else. At first glance, it runs contrary to the use of global MVCC timestamps; however, we may use local uncoordinated timestamps (possibly different at each DataShard), which are still correct global timestamps. Each distributed transaction is assigned a timestamp that consists of two numbers (step, txId), where a step is a coordination tick, often configured to increase every 10ms, and txId is a globally unique transaction id. Immediate transactions don't have a step, since they are not processed by coordinators, and while txId is unique, it is not guaranteed to always increase, so we cannot use it for write timestamps without risking these timestamps going back in time. There's an important distinction, however, since immediate transactions don't have to be repeatable, their read/write timestamp does not have to be unique. That's why we allow them to share a timestamp with some next transaction in the queue (effectively executing "just before" that transaction). When the queue is empty, we use a broadcasted coordinator time (the maximum step acknowledged by shards, so shard is guaranteed there will be no transactions up to that step's end) and a maximum number as txId (effectively executing "just before" that step ends).
Assigning such non-unique timestamps to immediate transactions guarantees there's always some new non-decreasing timestamp that allows them to execute without delay (subject to other out-of-order execution restrictions). It also helps with compactions, as we may have thousands of these transactions executed at the same timestamp, and all of that history is compacted into a single final row version for that step. This allows us to only keep versions in history that need to be consistent across multiple shards.
-## Prioritizing reads
+## Prioritizing Reads
-An interesting conundrum happened when we tried to enable MVCC snapshots for the first time, there was a severe degradation in read latency under some workloads! This was because time in {{ ydb-short-name }} usually "ticks" every 10ms (tuned to be similar on par with typical multi-datacenter commit time of 4ms), and single-shard writes use "current time" as part of their timestamp. This meant snapshot reads had to wait for the next tick until the read timestamp is "closed" for new writes, as well as make sure it is actually safe. This added quite a bit of latency to reads, which in hindsight was entirely expected.
+An interesting conundrum happened when we tried to enable MVCC snapshots for the first time: there was a severe degradation in read latency under some workloads! This was because time in {{ ydb-short-name }} usually "ticks" every 10ms (tuned to be similar to typical multi-datacenter commit time of 4ms), and single-shard writes use "current time" as part of their timestamp. This meant snapshot reads had to wait for the next tick until the read timestamp is "closed" for new writes, as well as make sure it is actually safe. This added quite a bit of latency to reads, which in hindsight was entirely expected.
-We had to go back to the drawing board and find ways to prioritize reads without penalizing writes too much. What we ended up doing was to "close" the read timestamp as soon as we perform a repeatable snapshot read, while choosing some "future" timestamp for new single-shard writes, that is guaranteed to not corrupt previously read snapshots (ensuring repeatable read). However, since that write timestamp is in the future, and we must ensure any new snapshot includes committed data, we delay responses until that future timestamp matches the current timestamp, and pretend this new data is not committed (e.g. when running concurrent single-shard reads) until timestamps finally match. Interestingly, since writes are already in flight to storage and must be committed first in at least one other datacenter, this wait did not add much to average write latency even with many snapshot reads, but it did wonders to read latency:
+We had to go back to the drawing board and find ways to prioritize reads without penalizing writes too much. What we ended up doing was to "close" the read timestamp as soon as we perform a repeatable snapshot read, while choosing some "future" timestamp for new single-shard writes that is guaranteed to not corrupt previously read snapshots (ensuring repeatable read). However, since that write timestamp is in the future, and we must ensure any new snapshot includes committed data, we delay responses until that future timestamp matches the current timestamp, and pretend this new data is not committed (e.g., when running concurrent single-shard reads) until timestamps finally match. Interestingly, since writes are already in flight to storage and must be committed first in at least one other datacenter, this wait did not add much to average write latency even with many snapshot reads, but it did wonders to read latency:

diff --git a/ydb/docs/en/core/concepts/optimizer.md b/ydb/docs/en/core/concepts/optimizer.md
index 4ce07b72bdbf..0b6eed167bba 100644
--- a/ydb/docs/en/core/concepts/optimizer.md
+++ b/ydb/docs/en/core/concepts/optimizer.md
@@ -1,16 +1,16 @@
-# Query optimization in {{ ydb-short-name }}
+# Query Optimization in {{ ydb-short-name }}
{{ ydb-short-name }} uses two types of query optimizers: a rule-based optimizer and a cost-based optimizer. The cost-based optimizer is used for complex queries, typically analytical ([OLAP](https://en.wikipedia.org/wiki/Online_analytical_processing)), while rule-based optimization works on all queries.
A query plan is a graph of operations, such as reading data from a source, filtering a data stream by a predicate, or performing more complex operations such as [JOIN](../yql/reference/syntax/join.md) and [GROUP BY](../yql/reference/syntax/group_by.md). Optimizers in {{ ydb-short-name }} take an initial query plan as input and transform it into a more efficient plan that is equivalent to the initial one in terms of the returned result.
-## Rule-based optimizer
+## Rule-Based Optimizer
A significant part of the optimizations in {{ ydb-short-name }} applies to almost any query plan, eliminating the need to analyze alternative plans and their costs. The rule-based optimizer consists of a set of heuristic rules that are applied whenever possible. For example, it is beneficial to filter out data as early as possible in the execution plan for any query. Each optimizer rule comprises a condition that triggers the rule and a rewriting logic that is executed when the plan is applied. Rules are applied iteratively as long as any rule conditions match.
## Cost-Based Query Optimizer
-The cost-based optimizer is used for more complex optimizations, such as choosing an optimal join order and join algorithms. The cost-based optimizer considers a large number of alternative execution plans for each query and selects the best one based on the cost estimate for each option. Currently, this optimizer only works with plans that contain [JOIN](../yql/reference/syntax/join.md) operations. It chooses the best order for these operations and the most efficient algotithm implementation for each join operation in the plan.
+The cost-based optimizer is used for more complex optimizations, such as choosing an optimal join order and join algorithms. The cost-based optimizer considers a large number of alternative execution plans for each query and selects the best one based on the cost estimate for each option. Currently, this optimizer only works with plans that contain [JOIN](../yql/reference/syntax/join.md) operations. It chooses the best order for these operations and the most efficient algorithm implementation for each join operation in the plan.
The cost-optimizer consists of three main components:
@@ -18,9 +18,9 @@ The cost-optimizer consists of three main components:
* Cost estimation function
* Statistics module, which is used to estimate statistics for the cost function
-### Plan enumerator
+### Plan Enumerator
-The current Cost-based optimizer in {{ ydb-short-name }} enumerates all useful join trees, for which the join conditions are defined. It first builds a join hypergraph, where the nodes are tables and edges are join conditions. Depending on how the original query is written, the join hypergraph may have quite different topologies, ranging from simple chain-like graphs to complex cliques. The resulting topology of the join graph determines how many possible altenative plans need to be considered by the optimizer.
+The current Cost-based optimizer in {{ ydb-short-name }} enumerates all useful join trees, for which the join conditions are defined. It first builds a join hypergraph, where the nodes are tables and edges are join conditions. Depending on how the original query is written, the join hypergraph may have quite different topologies, ranging from simple chain-like graphs to complex cliques. The resulting topology of the join graph determines how many possible alternative plans need to be considered by the optimizer.
For example, a star is a common topology in analytical queries, where a main fact table is joined to multiple dimension tables:
@@ -60,11 +60,11 @@ The topology significantly impacts the number of alternative plans that the opti
{{ ydb-short-name }} uses a modification of the [DPHyp](https://www.researchgate.net/publication/47862092_Dynamic_Programming_Strikes_Back) algorithm to search for the best join order. DPHyp is a modern dynamic programming algorithm for query optimization that avoids enumerating unnecessary alternatives and allows you to optimize plans with `JOIN` operators, complex predicates, and even `GROUP BY` and `ORDER BY` operators.
-### Cost estimation function
+### Cost Estimation Function
To compare plans, the optimizer needs to estimate their costs. The cost function estimates the time and resources required to execute an operation in {{ ydb-short-name }}. The primary parameters of the cost function are estimates of the input data size for each operator and the size of its output. These estimates are based on statistics collected from {{ ydb-short-name }} tables, along with an analysis of the plan itself.
-### Statistics for the cost-based optimizer {#statistics}
+### Statistics for the Cost-Based Optimizer {#statistics}
The cost-based optimizer relies on table statistics and individual column statistics. {{ ydb-short-name }} collects and maintains these statistics in the background. You can manually force statistics collection using the [ANALYZE](../yql/reference/syntax/analyze.md) query.
@@ -77,6 +77,6 @@ The current set of column statistics includes:
* [Count-min sketch](https://en.wikipedia.org/wiki/Count%E2%80%93min_sketch)
-### Cost optimization levels
+### Cost Optimization Levels
In {{ ydb-short-name }}, you can configure the cost optimization level via the [CostBasedOptimizationLevel](../yql/reference/syntax/pragma.md#costbasedoptimizationlevel) pragma.
\ No newline at end of file
diff --git a/ydb/docs/en/core/concepts/topic.md b/ydb/docs/en/core/concepts/topic.md
index c09ad6dd3095..8a6a7deb61f9 100644
--- a/ydb/docs/en/core/concepts/topic.md
+++ b/ydb/docs/en/core/concepts/topic.md
@@ -2,7 +2,7 @@
A topic in {{ ydb-short-name }} is an entity for storing unstructured messages and delivering them to multiple subscribers. Basically, a topic is a named set of messages.
-A producer app writes messages to a topic. Consumer apps are independent of each other, they receive and read messages from the topic in the order they were written there. Topics implement the [publish-subscribe]{% if lang == "en" %}(https://en.wikipedia.org/wiki/Publish–subscribe_pattern){% endif %}{% if lang == "ru" %}(https://ru.wikipedia.org/wiki/Издатель-подписчик_(шаблон_проектирования)){% endif %} architectural pattern.
+A producer app writes messages to a topic. Consumer apps are independent of each other, they receive and read messages from the topic in the order they were written there. Topics implement the [publish-subscribe](https://en.wikipedia.org/wiki/Publish–subscribe_pattern) architectural pattern.
{{ ydb-short-name }} topics have the following properties:
@@ -13,7 +13,7 @@ A producer app writes messages to a topic. Consumer apps are independent of each
## Messages {#message}
-Data is transferred as message streams. A message is the minimum atomic unit of user information. A message consists of a body and attributes and additional system properties. The content of a message is an array of bytes which is not interpreted by {{ydb-short-name}} in any way.
+Data is transferred as message streams. A message is the minimum atomic unit of user information. A message consists of a body, attributes, and additional system properties. The content of a message is an array of bytes which is not interpreted by {{ydb-short-name}} in any way.
Messages may contain user-defined attributes in "key-value" format. They are returned along with the message body when reading the message. User-defined attributes let the consumer decide whether it should process the message without unpacking the message body. Message attributes are set when initializing a write session. This means that all messages written within a single write session will have the same attributes when reading them.
@@ -23,7 +23,7 @@ To enable horizontal scaling, a topic is divided into `partitions` that are unit
{% note info %}
-As for now, you can only reduce the number of partitions in a topic by deleting and recreating a topic with a smaller number of partitions.
+As of now, you can only reduce the number of partitions in a topic by deleting and recreating a topic with a smaller number of partitions.
{% endnote %}
@@ -34,11 +34,11 @@ Partitions can be:
### Offset {#offset}
-All messages within a partition have a unique sequence number called an `offset` An offset monotonically increases as new messages are written.
+All messages within a partition have a unique sequence number called an `offset`. An offset monotonically increases as new messages are written.
## Autopartitioning {#autopartitioning}
-Total topic throughput is determined by the number of partitions in the topic and the throughput of each partition. The number of partitions and the throughput of each partition are set at the time of topic creation. If the maximum required write speed for a topic is unknown at the creation time, autopartitioning allows the topic to be scaled automatically. If autopartitioning is enabled for a topic, the number of partitions will increase automatically as the write speed increases (see [Autopartitioning strategies](#autopartitioning_strategies)).
+Total topic throughput is determined by the number of partitions in the topic and the throughput of each partition. The number of partitions and the throughput of each partition are set at the time of topic creation. If the maximum required write speed for a topic is unknown at the creation time, autopartitioning allows the topic to be scaled automatically. If autopartitioning is enabled for a topic, the number of partitions will increase automatically as the write speed increases (see [Autopartitioning Strategies](#autopartitioning_strategies)).
### Guarantees {#autopartitioning_guarantee}
@@ -46,7 +46,7 @@ Total topic throughput is determined by the number of partitions in the topic an
2. The SDK and server maintain the reading order. Data is read from the parent partition first, followed by the child partitions.
3. As a result, the exactly-once writing guarantee and the reading order guarantee are preserved for a specific [producer identifier](#producer-id).
-### Autopartitioning strategies {#autopartitioning_strategies}
+### Autopartitioning Strategies {#autopartitioning_strategies}
The following autopartitioning strategies are available for any topic:
@@ -68,7 +68,7 @@ Autopartitioning is paused for this topic, meaning that the number of partitions
Examples of YQL queries for switching between different autopartitioning strategies can be found [here](../yql/reference/syntax/alter-topic.md#autopartitioning).
-### Autopartitioning constraints {#autopartitioning_constraints}
+### Autopartitioning Constraints {#autopartitioning_constraints}
The following constraints apply when using autopartitioning:
@@ -76,7 +76,7 @@ The following constraints apply when using autopartitioning:
2. When autopartitioning is enabled for a topic, it is impossible to read from or write to it using the [Kafka API](../reference/kafka-api/index.md).
3. Autopartitioning can only be enabled on topics that use the reserved capacity mode.
-## Message sources and groups {#producer-id}
+## Message Sources and Groups {#producer-id}
Messages are ordered using the `producer_id` and `message_group_id`. The order of written messages is maintained within pairs: ``.
@@ -88,9 +88,9 @@ The recommended maximum number of `` pairs is up
{% endnote %}
-{% cut "Why and when the message processing order is important" %}
+{% cut "Why and When the Message Processing Order Is Important" %}
-### When the message processing order is important
+### When the Message Processing Order Is Important
Let's consider a finance application that calculates the balance on a user's account and permits or prohibits debiting the funds.
@@ -98,21 +98,21 @@ For such tasks, you can use a [message queue](https://en.wikipedia.org/wiki/Mess

-To accurately calculate the balance, the message processing order is crucial. If a user first tops up their account and then makes a purchase, messages with details about these transactions must be processed by the app in the same order. Otherwise there may be an error in the business logic and the app will reject the purchase as a result of insufficient funds. There are guaranteed delivery order mechanisms, but they cannot ensure a message order within a single queue on an arbitrary data amount.
+To accurately calculate the balance, the message processing order is crucial. If a user first tops up their account and then makes a purchase, messages with details about these transactions must be processed by the app in the same order. Otherwise, there may be an error in the business logic and the app will reject the purchase as a result of insufficient funds. There are guaranteed delivery order mechanisms, but they cannot ensure a message order within a single queue on an arbitrary data amount.
When several application instances read messages from a stream, a message about account top-ups can be received by one instance and a message about debiting by another. In this case, there's no guaranteed instance with accurate balance information. To avoid this issue, you can, for example, save data in the DBMS, share information between application instances, and implement a distributed cache.
{{ ydb-short-name }} can write data so that messages from one source (for example, about transactions from one account) arrive at the same application instance. The source of a message is identified by the source_id, while the sequence number of a message from the source is used to ensure there are no duplicate messages. {{ydb-short-name}} arranges data streams so that messages from the same source arrive at the same partition. As a result, transaction messages for a given account will always arrive at the same partition and be processed by the application instance linked to this partition. Each of the instances processes its own subset of partitions and there's no need to synchronize the instances.
-Below is an example when all transactions on accounts with even ids are transferred to the first instance of the application, and with odd ones — to the second.
+Below is an example when all transactions on accounts with even IDs are transferred to the first instance of the application, and with odd ones — to the second.

-### When the processing order is not important {#no-dedup}
+### When the Processing Order Is Not Important {#no-dedup}
For some tasks, the message processing order is not critical. For example, it's sometimes important to simply deliver data that will then be ordered by the storage system.
-For such tasks, the 'no-deduplication' mode can be used. In this scenario neither [`producer_id`](#producer-id) or [`source_id`](#source-id) are specified in write session setup and [`sequence numbers`](#seqno) are also not used for messages. The no-deduplication mode offers better perfomance and requires less server resources, but there is no message ordering or deduplication on the server side, which means that some message sent to the server multiple times (for example due to network instablity or writer process crash) also may be written to the topic multiple times.
+For such tasks, the 'no-deduplication' mode can be used. In this scenario, neither [`producer_id`](#producer-id) nor [`source_id`](#source-id) are specified in write session setup and [`sequence numbers`](#seqno) are also not used for messages. The no-deduplication mode offers better performance and requires fewer server resources, but there is no message ordering or deduplication on the server side, which means that a message sent to the server multiple times (for example, due to network instability or writer process crash) may also be written to the topic multiple times.
{% note warning %}
@@ -126,44 +126,44 @@ We strongly recommend that you don't use random or pseudo-random source IDs. We
A source ID is an arbitrary string up to 2048 characters long. This is usually the ID of a file server or some other ID.
-#### Sample source IDs {#source-id-examples}
+#### Sample Source IDs {#source-id-examples}
| Type | ID | Description |
|--------------| --- |---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| File | Server ID | Files are used to store application logs. In this case, it's convenient to use the server ID as a source ID. |
| User actions | ID of the class of user actions, such as "viewing a page", "making a purchase", and so on. | It's important to handle user actions in the order they were performed by the user. At the same time, there is no need to handle every single user action in one application. In this case, it's convenient to group user actions by class. |
-### Message group ID {#group-id}
+### Message Group ID {#group-id}
A message group ID is an arbitrary string up to 2048 characters long. This is usually a file name or user ID.
-#### Sample message group IDs {#group-id-examples}
+#### Sample Message Group IDs {#group-id-examples}
| Type | ID | Description |
|--------------| --- |------------------------------------------------------------------------------------------------------------------------------------------|
| File | Full file path | All data from the server and the file it hosts will be sent to the same partition. |
| User actions | User ID | It's important to handle user actions in the order they were performed. In this case, it's convenient to use the user ID as a source ID. |
-## Message sequence numbers {#seqno}
+## Message Sequence Numbers {#seqno}
-All messages from the same source have a [`sequence number`](#seqno) used for their deduplication. A message sequence number should monotonically increase within a `topic`, `source` pair. If the server receives a message whose sequence number is less than or equal to the maximum number written for the `topic`, `source` pair, the message will be skipped as a duplicate. Some sequence numbers in the sequence may be skipped. Message sequence numbers must be unique within the `topic`, `source` pair.
+All messages from the same source have a [`sequence number`](#seqno) used for their deduplication. A message sequence number should monotonically increase within a `topic`, `source` pair. If the server receives a message whose sequence number is less than or equal to the maximum number written for the `topic`, `source` pair, the message will be skipped as a duplicate. Some sequence numbers in the sequence may be skipped. Message sequence numbers must be unique within the `topic`, `source` pair.
Sequence numbers are not used if [no-deduplication mode](#no-dedup) is enabled.
-### Sample message sequence numbers {#seqno-examples}
+### Sample Message Sequence Numbers {#seqno-examples}
| Type | Example | Description |
|----------| --- |------------------------------------------------------------------------------------------------------------------------------------|
| File | Offset of transferred data from the beginning of a file | You can't delete lines from the beginning of a file, since this will lead to skipping some data as duplicates or losing some data. |
| DB table | Auto-increment record ID |
-## Message retention period {#retention-time}
+## Message Retention Period {#retention-time}
The message retention period is set for each topic. After it expires, messages are automatically deleted. An exception is data that hasn't been read by an [important](#important-consumer) consumer: this data will be stored until it's read.
-## Data compression {#message-codec}
+## Data Compression {#message-codec}
-When transferring data, the producer app indicates that a message can be compressed using one of the supported codecs. The codec name is passed while writing a message, saved along with it, and returned when reading the message. Compression applies to each individual message, no batch message compression is supported. Data is compressed and decompressed on the producer and consumer apps end.
+When transferring data, the producer app indicates that a message can be compressed using one of the supported codecs. The codec name is passed while writing a message, saved along with it, and returned when reading the message. Compression applies to each individual message, no batch message compression is supported. Data is compressed and decompressed on the producer and consumer apps' end.
Supported codecs are explicitly listed in each topic. When making an attempt to write data to a topic with a codec that is not supported, a write error occurs.
@@ -180,11 +180,11 @@ Supported codecs are explicitly listed in each topic. When making an attempt to
A consumer is a named entity that reads data from a topic. A consumer contains committed consumer offsets for each topic read on their behalf.
-### Consumer offset {#consumer-offset}
+### Consumer Offset {#consumer-offset}
A consumer offset is a saved [offset](#offset) of a consumer by each topic partition. It's saved by a consumer after sending commits of the data read. When a new read session is established, messages are delivered to the consumer starting with the saved consumer offset. This lets users avoid saving the consumer offset on their end.
-### Important consumer {#important-consumer}
+### Important Consumer {#important-consumer}
A consumer may be flagged as "important". This flag indicates that messages in a topic won't be removed until the consumer reads and confirms them. You can set this flag for most critical consumers that need to handle all data even if there's a long idle time.
@@ -194,25 +194,25 @@ As a long timeout of an important consumer may result in full use of all availab
{% endnote %}
-## Topic protocols {#topic-protocols}
+## Topic Protocols {#topic-protocols}
To work with topics, the {{ ydb-short-name }} SDK is used (see also [Reference](../reference/ydb-sdk/topic.md)).
Kafka API version 3.4.0 is also supported with some restrictions (see [Work with Kafka API](../reference/kafka-api/index.md)).
-## Transactions with topics {#topic-transactions}
+## Transactions with Topics {#topic-transactions}
{{ ydb-short-name }} supports working with topics within [transactions](./transactions.md).
-### Read from a topic within a transaction {#topic-transactions-read}
+### Read from a Topic Within a Transaction {#topic-transactions-read}
Topic data does not change during a read operation. Therefore, within transactional reads from a topic, only the offset commit is a true transactional operation. The postponed offset commit occurs automatically at the transaction commit, and the SDK handles this transparently for the user.
-### Write into a topic within a transaction {#topic-transactions-write}
+### Write into a Topic Within a Transaction {#topic-transactions-write}
During transactional writes to a topic, data is stored outside the partition until the transaction is committed. At the transaction commit, the data is published to the partition and appended to the end of the partition with sequential offsets. Changes made within the transaction are not visible in transactions with topics in {{ ydb-short-name }}.
-### Topic transaction constraints {#topic-transactions-constraints}
+### Topic Transaction Constraints {#topic-transactions-constraints}
There are no additional constraints when working with topics within a transaction. It is possible to write large amounts of data to a topic, write to multiple partitions, and read with multiple consumers.
diff --git a/ydb/docs/en/core/concepts/topology.md b/ydb/docs/en/core/concepts/topology.md
index 7b4394ee612e..805216208cb6 100644
--- a/ydb/docs/en/core/concepts/topology.md
+++ b/ydb/docs/en/core/concepts/topology.md
@@ -1,8 +1,8 @@
-# {{ ydb-short-name }} cluster topology
+# {{ ydb-short-name }} Cluster Topology
A {{ ydb-short-name }} cluster consists of [storage](glossary.md#storage-node) and [database](glossary.md#database-node) nodes. As the data stored in {{ ydb-short-name }} is available only via queries and API calls, both types of nodes are essential for [database availability](#database-availability). However, [distributed storage](glossary.md#distributed-storage) consisting of storage nodes has the most impact on the cluster's fault tolerance and ability to persist data reliably. During the initial cluster deployment, an appropriate distributed storage [operating mode](#cluster-config) needs to be chosen according to the expected workload and [database availability](#database-availability) requirements. The operation mode cannot be changed after the initial cluster setup, making it one of the key decisions to consider when planning a new {{ ydb-short-name }} deployment.
-## Cluster operating modes {#cluster-config}
+## Cluster Operating Modes {#cluster-config}
Cluster topology is based on the chosen distributed storage operating mode, which needs to be determined according to the fault tolerance requirements. {{ ydb-short-name }}'s failure model is based on the concepts of [fail domain](glossary.md#fail-domain) and [fail realm](glossary.md#fail-realm).
@@ -43,7 +43,7 @@ The storage volume multiplier specified above only applies to the fault toleranc
For information about how to set the {{ ydb-short-name }} cluster topology, see [{#T}](../reference/configuration/index.md#domains-blob).
-### Reduced configurations {#reduced}
+### Reduced Configurations {#reduced}
If it is impossible to use the [recommended amount](#cluster-config) of hardware, you can divide servers within a single rack into two dummy fail domains. In this configuration, the failure of one rack results in the failure of two domains instead of just one. In such reduced configurations, {{ ydb-short-name }} will continue to operate if two domains fail. The minimum number of racks in a cluster is five for `block-4-2` mode and two per data center (e.g., six in total) for `mirror-3-dc` mode.
@@ -51,7 +51,7 @@ The minimal fault-tolerant configuration of a {{ ydb-short-name }} cluster uses
{{ ydb-short-name }} clusters configured with one of these approaches can be used for production environments if they don't require stronger fault tolerance guarantees.
-## Capacity and performance considerations {#capacity}
+## Capacity and Performance Considerations {#capacity}
The system can function with fail domains of any size. However, if there are few domains with varying numbers of disks, the number of storage groups that can be created will be limited. In such cases, hardware in overly large fail domains may be underutilized. If all hardware is fully utilized, significant differences in domain sizes may prevent reconfiguration.
@@ -70,7 +70,7 @@ Therefore, the optimal initial hardware configurations for production {{ ydb-sho
* **A cluster hosted in one availability zone**: This setup uses the `block-4-2` mode and consists of nine or more racks, each with an identical number of servers.
* **A cluster hosted in three availability zones**: This setup uses the `mirror-3-dc` mode and is distributed across three data centers, with four or more racks in each, all containing an identical number of servers.
-## Database availability {#database-availability}
+## Database Availability {#database-availability}
A [database](glossary.md#database) within a {{ ydb-short-name }} cluster is available if both its storage and compute resources are operational:
@@ -82,11 +82,11 @@ To survive an entire data center outage at the database level, assuming a cluste
- The [storage nodes](glossary.md#storage-node) need to have at least double the I/O bandwidth and disk capacity compared to what is required for normal operation. In the worst case, the load on the remaining nodes during the maximum allowed outage might triple, but that's only temporary until self-heal restores failed disks in operating data centers.
- The [database nodes](glossary.md#database-node) must be evenly distributed between all 3 data centers and include sufficient resources to handle the entire workload when running in just 2 of the 3 data centers. To achieve this, database nodes in each datacenter need at least 35% extra spare CPU and RAM resources when running normally without ongoing failures. If database nodes are typically utilized above this threshold, consider adding more of them or moving them to servers with more resources.
-## See also
+## See Also
* [Documentation for DevOps Engineers](../devops/index.md)
* [{#T}](../reference/configuration/index.md#domains-blob)
-* [Example cluster configuration files](https://github.com/ydb-platform/ydb/tree/main/ydb/deploy/yaml_config_examples/)
+* [Example Cluster Configuration Files](https://github.com/ydb-platform/ydb/tree/main/ydb/deploy/yaml_config_examples/)
* [{#T}](../contributor/distributed-storage.md)
[*recommended-node-count]: Using fewer than this number of nodes will limit the cluster's ability to [self-heal](../maintenance/manual/selfheal.md).
\ No newline at end of file